compcogneuro/book: はじめに
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/book/blob/main/chapter-01.md
ライセンス: CC BY 4.0。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
bibfile: ccnlab.bib —
はじめに
あなたは、可能な限り最も魅力的な科学の旅の 1 つ、つまり自分自身の脳内に乗り出そうとしています。この旅は、新皮質の個々の ニューロン (第 2 章) が、他のニューロンから受け取る約 10,000 個のシナプス入力信号をどのように扱うかを理解することから始まります。 新皮質は、進化的に最も新しい脳の部分であり、人間の中で最も拡大しており、ほとんどの思考が行われる場所です。新皮質のニューロンとニューロン間のシナプスの数は驚くべきもので、約 200 億個のニューロンがあり、それぞれのニューロンは約 10,000 個の他のニューロンと相互接続されています。これは地球上の人類の数倍のニューロン数です。そして、それぞれのニューロンは、私たち人間よりもはるかに社交的です。安定した人間の社会的ネットワークの推定規模は、ニューロンの 10,000 人に対して、わずか 150 ~ 200 人程度です。
内部では多くのことが起こっています。これらのスケールでは、1 つのニューロンが他のニューロンに与える影響は比較的小さいです。これらの小さな影響が、学習メカニズム (第 4 章) を通じて強力な方法で形成され、複雑で強力な形式の情報処理を実現できることがわかります。そして、この情報処理能力は、個々のニューロン自体にそれほど複雑さを必要としません。非常に単純な形式の情報統合は、実際の新皮質ニューロンの応答特性を正確に記述し、集合的なニューラル ネットワーク レベルでの高度な情報処理を可能にします (第 3 章)。
本書の第 1 部でこれらの基本的な神経情報処理メカニズムの理解を深めた後、第 2 部で、知覚と注意 (第 6 章)、学習と記憶 (第 7 章)、運動制御と強化学習 (第 8 章)、実行機能 (第 9 章)、言語 (第 10 章) など、人間の思考 (認知) のさまざまな側面を探求します。驚くべきことに、これらの一見異なる認知機能はすべて、第 1 部で開発した共通の神経機構の小さなセットを使用して理解することができます。実際、私たちの新皮質は愚かなパテの素晴らしい形態であり、学習プロセスによってさまざまな認知タスクを引き受けるように成形することができます。たとえば、さまざまな脳領域や認知機能にわたって驚くべき類似点が見つかるでしょう。一次視覚野の発達は、単語の意味についての豊かな意味知識の発達について多くのことを教えてくれます。
私たちが探求するいくつかの現象
以下は、本書の第 2 部で検討する認知神経科学現象の一部のリストです。
-
ビジョン: 私たちは、数え切れないほどの人、場所、物を簡単に認識できます。なぜロボットにとってこれはそれほど難しいのでしょうか?私たちは、自然の風景 (山、木など) を表示し、学習原理を使用してそれらをエンコードする脳のような方法を開発するネットワークでこの問題を調査します。
-
注意: ウォーリーはどこですか? 2 つの視覚処理経路がどのように連携して空間のさまざまな場所 (何かを探しているのか、単に物を取り込んでいるのか) に注意を集中させるのに役立つのか、また、これらの経路の 1 つが損傷すると人々が空間の半分を無視するようになるのはなぜかをモデルで確認します。
-
エピソード記憶: 脳の小さな部分が損傷すると、どのようにして健忘症が引き起こされるのでしょうか?海馬の構造を再現したモデルでその方法を見てみましょう。このモデルは、脳の残りの部分が新しいエピソード記憶を形成するのに適していない理由についての洞察を提供します。
-
