compcogneuro/book: パート I: ニューロン
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/book/blob/main/chapter-02.md
ライセンス: CC BY 4.0。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
bibfile: ccnlab.bib —
パート I: ニューロン
脳が非常に可塑的であり、非常に多くの異なることを学習できる主な理由の 1 つは、脳が高度に彫刻可能な形式の 愚かなパテ で構成されているためです。数十億個の個々のニューロンが互いに密に相互接続されており、相互接続のパターンを変更することで動作を形作ることができます。脳は巨大なレゴ セットのようなもので、個々のピースは (単一のレゴ ピースのように) 非常に単純であり、すべてのパワーは、これらの単純なピースを組み合わせてさまざまな動作を実行できるほぼ無限の方法から得られます。
学生のあなたにとって朗報なのは、ニューロンは基本的に 単純 であるということです。多くの人はそうではないと言おうとするでしょうが、この本を読んでいくとわかるように、単純なニューロンが脳の機能について私たちが知っていることの多くを説明できるのです。したがって、ニューロンには多くの可動部分があり、ニューロンのほんの 1 つの小さな部分について学ぶのにキャリア全体を費やすことができますが、この複雑さはすべて、非常に単純な全体的な機能に役立つと強く信じています。
その機能は何ですか?基本的には検出に関するものです。ニューロンは他のニューロンから何千もの異なる入力信号を受け取り、自分にとって「意味のある」特定のパターンを探します。非常に簡単な例としては、空気をサンプリングして明らかな煙の痕跡を探す煙探知機があります。これらが指定されたしきい値制限を超えると、アラームが鳴ります。同様に、ニューロンには閾値があり、この閾値を超えるほど重大な何かを検出した場合にのみ、他のニューロンに「警報」信号を送信します。アラームは 活動電位 または スパイク と呼ばれ、ニューロン間の通信の基本単位です。
この章の目的は、ニューロンが他のニューロンから入力信号をどのように受信し、それらを統合してしきい値と比較される全体的な信号強度を作り、その結果を他のニューロンに伝達するかを理解することです。これらのプロセスがコンピューター シミュレーションでどのように数学的に特徴付けられるかを見ていきます (図 2.1 に要約)。この本の残りの部分では、ニューロンのこの単純な全体的な機能によって、最終的に私たちが世界を認識し、考え、コミュニケーションし、記憶することがどのように可能になるのかを見ていきます。
数学に関する警告: この章と学習の章 (第 4 章) は、本書全体の中で大量の数学が含まれる唯一の 2 つの章です。これらの 2 つの章は、ニューラル シミュレーションを強化する核となる方程式を開発するためです。私たちは概念的なものを数学的な内容から分離しているので、数学が嫌いな人でも詳細をすべて理解しなくても大丈夫です。したがって、ここでの計算に気後れしたり圧倒されたりしないでください。核となる概念的なアイデアに集中し、計算からできる限りのことを引き出してください (たとえそれが大したことでなくても、大丈夫です)。
検出器としてのニューロンの基本生物学
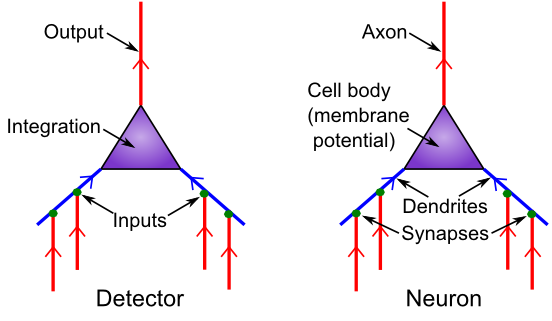
[@fig:fig-neuron-as-detect] は、神経生物学とそれらが提供する検出機能との対応を示します。 シナプスは、送信ニューロン (アラームを発して信号を送信するニューロン) と 受信ニューロン (その信号を受信するニューロン) の間の接続ポイントです。ほとんどのシナプスは、大きな枝分かれした木である 樹状突起 上にあり (「樹状突起」という言葉は、木を意味するギリシャ語の「デンドロス」に由来します)、ニューロンはそこですべての入力信号を統合します。主要な川に流入する支流と同様に、これらの信号はすべて樹状突起の幹に流れ込み、細胞体に流れ込み、そこで信号の最終的な統合が行われます。しきい値処理は、軸索と呼ばれるニューロンの出力端の最初の部分で行われます (この開始場所は 軸索丘 と呼ばれます – どうやら小さな丘か何かのように見えます)。また、軸索は広く分岐し、他のニューロンの樹状突起上にシナプスの反対側を形成し、次の伝達連鎖を完成させます。そしてさらに進みます。
基本的な検出器の機能を理解するためにニューロンの生物学について知っておく必要があることはすべて非常に単純です。検出器は入力を受け取り、それらを統合し、統合された入力が出力信号をトリガーするのに十分な強さであるかどうかを判断するだけです。 ただし、これらの入力信号の性質に関して追加の生物学的特性がいくつかあり、統合プロセスが全体的な入力信号強度の大きな変化にうまく対処できるようにするなど、神経機能に影響を与えることがわかります。
ニューロンへの入力信号の主なソースは少なくとも 3 つあります。
-
興奮性入力 — これらは、他のニューロンからの「通常の」最も一般的なタイプの入力 (全入力の約 85%) であり、受信ニューロンを興奮させる効果があります (閾値を超えて「警報」を発する可能性が高くなります)。それらは、神経伝達物質グルタミン酸によって開かれるAMPAと呼ばれるシナプスチャネルを介して伝達されます。
-
抑制性入力 — これらは入力の残りの 15% であり、興奮性入力とは逆の効果を持ちます — これらはニューロンが発火する可能性を 低くし、興奮を抑制することで統合プロセスをより堅牢にする役割を果たします。脳には、この抑制性入力を生成する 抑制性介在ニューロン と呼ばれる特殊なニューロンがあります (ネットワーク* の章 (3) でこれらについて詳しく学びます。この入力は、神経伝達物質 GABA によって駆動される GABA シナプス チャネルを介して入ります。
-
リーク入力 — これらは常に存在してアクティブであるため、厳密には入力ではありませんが、興奮を打ち消してニューロン全体のバランスを保つことにより、抑制性入力と同様の機能を果たします。生物学的には、リーク チャネルは カリウム チャネル (K) です。
抑制性と興奮性の入力は、皮質の「異なる」ニューロンから来ます。特定のニューロンは、興奮性または抑制性の出力のいずれかのみを他のニューロンに送信でき、両方には送信できません(他の脳領域のニューロンはこの制約に違反しますが、新皮質錐体ニューロンはそれに従うようです)。この制約がもたらすさまざまな影響を本文全体で見ていきます。
最後に、正味シナプス効率 または 重み の概念を導入します。これは、送信ニューロン活動信号がシナプス接続を介して受信ニューロンに与える可能性のある合計の影響を表します。 シナプスの重みは、計算認知神経科学の分野全体で最も重要な概念の 1 つです! 私たちは、これを進めながら、さまざまな方法でそれを調査していきます。生物学的には、神経伝達物質を放出する送信ニューロンの活動電位の正味の能力と、その神経伝達物質がシナプス後側のシナプスチャネルを開く能力(開くことができるそのようなチャネルの総数を含む)を表します。 興奮性入力の場合、重みは送信ニューロンによってシナプスに放出されるグルタミン酸の量と、シナプスの受信ニューロン側の AMPA チャネルの数と有効性に依存します ([@fig:fig-synapse])。
計算上、重みによってニューロンが何を検出しているかが決まります。強い重み値は、ニューロンがその特定の入力ニューロンに対して非常に敏感であることを示し、一方、低い重み値は、その入力が比較的重要ではないことを意味します。学習プロセス全体 (第 4 章) は、送信ニューロンと受信ニューロンの神経活動パターンの関数としてこれらのシナプスの重みを変更することになります。つまり、あなたが知っているすべてのもの、脳内のすべての大切な記憶は、シナプスの重みのパターンとしてエンコードされています! 第 3 章では、この検出プロセスが 分類 をサポートし、線形代数の用語で、特定の 次元、基底、または 軸 (目的にとってはすべて同義語) に沿った高次元入力空間の 射影 をサポートしていることがわかります。 したがって、この検出プロセスはまさにニューラル計算の基本エンジンであり、さまざまな方法で説明できますが、すべてここで分解する同じ本質的なプロセスに相当します。
生物学の詳細
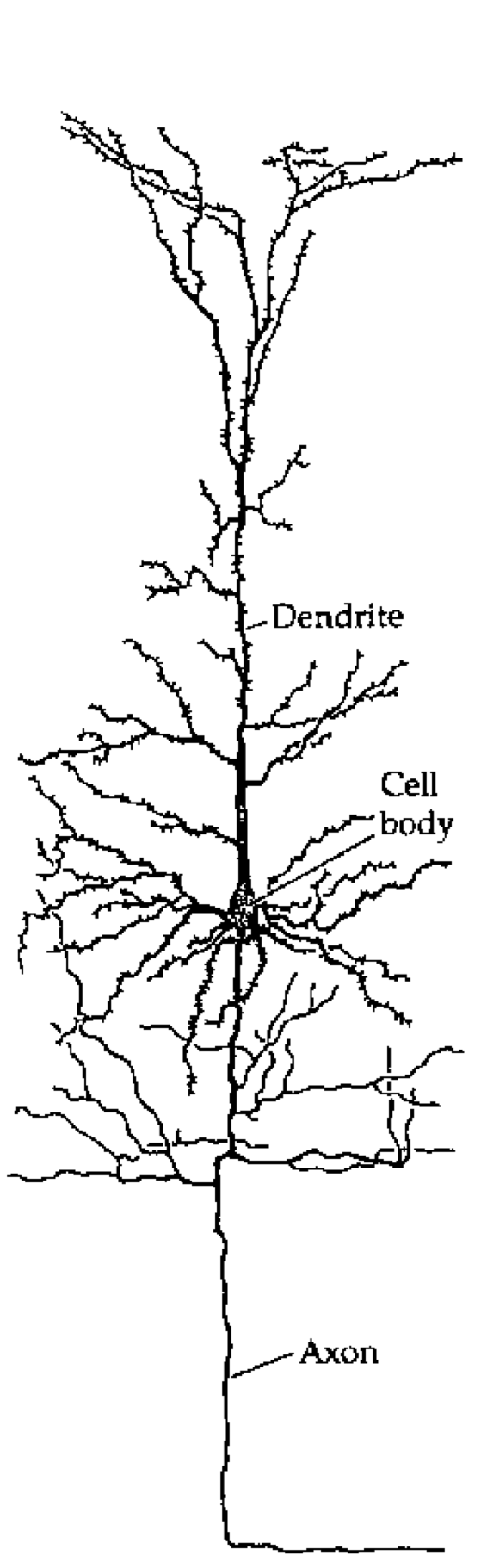
[@fig:fig-cortical-neuron] は、錐体ニューロンと呼ばれる皮質の典型的な興奮性ニューロンのトレースを示しています。これは、モデルでシミュレートする主なタイプです。 主要な章で説明した樹状突起、細胞体、および軸索の主要な要素が示されています。 樹状突起には小さな棘があることに注意してください。これらは、ニューロンを送信する際の軸索がシナプスを形成し、ニューロン間の接続を形成する場所です。