ドーパミンと報酬: なぜ私たちは物事にすぐに飽きてしまうのでしょうか?なぜなら、私たちのドーパミンシステムは常に私たちが知っているすべてのものに適応しており、何か新しいことや違うことが起こったときにのみ報酬を与えてくれるからです。段階的なドーパミン放出を促す脳システムの相互作用を通じて、これがどのように起こるかを見ていきます。
-
タスク指向の行動: 気を散らすもの (電子メール、テキスト メッセージ、ツイートなど) が増え続ける中、どうすれば完了しなければならないタスクや注意を払う必要がある事柄に集中し続けることができるでしょうか? 私たちは、脳の「実行」部分である前頭前野をシミュレートするネットワークを通じて、この問題を探っていきます。この領域が私たちを気を散らすことから守るのにどのように適しているのか、またこれが年齢とともにどのように変化するのかを見ていきます。
-
意味: 「バラはバラ、バラはバラだ。」 しかし、そもそもバラが何であるかをどうやって知ることができるのでしょうか?私たちは、教科書のすべての段落を「読み」、どの単語が一緒に使われたり、似たような文脈で使われたりする傾向があるのかに注目することで、驚くほど優れた意味理解を獲得するネットワークを通じてこれを探求します。
-
読書: ディスレクシアの原因は何ですか?また、ディスレクシアを持つ人々によって、読むことへの苦労がこれほどまでに異なるのはなぜですか?私たちは、人間と同じように、3,000 近くの英単語の読みと発音を学習し、新しい非単語 (「mave」や「nust」など) に一般化するネットワークでこれらの問題を調査します。さまざまな方法でネットワークに損傷を与えると、さまざまな形の失読症がシミュレートされる理由を見ていきます。
計算によるアプローチ
私たちの脳の旅の重要な特徴は、認知神経科学 (つまり、計算認知神経科学) を理解するために コンピューター モデル という手段を使用することです。これらのコンピューター モデルは、重要な方法で学習体験を豊かにします。コンピューター モデルを取り出して数時間いじってみるまで、実際には何も理解できなかったという声を生徒からよく聞きます。強力な 3D グラフィカル インターフェイスを使用して脳を操作および視覚化できるため、抽象的な概念に命が吹き込まれ、快適なラップトップで多くの実験を簡単、クリーン、安全に実行できるようになります。これはビデオ ゲームのような楽しいものです。数年前に流行った「シム シティ」ゲームのような「シム ブレイン」を考えてください。
より深刻なレベルでは、脳がどのように機能するかを理解するためのコンピューター モデルの使用は、過去数十年にわたるこの分野の科学の進歩に大きく貢献してきました。コンピューター モデリングの主な利点は、単独では人間の理解が困難になることが多い複雑さに対処できることです。漠然とした言葉や単純な紙の図で話すだけで、何十億ものニューロンが他の何万ものニューロンと相互作用し、どのように人間の複雑な認知を生み出すのかをどのようにして理解できるでしょうか?確かに、正確な予測を行い、多くの複雑な要因がどのように相互作用するかを理解するために、気候モデリングにコンピューター モデルを使用する必要性に疑問を抱く人はいません。認知神経科学においては、状況はさらに悲惨です。
それにもかかわらず、コンピューター モデルが使用されるあらゆる分野で、モデルに対する根本的な不信感が存在します。それら自体は複雑であり、人間によって作成されており、問題となっている実際のシステムとは必要な関係がありません。これらのモデルが完全にでっち上げられた空想ではないことは、どうやってわかるのでしょうか?答えは簡単のようです。モデルはできるだけ多くのレベルでデータによって制約され、経験的にテストできる予測を生成する必要があります。以下では、この課題に対して人々が取る可能性のあるさまざまなアプローチについて説明します。これは、この本で説明されている研究の背後にある科学的アプローチの感覚を与えることを目的としています。学生にとって、これはおそらくあまり意味がありませんが、科学が実際にどのように機能するかについてある程度の視点を与えるのに役立つかもしれません。
理想的な世界では、ニューラル モデル内のニューロンは実際の脳内のニューロンの鏡像であり、必要な詳細を取得するための技術的な制限を考慮して、可能な限り多くの詳細を複製すると想像するかもしれません。それらは実際の脳内とまったく同じように接続されます。そして、それらは、問題の生物がさまざまな状況でどのように行動するかを正確に再現する詳細な行動を生成するでしょう。そうすれば、モデルが十分に「現実的」であり、その予測の一部を信頼できると確信できるでしょう。
しかし、たとえこれが技術的に実現可能だったとしても、その結果として得られるシステムが脳そのものよりも理解できるものになるのかどうか疑問に思うかもしれません。言い換えれば、物が実際にどのように機能するかについての実際の理解を発展させることなく、根本的な謎を脳からモデルに移すことにしか成功しなかったでしょう。この観点から見ると、最も重要なことは、可能な限り多くのデータを取得できる最も単純なモデルを開発することです。これは基本的に オッカムのカミソリ の原理であり、すべての科学理論化の中心原理として広く認識されています。
場合によっては、このカミソリを使って不要な部分を簡単に切り落とすことができます。確かに、ニューロンの多くの生物学的特性は、その中核となる情報処理機能(たとえば、ニューロンだけでなくすべての生物学的細胞に共通する細胞プロセス)には無関係です。しかし多くの場合、どの現象が重要であると考えるかについての判断が必要になります。これは、モデルで扱われる科学的問題によって異なります。
本書のモデルに採用されたアプローチは、生物学的な詳細と認知機能の間にある種の幸福な (または不幸な) 中間点を見つけることです。この中間点は、この連続体のどちらかの端に関係する研究者がモデルのレベルに不満を抱いている程度に不満です。生物学者は、私たちのニューロンとネットワークが過度に単純化されているのではないかと心配するでしょう。認知心理学者は、我々のモデルが生物学的に詳細すぎることを懸念するだろうし、同じ認知現象を捉えるもっと単純なモデルを作成できるだろう。この「黄金の中間」を楽しむ私たちは、重要な認知現象を捉えながら、神経面で重要な単純化を達成できたときに幸せを感じます。このレベルのモデリングでは、神経メカニズムの考察がどのように心の働きに情報を与えるのか、そしてその逆に、認知的および計算上の制約がどのようにしてこれらのメカニズムが解決するために進化した問題をより深く理解できるようになるのかを探ります。したがって、認知現象(記憶干渉など)が神経レベルでの変化(疾患、薬理学、遺伝学、または認知タスクパラメータの変化による同様の原因)によってどのように影響を受けるかを予測できます。その後、モデルをテスト、改ざん、改良することができます。この意味で、認知神経科学のモデルは、明示的に指定され形式化されている点を除けば、他の「理論」とまったく同じであり、データが一致しなかった場合、または一致しない場合には、モデル作成者に理論の責任を強いることになります。逆に、モデルは、既存の理論が困難なデータに直面した場合、口頭での理論化では考慮されない特定のダイナミクスにより、最終的に理論が維持される可能性があることを示す場合があります。
結局のところ、それは美学や性格に基づく要因に帰着し、それによって人によってコンピューター モデリングに対する全体的な戦略が異なります。これらのさまざまなアプローチにはそれぞれ価値があり、それらがなければ科学は進歩しません。幸いなことに、人々の性格は異なり、異なる人が異なることを行うことになります。シンプルさ、優雅さ、清潔さを最も高く評価する人もいます。このような人は、抽象的な数学的 (ベイジアンなど) 認知モデルを好む傾向があります。また、生物学的な詳細を何よりも重視し、最も確固たる確立された事実から逸脱することにあまり抵抗を感じず、既知のすべてを組み込んだ高度に精巧な個々のニューロン モデルを作成することを好む人もいます。その中間で生きるためには、ある程度のリスクを冒す覚悟が必要であり、複雑な現象がより単純な基礎メカニズムから出現することが示される「出現」のプロセスを最も高く評価する必要があります。