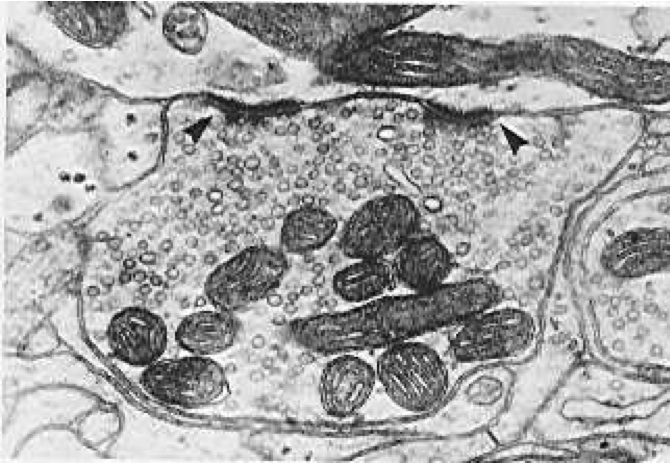
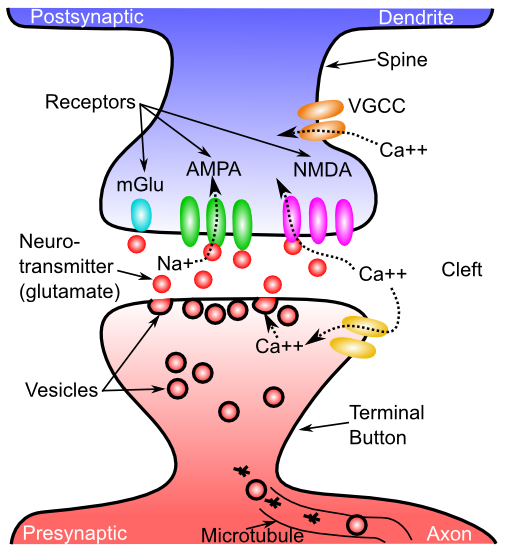
[@fig:fig-synapse-em] はシナプスの高解像度画像を示し、[@fig:fig-synapse] はシナプス信号伝達カスケードの主要な要素をすべて表示した概略図を示します。 シナプスの主な動作は、活動電位が シナプス前終末ボタンからの神経伝達物質 (NT) の放出を引き起こすことであり、この NT は次にシナプス後受容体に結合し、イオンが流れるように開き、シナプス後ニューロンに信号を伝達します。 NT グルタミン酸による興奮性AMPA受容体活性化の主なケースでは、AMPAチャネルが開いてナトリウム($Na^+$)イオンがシナプス後ニューロンに入ることができ、膜電位を上昇させてニューロンを興奮させる効果があります。 この興奮性入力は、興奮性シナプス後電位または EPSP と呼ばれます。
他の主要なタイプのシナプス後受容体は次のとおりです。
- NMDA、学習に関与し、カルシウム ($Ca^{++}$) イオンの流れを可能にします — これらの受容体については、第 4 章 (学習) で詳しく説明します。
- mGluR、学習にも関与しており、おそらく作業記憶における情報の積極的な維持にも関与しています — これらの受容体はイオンを通過させず、代わりにシナプス後細胞の複雑な化学プロセスに影響を与えます。
抑制性介在ニューロンから生じる抑制性シナプスは GABA NT を放出し、受信ニューロン上の対応する GABA 受容体が開いて塩化物 ($Cl^-$) イオンが流れるようにし、シナプス後細胞に正味の負の効果または抑制効果を生み出します (抑制性シナプス後電位または IPSP と呼ばれます)。
重要なのは、皮質のシナプスは興奮性か抑制性のいずれかであるが、両方ではないことが生物学的に示されているということです。 これは、ネットワーク 章で説明する計算モデルに影響を与えます。
統合のダイナミクス: 励起 vs. 抑制およびリーク
3 つの異なるタイプの入力信号 (励起、抑制、漏れ) を統合するプロセスは、ニューラル計算の中心にあります。このセクションでは、このプロセスの概念的かつ直観的な理解を提供し、それがニューロンの根底にある電気的特性にどのように関連するかを説明します。後で、このプロセスをコンピューター上で実際にシミュレーションできる数式に変換する方法を見ていきます。
統合プロセスは、綱引き ([@fig:fig-vm-as-tug-of-war]) の観点から理解できます。この綱引きは、ニューロンが生息する周囲の細胞外媒体と比較して、ニューロン内に存在する 電位 の空間で行われます (興味深いことに、この媒体、およびニューロンや他の細胞の内部も、基本的にはナトリウム ($Na^+$)、塩化物 ($Cl^-$)、およびその他のイオンが浮遊している塩水です。私たちは常に私たちの内部に遠い進化環境を持ち歩いています)。ニューロンの中核機能は、電圧 (電位) と電流 (イオン チャネルと呼ばれる小さな孔を通ってニューロンに出入りする荷電イオンの流れ) という電気用語で完全に理解できます。
これがどのように機能するかを確認するために、励起と抑制を考えてみましょう (現時点では、抑制とリークは事実上同じです)。重要な点は、統合プロセスは興奮と抑制の相対的な強さを反映しているということです。興奮が抑制よりも強い場合、ニューロンの電位 (電圧) はおそらく閾値を超えて出力活動電位が発火する点まで増加します。抑制がより強い場合、ニューロンの電位は低下するため、発火の閾値を超えることから遠ざかります。
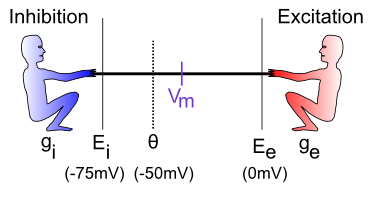
特定のケースを検討する前に、神経科学者が綱引き劇のさまざまな俳優にラベルを付けるために使用するいくつかのあいまいな用語を紹介しましょう (図の左から右へ)。
-