ここでの成功の基準は、もう少し曖昧で主観的です。基本的には、モデルが理解できるほど単純であるかどうかに要約されますが、その動作が自明になるほど単純ではないか、あるいは、そもそも何の役にも立っていないと思われるほど完全に透明であるかどうかです。この問題に関する最後の注意点は、さまざまなレベルのモデルは相互に排他的ではないということです。低レベルの生物物理学モデルと高レベルの認知モデルはそれぞれ、それぞれの領域の理解と分析に多大な貢献をしてきました (その多くは、本書でさらに簡略化または詳しく説明するための基礎となっています)。実際、モデリングの 1 つのレベルを別のレベルで理解しようとする試みによって、多くの根拠が得られます (そしてある程度はすでに得られています)。結局のところ、分子から心へのリンクは複数のレベルの分析にまたがり、素粒子物理学の法則から惑星の運動までを研究するのと同様に、複数の正式なツールが必要になります。
緊急現象
何が満足のいく科学的説明となるのでしょうか?満足のいく答えは、一見複雑な現象を、特定の方法で相互作用する、より単純な基礎となるメカニズムの観点から説明できるということです。ここでは、還元主義という古典的な科学プロセスが重要な役割を果たしており、複雑なシステムがより単純な部分に還元されます。ただし、無視されがちな反対の方向、再構築主義、つまり複雑なシステムがこれらのより単純な部分から実際に再構築される方向に進む必要もあります。多くの場合、この再構成を実際に実現する唯一の方法は、計算モデリングを使用することです。その結果、創発の本質を捉えようとする試みが生まれました。
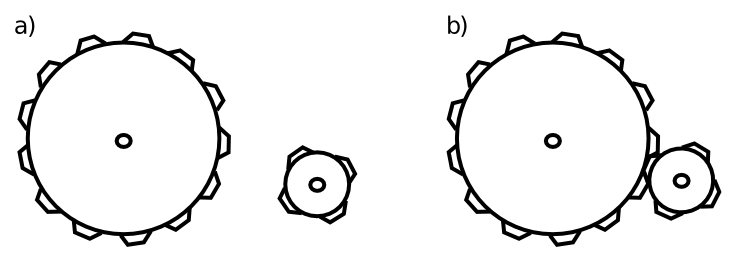
出現は、[@fig:fig-gears] に示すように、2 つの相互作用する歯車という非常に単純な物理システムで説明できます。それは神秘的でも魔法的なものでもありません。一方で、実はそうなんです。十分に硬い材料であればどのような材料でも歯車を作ることができ、それでも機能します。摩擦や耐久性などの微妙な要因が異なる場合があります。しかし、広い範囲においては、ギアの材質は関係ありません。したがって、創発とともに発生する「超越性」のレベルがあり、より複雑な相互作用システムの動作は、下位レベルの部分の詳細なプロパティの多くに依存しません。実際には、相互作用自体が重要であり、パーツは単なるプレースホルダーにすぎません。もちろん、それらはそこに存在し、いくつかの基本的な基準を満たしている必要がありますが、それでも交換可能です。
この例をここで興味のある領域に取り上げると、これは、生体ニューロンを人工ニューロンに置き換えることができ、本質的な相互作用を正しい方法で捉えている限り、すべてが同じように機能するはずだということを意味するのでしょうか? 私たちの中には、これが事実であると信じている人もいます。最終的に適切な構成で十分なニューロンを大規模なコンピューターシミュレーションに組み込むことができたとき、結果として得られる脳は、私たち自身の頭の中にあるものと同じように、意識やその他すべてのものをサポートすることになるでしょう。さらに興味深い疑問が 1 つ生じます。私たちの肉体と物理的環境の間のすべての相互作用はどれくらい重要なのでしょうか?これが重要であると考える十分な理由があります。したがって、この脳をロボットに組み込む必要があります。あるいは、おそらくもっと挑戦的なのは、仮想現実の仮想環境において、依然としてコンピューターの中に留まっているということです。シミュレートされた脳を旅しながら、この質問について深く考えるのは興味深いでしょう…
なぜ脳を気にする必要があるのでしょうか?
この旅であなたが発見することの 1 つは、計算論的認知神経科学は難しい ということです。複数のレベルで習得すべき内容がたくさんあります。行動パラダイムや反応時間パターンの詳細に加えて、ニューロンのイオンチャネル、脳のさまざまな部分の経路の名前、さまざまな脳領域への損傷の影響、および神経活動のパターンの詳細を調べます。これらの脳の詳細をすべて無視して、私たちが本当に気にかけているものだけに集中できたら、ずっと簡単になると思いませんか? — 認知自体はどのように機能するのでしょうか?たとえば、Visual Basic や Python でプログラムする場合、コンピューター ハードウェアがどのように機能するかについてほとんど知識は必要ありません。さまざまな種類のハードウェアがすべて同じプログラミング言語とソフトウェアを実行できます。心のソフトウェアだけに焦点を当てて、ハードウェアを無視することはできないでしょうか?
まさにこの議論は、長年にわたってさまざまな形で広められてきましたが、実際、最近、抽象的なベイジアン認知モデルの形で少し復活しています。 David Marr はおそらく、3 つの異なるレベル [@Marr77] で認知をある程度独立して調べることができると主張し、最も影響力がありました。
-
計算 — どのような計算が実行されていますか?どのような情報が処理されていますか?
-
アルゴリズム — 一連の情報処理ステップの観点から、これらの計算はどのように実行されますか?
-
実装 — ハードウェアはこれらのアルゴリズムを実際にどのように実装するのでしょうか?
この問題の分割方法は、コンピュータと同様、ハードウェアは実際にはそれほど重要ではないため、実装 (つまり脳) を無視しても問題なく、計算レベルとアルゴリズム レベルに集中できると主張するために使用されてきました。
ただし、このアプローチの重要な見落としは、標準的なコンピュータではハードウェアが重要ではない理由は、そもそもそれらはすべて機能的に同等になるように特別に設計されているからであるということです! 確かに、多くの異なる詳細がありますが、それらはすべて基本的なシリアル フォン ノイマン アーキテクチャを実装しているということです。脳のアーキテクチャが大きく異なり、一部のアルゴリズムや計算が非常に効率的に動作する一方、他のアルゴリズムや計算はサポートできない場合はどうなるでしょうか?そうなると、実装レベルが非常に重要になります。
これが事実であると信じる十分な理由があります。脳は汎用の計算装置とはまったく似ていません。代わりに、実際には、200 億個のニューロンにわたって大規模な並列処理で非常に特殊な計算セットを実装するカスタム ハードウェアです。この点では、現代のコンピューターの特殊なグラフィックス プロセッシング ユニット (GPU) によく似ています。GPU は、複雑な 3D グラフィックスのレンダリングに必要な特定の計算を大規模な並列処理で効率的に実行するようにカスタム設計されています。より一般的には、コンピューター サイエンスの分野では、並列計算のプログラミングが非常に難しく、効率的な並列計算を実現するにはアルゴリズムと計算を完全に再考する必要があることが判明しつつあります。したがって、脳のハードウェアは非常に重要であり、どのような種類のアルゴリズムや計算が実行されているかについて多くの重要な手がかりを提供します。