$g_i$ — 抑制コンダクタンス (g はコンダクタンスの記号、i は抑制を示します) — これは抑制入力の合計の強さ (つまり、抑制的な男がどれだけ強く引っ張られているか) であり、抑制電流の強さを決定する上で重要な役割を果たします。これは生物学的に、現在開いていて抑制性イオンの流れを許可している抑制性イオンチャネルの割合に対応します (GABA 抑制の場合は 塩化物 または $Cl^-$ イオン、漏れ電流の場合は カリウム または $K^+$ イオンです)。電気愛好家にとって、コンダクタンスは抵抗の逆数です。ほとんどの人は抵抗よりもコンダクタンスの方が直感的であると考えているため、ここではそれに固執します。
-
$E_i$ — 抑制性駆動電位 — 綱引きの比喩で言えば、これはニューロン内で動作する電位スケールに対して抑制性の人がたまたま立っている位置に相当します。通常、この値は約 -75mV です。ここで、mV は ミリボルト、つまり 1/1000 ボルト (1/1,000) を表します。これらは、非常に小さなニューロンにとっては非常に小さな電位です。
-
$\Theta$ — 活動電位閾値 — これは、ニューロンが他のニューロンに信号を送るために活動電位出力を発火させる電位です。通常、これは約 -50mV です。ニューロンはこの閾値を超えると「スパイクを発火する」と表現されるため、これは 発火閾値 または スパイク閾値 とも呼ばれます。
-
$V_m$ — ニューロンの 膜電位 (V = 電圧または電位、m = 膜)。これは、ニューロンの外側の細胞外空間に対するニューロンの現在の電位です。これは、ニューロンの内側と外側を隔てる細胞膜(基本的には脂肪の薄い層)であり、実際に電位が発生する場所であるため、膜電位と呼ばれます。電位または電圧は、ある場所と別の場所の電荷量の相対的な比較です。違いがあるとき、物事が起こる可能性があるため、それは「潜在的」と呼ばれます。たとえば、雲の中の電荷と地上の電荷の間に大きな電位差がある場合、雷が発生する可能性が生じます。水と同じように、責任の違いはバランスをとろうと常に「下り坂」に流れます。したがって、1 つの場所に大量の電荷 (水) がある場合、すべてが水平になるまで水が流れます。細胞膜はこの流れに対する効果的なダムの役割を果たし、細胞内の電荷を細胞の外側とは異なるものにすることができます。この文脈でのイオン チャネルは、制御された方法で物が流れることを可能にするダム壁の小さなトンネルのようなものです。そして、物事が流れると、膜電位が変化します。綱引きの比喩では、膜電位を、現時点で綱引きのバランスがどこにあるかを示すロープに取り付けられた旗として考えてください。
-
$E_e$ — 興奮性駆動電位 — これは、興奮性の人が電位空間 (通常は約 0 mV) 内に立っている場所です。
-
$g_e$ — 興奮性コンダクタンス — これは興奮性入力の合計強度であり、開いている興奮性イオン チャネルの割合を反映します (これらのチャネルは ナトリウム ($Na^+$) イオンを通過させます — 私たちの最も深い思考はすべて単なる塩水が動き回っているだけです)。
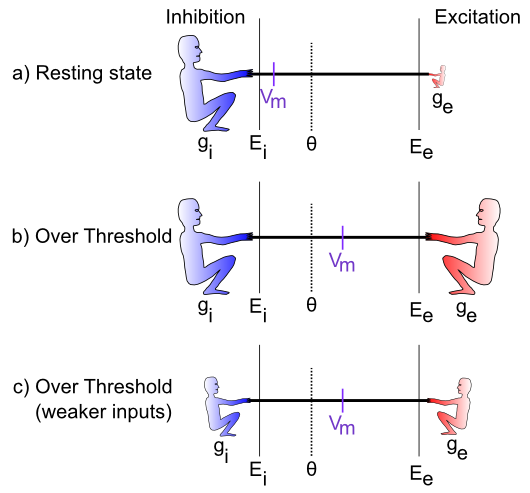
[@fig:fig-vm-as-tug-of-war-cases] は、綱引きシナリオにおける特定のケースを示しています。最初のケースでは、興奮性コンダクタンス $g_e$ は非常に低く (興奮性ガイのサイズが小さいことで示されます)、これは静止しているニューロンを表しており、他のニューロンから多くの興奮性入力信号を受信していません。この場合、抑制/漏出ははるかに強く引っ張られ、膜電位 ($Vm$) を -70mV 領域付近に維持します。これはニューロンの 静止電位 とも呼ばれます。したがって、活動電位閾値 $\Theta$ を下回っているため、ニューロン自体は信号を出力しません。みんなただくつろいでいます。
次の (b) の場合、励起は抑制と同じくらい強いので、膜電位を範囲のほぼ中央まで引き上げることができます。発射閾値は射程の下限に近いため、閾値を超えてスパイクを発射するにはこれで十分です。ニューロンはその信号を他のニューロンに伝達し、脳のネットワーク内の全体的な情報の流れに貢献します。