歴史的に、「脳を無視する」アプローチは興味深い軌跡をたどってきました。 1960 年代から 1990 年代初頭にかけて、脳は実際には標準的なコンピューターとほぼ同じように動作すると仮定するアプローチが主流であり、研究者は認知モデルに論理や記号命題などの概念を使用する傾向がありました。それ以来、より統計的な比喩が普及するようになり、特にベイズ確率的フレームワークが広く使用されるようになりました。これは、認知の多くの(すべてではありませんが!)側面が実際に動作する方法に特によく適合していないようだったハードシンボルやロジックとは対照的に、脳内の情報処理の段階的な性質(たとえば、さまざまな段階的な確率を統合して、何らかのイベントの可能性の全体的な推定値に到達する)を強調するため、多くの点で進歩です。
しかし、ベイズ確率計算の実際の数学は、脳が神経レベルでどのように機能するかに特によく適合しているわけではなく、この研究の多くは、脳が実際にどのように機能するかをあまり考慮せずに行われています。代わりに、マーの計算レベルのバージョンが採用されており、脳が何をしていてもそれは少なくとも最適に近いものである必要があり、ベイジアン モデルは多くの場合、不確実な情報を最適に組み合わせる方法を教えてくれます。この最適性の仮定が妥当であるかどうかに関係なく、特定の問題に対して最適な計算が何であるかを知ることは間違いなく有益であるため、このアプローチは一般に確かに多くの価値があります。ただし、最適性は通常、多くの仮定に基づいて条件付けされるため、これらの異なる仮定の中から決定することが困難なことがよくあります。
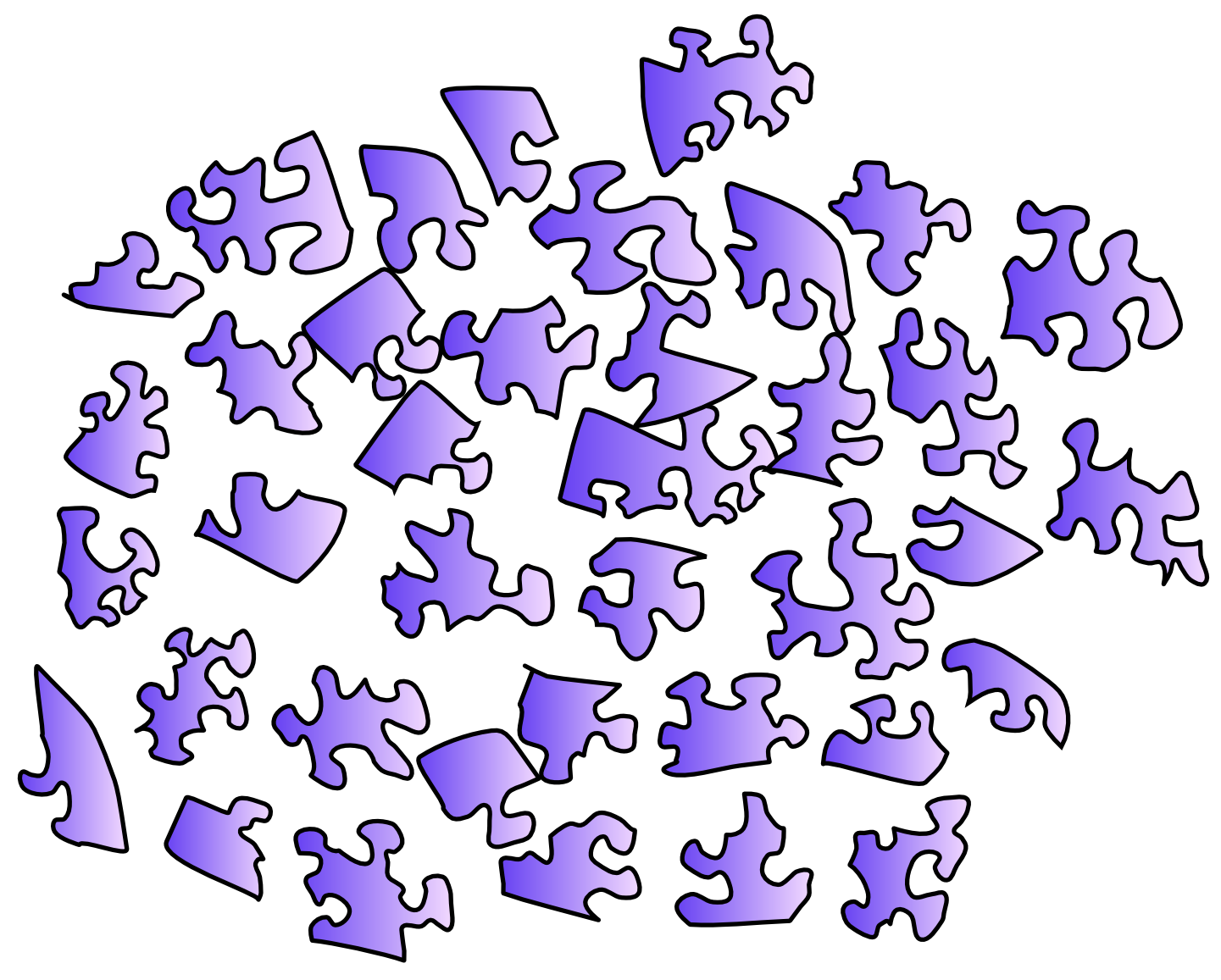
脳が実際にどのように認知を生み出しているのかを本当に知りたいのであれば、明らかに脳が実際にどのように機能しているのかを知る必要があります。はい、これは難しいです。しかし、それは不可能ではなく、最近の神経科学の状況では、脳が実際にどのように機能するかについてのあらゆる種類の洞察を提供するための有用な情報が豊富にあります。それはジグソーパズルに取り組んでいるようなものです。最も簡単なパズルは、どこにでも独特のテクスチャとがらくたでいっぱいなので、ピースがどのように組み合わされるかを実際に見ることができます ([@fig:fig-puzzle-clutter])。神経科学データの豊富なタブローは、この独特のジャンクをすべて提供して、認知を混乱させるプロセスを制限します。対照的に、抽象的で純粋に認知的なモデルは、特徴のない大きな青空 ([@fig:fig-puzzle-blue-sky]) だけを備えたジグソーパズルのようなものです。論理的な制約があるのはピースの形状だけであり、それらはすべて非常に類似しており、区別するのが困難です。永遠に時間がかかります。
すべてのピースを組み合わせてパズルを完成させる最も満足のいく例としては、次のようなものがあります。
高レベルの抑制と広範囲のびまん性結合を含む海馬の詳細な生物学は、新しいエピソード情報を迅速に学習するという海馬の独特の役割、および難治性てんかんを予防するために海馬を切除した患者HMからの注目すべきデータと適合します。第 8 章 (記憶) の計算モデルを通じて、これらの生物学的詳細が高レベルの *パターン分離 を生み出し、それによって記憶が高度に明確に保たれるため、壊滅的なレベルの干渉を引き起こすことなく迅速な学習が可能になることがわかります。
- ドーパミン、大脳基底核、および前頭前皮質の間の接続に関する詳細な生物学は、以前の報酬履歴に基づいて意思決定を行い、どの情報を保持しておくことが重要で、どの情報は無視してもよいかを学習するための計算要件と適合します。第 10 章 (実行機能) の計算モデルは、ドーパミン システムが、後の有用性をどの情報を維持するかという初期の決定に変換するために必要な一種のタイムトラベルを示すことができることを示し、第 7 章 (運動) の計算モデルは、大脳基底核回路に対するドーパミンの影響が、正と負の両方の結果に基づいた意思決定を促進するのに適切であることを示しています。そして、大脳基底核と前頭前皮質の間の相互作用により、大脳基底核の決定が前頭前皮質で維持され、それに作用するものに影響を与えることが可能になります。ここには多くの部分がありますが、それらがすべて機能モデルに非常によく適合しているという事実、およびそれらの多くの側面が直接実験のテストに耐えているという事実により、これが実際に起こっていることである可能性が非常に高くなります。
AI、ML、神経科学
この教科書の中核となる内容は 2000 [@OReillyMunakata00] 以来 20 年間存在しており、ニューラル ネットワーク モデルの全体的な人気はその間に大きく変動しました。 2020 年の第 4 版の時点では、人工知能 (AI) と機械学習 (ML) [@LeCunBengioHinton15; @Schmidhuber15a] に「ディープ」ニューラル ネットワークを使用することへの関心が再び大きく高まっています。 これらのモデルは現在、最新のスマートフォン上で実用的ではあるものの、まだ非常に限定的なアプリケーションを強化しており、幅広い ML コンテスト [@KrizhevskySutskeverHinton12] で他のテクニックを上回り、最も大切にしているゲーム [@SilverSchrittwieserSimonyanEtAl17] で人間に勝利しています。 興味深いことに、これらの新しい AI モデルを動かす中心となる原理は、学習 の章で詳しく説明する誤差逆伝播学習アルゴリズムなど、脳の機能に基づく原理の多くと一致しています。