最後のケース (c) は、統合プロセスが基本的に 相対的であることを示しているため、特に興味深いです。重要なのは、抑制に対してどれだけ強い興奮が 相対的であるかです。両方が全体的に弱い場合でも、ニューロンは発火閾値を超える可能性があります。これが重要となる実際の例が何か思いつきますか?視覚系のニューロンについて考えてみましょう。ニューロンは、何を見ているかに応じて、そこに入ってくる光の総量が大きく変化する可能性があります(たとえば、明るい晴れた日にスノーボードをする場合と、日没後に深い森の中を歩く場合を比較してください)。視覚系に入ってくる光の総量は、視覚ニューロンが経験する興奮量に加えて、「バックグラウンド」レベルの抑制を引き起こすことが判明しました。したがって、明るいときは、暗いときと比較して、ニューロンは興奮と抑制の両方をより多く受け取ります。 これにより、全体的な入力レベルに大きな違いがあるにもかかわらず、ニューロンが物事を検出するための感度範囲内に留まることができます。
アクティベーション出力の計算
膜電位 $Vm$ は他のニューロンに直接伝達されません。代わりに、閾値が適用され、最も強いレベルの興奮のみが伝達され、その結果、脳内の情報がより効率的かつコンパクトにエンコードされます。人間の言葉で言えば、ニューロンは「TMI」(過剰な情報)の共有を避け、「グリセの格言」 に従っているかのように、関連性のある重要な情報のみを伝達します。
新皮質の実際のニューロンは、非常に短い ($< 1$ ミリ秒) 離散 スパイク または 活動電位 を計算し、神経伝達物質の放出を引き起こし、送信先のニューロンの興奮または抑制を引き起こします。スパイクの後、膜電位 $Vm$ は低い値 (静止電位またはそれ以下) にリセットされ、別のスパイクが発生する前に閾値のレベルまで再び上昇する必要があります。このプロセスは、さまざまなレベルの興奮に関連するさまざまな スパイク速度 をもたらします。この スパイク速度 情報が、行動的および認知的に関連する情報について非常に有益であることは、新皮質全体のニューロンの電気生理学的記録から明らかです。スパイクのタイミングのより正確な違いに、どの程度追加の有用な情報が含まれるかについては、依然としてかなりの議論が残っています。
私たちのコンピュータ モデルでは、非常に簡単な方法で個別のスパイク動作を直接シミュレートできます (詳細は以下を参照)。ただし、代わりに レート コード 近似を使用することがよくあります。この場合、ニューロンの活性化出力は、ニューラル スパイクの全体的なレートに対応する 0 ~ 1 の間の 実数値 になります。私たちは通常、このレート コードを、すべてが同様の情報に応答する約 100 個のニューロンからなる少数のニューロンの正味出力を反映していると考えます。新皮質は、ほぼこの数のニューロンからなる マイクロカラム で解剖学的に組織されており、実際にすべてのニューロンが同様の情報をコード化しています。このレート コード アクティベーションを使用すると、入力パターンの安定した解釈に迅速に収束する小規模なモデルが可能になり、計算時間とモデルの複雑さが全体的に節約されます。それにもかかわらず、これらの近似値の使用にはトレードオフがあり、これについてはネットワークや他の章で詳しく説明します。 Leabra フレームワークでは、レート コードを取得して離散スパイク動作の適切な近似を生成するのがやや困難でしたが、本当に満足のいくソリューションが開発されたのはつい最近のことであり、現在は 緊急の ソフトウェアの標準となっています。
数学的定式化
これで、ニューロンが興奮と抑制をどのように統合するかについて直感的に理解できました。このダイナミクスを一連の数式で捉えることができ、これを使用してコンピューター上でニューロンをシミュレートできます。最初の方程式セットは、ニューロンへの入力の効果に焦点を当てています。 2 番目のセットは、ニューロンからの出力の生成に焦点を当てます。ここではかなりの量の数学的根拠を説明します。すべての詳細に従っていない場合でも、心配する必要はありません。方程式の動作を概念的に理解している限り、実際の方程式そのものを手に取り、さまざまな入力やパラメーターで方程式がどのように動作するかを調査するときに、この理解をさらに深めることができるはずです。あらゆる計算にもかかわらず、ニューロンの動作は実際には単純であることがわかります。興奮性入力の量によって、抑制と漏れの量とのバランスをとりながら、どの程度興奮するかが決まります。そして、結果として得られる出力信号は、ほぼ予想どおりに動作します。
入力の計算
まず、綱引きの各側が引く「強さ」を形式化してから、それが結果として $Vm$ の「旗」をどのように動かすかを示します。これにより、綱引きの動的統合プロセスの明示的な方程式が提供されます。次に、この綱引き方程式のコンダクタンス係数を、ニューロンに入力される入力とシナプスの重みの関数として実際に計算する方法を示します (今のところ興奮性入力に焦点を当てています)。最後に、時間の経過とともに旗がどのように動くかを示す力学方程式を補完するために、旗が最終的にどこに着くかを示す綱引きの概要方程式を提供します。
ニューラル統合
これらの方程式の背後にある重要な考え方は、綱引きに参加する各選手が、その全体的な強さ (コンダクタンス) と、「旗」 ($Vm$) がその位置からどのくらい離れているか (駆動ポテンシャル E で示される) の両方に比例する強さで引っ張るということです。牽引車が所定の位置に固定され、$Vm$ フラグが所定の位置 (E) に到達したときに腕が完全に収縮し、ロープを再び握ることができず、この時点でそれ以上引っ張ることができないと想像してください。この考えを方程式に入れると、興奮した男が発揮する「力」または 電流 を次のように書くことができます。 \(I_e = g_e \left(E_e-V_m\right)\)
興奮性電流は $I_e$ (I は電流を表す伝統的な用語、e は励起を表す) であり、コンダクタンス $g_e$ と * 膜電位が興奮性駆動電位からどれだけ離れているか * の積です。 $V_m = E_e$ の場合、興奮した男が綱引きに「勝った」ことになり、綱引きはもう引っ張られなくなり、電流はゼロになります (コンダクタンスがどれほど大きくても、0 を掛けたものは 0 です)。興味深いことに、これは、$Vm$ 「フラグ」がそこから最も離れているとき、つまりニューロンが休止電位にあるとき、興奮性のやつが最も強く引っ張られることも意味します。したがって、十分に休息しているときにニューロンを興奮させるのが最も簡単です。
同じ基本方程式を、抑制項についても書くことができますが、リーク関数についても個別に書くことができます (これは、抑制項の基本的なクローンとして再導入できます)。 \(I_i = g_i \left(E_i-V_m\right)\) 漏れ電流: \(I_l = g_l \left(E_l-V_m\right)\) (添え字のみが異なります)。
次に、これら 3 つの異なる電流を合計して 正味電流 を取得します。これは、ニューロンの膜を横切る (イオン チャネルを通る) 荷電イオンの正味の流れを表します。 \(\begin{整列} I_{net} = & I_e + I_i + I_l = & g_e \left(E_e-V_m\right) + g_i \left(E_i-V_m\right)\\ & + g_l \left(E_l-V_m\right) \end{整列}\)
では、正味電流とは何の役に立つのでしょうか?電気は水のようなもので、それ自体を平らにするために流れることを思い出してください。水が多い場所から少ない場所へ水が流れると、最初の水は少なくなり、2 番目の水は増えます。同じことが電流でも起こります。電流の流れによってニューロン内の膜電位 (水の高さ) が変化します。 \(V_m\left(t\right) = V_m\left(t-1\right) + dt_{vm} I_{net}\)
$V_m(t)$ は $Vm$ の現在の値で、前のタイム ステップ $V_m(t-1)$ の値から更新されます。$dt_{vm}$ は膜電位の変化の速さを決定する 速度定数 です – 主にニューロンの膜の静電容量を反映します)。
上記の 2 つの方程式は、コンピューター上でニューロンをシミュレートできるようにするために必要なものの本質です。これは、膜電位が抑制性入力、漏れ入力、および興奮性入力の関数としてどのように変化するかを示します。これらの入力コンダクタンスの特定の数値と $Vm$ の開始値が与えられると、上記の方程式に従って新しい $Vm$ 値を反復 計算できます。これは、実際のニューロンが同様の入力にどのように応答するかを正確に反映します。
要約すると、すべてを実行する上記の方程式の単一バージョンを次に示します。 \(\begin{整列} V_m(t) = & V_m(t-1) + dt_{vm} \\ & \left[ g_e (E_e-V_m) + g_i (E_i-V_m) + g_l (E_l-V_m) \right] \end{整列}\)