ただし、これらの新しい AI モデルには、基礎となる生物学と「一致しない」メカニズムも多数含まれており、これらのモデルのパフォーマンスベースの目標は、脳の仕組みを理解するというより純粋に「科学的な」目標と矛盾することがよくあります。 したがって、このテキストの内容は AI / ML アプローチを補完するものです。 さらに、人間の脳が一般知能において議論の余地のないチャンピオンであることは依然として事実です。つまり、多くの異なるタスクを合理的に適切に実行し、新しいタスクを実行するための比較的最小限のレベルの明示的な指示で学習する能力です。
興味深いことに、人間の脳の中核となる特徴の 1 つは、この本で開発されたモデルには存在しますが、現在の AI モデルにはほとんど存在しませんが、ニューロン間の広範な 双方向接続 です。脳内のニューロンは 相互に * 相互作用し、高度に「社会的」な小さな細胞です。 さらに、この双方向の接続性または *再発 は 意識 [@Lamme06] と結びついており、この双方向の接続性に基づく人間の意識能力が、私たちの一般的な知能能力の重要な要素である可能性があるという興味深い可能性を示唆しています。 特に、意識は、知識が意識 [@Baars88] の「プレナリー」グローバル ワークスペース 内のドメインを越えて「浮遊」することができるため、多くの異なるルートで知識への柔軟なアクセスを可能にする可能性があり、私たちは知識を直接、意識的に操作および制御して、それを望ましい認知目標に向けることができます。
この教科書のモデルは、この種の柔軟な認知機能を理解するための基礎を提供しており、現在の研究はこれらのアイデアをさらに探求することに直接焦点を当てており、最終的には人間の心の深い秘密をさらに理解できるようになります。
この本の読み方
この本は、さまざまなレベルの背景や関心に対応することを目的としています。主要な章は比較的短く、主要テーマの概要を説明します。特定の問題のより高度な処理をサポートするために、時間の経過とともに追加される詳細なサブセクションの数が増えていく予定です。これらの複数のレベルのリーダーをサポートできることは、Wiki 形式の大きな利点です。また、関連トピックに関する他のコースの補助としてこの教材を使用することもお勧めします。シミュレーションモデルは、さまざまなコースで単独で使用できます。
この資料の複雑さと相互に関連した性質 (脳自体を反映している) のため、後の章を読んだ後に前の章に戻ると役立つ場合があります。また、第 5 章 (脳の領域) の章を 今すぐ 読んで、パート I を最後まで読み終えた後、通常の順序で再読することを強くお勧めします。これは、脳の機能的構成に関する優れた高レベルの概要を提供し、本の 2 つの部分を橋渡しし、これから取り上げる内容の全体的なロードマップを提供します。一部の内容は、第 1 部を読み終わるまではあまり意味が分かりませんが、今すぐ最初にざっと読んでおくと、多くの有益な視点が得られるでしょう。