上記のマイナス記号の問題に気付いた方、またはこれらすべてが オームの法則および拡散のプロセスにどのように関連しているか興味がある方は、章の付録のセクション ニューロンの電気生理学を参照してください。ここまでの説明に十分満足している場合は、これらの入力コンダクタンスをどのように計算するか、そしてニューロンの出力信号を駆動するために $Vm$ 値をどのように処理するかを理解することに自由に進んでください。
入力コンダクタンスの計算
興奮性入力コンダクタンスと抑制性入力コンダクタンスは、現在開いていてイオンの流れを可能にしている各タイプのイオン チャネルの総数を表します。実際のニューロンでは、これらのコンダクタンスは通常、$10^{-9}$ ジーメンスであるナノ ジーメンス (nS) で測定されます (非常に小さい数 – ニューロンは非常に小さい)。通常、神経科学者はこれらのコンダクタンスを 2 つの要素に分割します。
-
$\bar{g}$ (「g-bar」) — すべてのイオン チャネルが開いた場合に発生する最大コンダクタンスを決定する定数値。
-
$g\left(t\right)$ — 現時点で、イオン チャネルの総数の何パーセントが現在開いているかを示す動的に変化する変数 (0 から 1 の間で変化)。
したがって、対象となる総コンダクタンスは次のように記述されます: 興奮性コンダクタンス: \(\bar{g}_e g_e(t)\) そして抑制コンダクタンス: \(\bar{g}_i g_i(t)\) そして漏れコンダクタンス: \(\bar{g}_l\) (リークは定数であるため、動的に変化する値はなく、一定の G バー値のみを持つことに注意してください)。
このように項を分離すると、各タイプの開いたイオン チャネルの割合または割合を計算することだけに集中する必要があるため、コンダクタンスの計算が容易になります。これは、ニューロンへの各シナプス入力で開いているイオン チャネルの平均数を計算することで実行できます。 \(g_e(t) = \frac{1}{n} \sum_i x_i w_i\) ここで、$x_i$ は下付き文字 i でインデックス付けされた特定の送信ニューロンの 活動、$w_i$ は送信ニューロン i を受信ニューロンに接続する シナプス重み強度、n はセルへのすべてのシナプス入力にわたるそのタイプのチャネル (この場合は興奮性) の総数です。上で述べたように、シナプスの重みは、受信ニューロンがどのようなパターンに敏感であるかを決定し、学習に適応するものです。この方程式は、興奮性コンダクタンスの総量の計算に数学的にどのように入力されるかを示しています。
上の方程式は、ニューロンが受信している入力量を決定する非常に単純な関数を実行していることを示唆しています。さまざまなソースすべてからの入力をすべて加算するだけです (合計ではなく平均を計算して比率を計算します。つまり、この比率に $\bar{g}_e$ を乗算して実際のコンダクタンス値を取得します)。各入力ソースは、送信者のアクティブ度に、受信ニューロンがその情報をどの程度気にするか、つまりシナプスの重み値を乗じたものに比例して寄与します。この平均合計投入量を 正味投入量とも呼びます。
同じ式が抑制性入力コンダクタンスにも当てはまります。抑制性入力コンダクタンスは、抑制性送信ニューロンの活性化と抑制性重み値の積で計算されます。
さまざまなカテゴリの入力ソースからの入力 (つまり、さまざまなソース脳領域から特定の受信ニューロンへの投影) をどのように統合するかについては、さらに複雑な点があります。これについては、付録の章の ネット入力の詳細 で扱います。しかし、全体として、計算のこの側面は比較的単純なので、膜電位を閾値と比較して何らかの出力を生成する次のステップに進むことができます。
平衡膜電位
検出プロセスの最終ステップ (出力の生成) を完了する前に、平衡膜電位 の概念を使用する必要があります。これは、興奮性入力コンダクタンスと抑制性入力コンダクタンスの固定セットを仮定した場合、ニューロンが安定してそこに留まる $Vm$ の値です (これらが安定していない場合、$Vm$ は変化に応じて常に変化する可能性があります)。この平衡値は、ニューロン内の綱引きプロセスが実際に最終的にどのようにバランスをとるかをより明確に示すため、興味深いものです。また、これが数学的に役立つことも次のセクションで説明します。
平衡膜電位 ($V_m^{eq}$) を計算するには、重要な数学的手法を使用できます。つまり、膜電位の変化 (上記の反復 $Vm$ 更新式に従って) を 0 に設定し、この条件下で $Vm$ の値の方程式を解きます。言い換えれば、平衡状態が何であるかを知りたい場合は、$Vm$ が変化しなくなる (つまり、変化率が 0 になる) ために必要な数値を計算するだけです。これを行う数学的手順は次のとおりです。 \(\begin{整列} V_m(t) = & V_m(t-1) + dt_{vm} \\ & \left[ g_e (E_e-V_m) + g_i (E_i-V_m) + g_l (E_l-V_m) \right] \end{整列}\) (反復的な $Vm$ 更新式:)
これは変化を引き起こす部分です (平衡を求めているため時定数は省略しています)。 \(\Delta V_m = g_e \left(E_e-V_m\right) + g_i (E_i-V_m) + g_l (E_l-V_m)\) 変化が止まった時点を見つけるためにこれをゼロに設定します。 \(0 = g_e \left(E_e-V_m\right) + g_i (E_i-V_m) + g_l (E_l-V_m)\) 次に、代数を実行して $Vm$ を解決します。 \(\begin{整列} V_m = & \frac{g_e}{g_e + g_i + g_l} E_e + \\ & \frac{g_i}{g_e + g_i + g_l} E_i + \frac{g_l}{g_e + g_i + g_l} E_l \end{整列}\) 詳細な計算は、章の付録セクション 数学の導出 に示されています。
言い換えれば、これは、興奮性ドライブ $E_e$ が、すべてのコンダクタンスの合計 ($g_e + g_i + g_l$) に対する興奮性コンダクタンス $g_e$ の割合の関数として、全体の $Vm$ に寄与していることを示しています。他のそれぞれについても同様です (阻害、漏れ)。これはまさに綱引きの図から予想されることです。$g_l$ を無視すると、$Vm$ の「フラグ」は、$g_e$ と $g_i$ の間の相対的なバランスの関数として配置されます — それらが等しい場合、$g_e / (g_e + g_i)$ は .5 になります (たとえば、各 g について — 1/2 = .5)、これは、$Vm$ フラグが $E_i$ と $E_e$ の中間にあることを意味します。つまり、この計算はすべて、私たちがすでに直感的に知っていたことを再発見するためだけに行われたのです。 (実際、これが数学を行うための最良の方法です。適切な絵を描けば、すべての代数を行う前に答えがわかるはずです)。しかし、この計算が次に役立つことがわかります。
以下は、コンダクタンス項が「g-bar」定数と時間変化する「g(t)」部分に明示的に分割されたバージョンです。 \(\begin{整列} V_m = & \frac{\bar{g}_e g_e(t)}{\bar{g}_e g_e(t) + \bar{g}_i g_i(t) + \bar{g}_l} E_e + \\ & \frac{\bar{g}_i g_i(t)}{\bar{g}_e g_e(t) + \bar{g}_i g_i(t) + \bar{g}_l} E_i + \\ & \frac{\bar{g}_l}{\bar{g}_e g_e(t) + \bar{g}_i g_i(t) + \bar{g}_l} E_l \end{整列}\)
数学が本当に好きな人のために、付録では平衡膜電位方程式がベイズ最適検出器であることが示されています。
出力の生成
ニューロンの出力は、離散スパイク (ニューロンが実際に生物学的にどのように動作するか) またはレート コード近似を使用するという 2 つの異なるレベルでシミュレートできます。それぞれを順番に説明し、時間の経過とともに平均した場合に、離散スパイキング ニューロンの動作に一致するレート コードをどのように導出する必要があるかを示します (ある程度の簡略化を提供する場合でも、可能な限りより詳細な生物学的動作に一致するという意味で、近似が有効であることが重要です)。
個別スパイク
これまでに得た神経方程式から離散的な活動電位スパイクの挙動を計算するには、膜電位が発火閾値を超えたときを判断し、その後スパイクを放出し、その後膜電位をある値にリセットして、その値から上昇して再び別のスパイクを引き起こす、などを行う必要があります。これは実際には、一種の単純なコンピューター プログラムとして最もよく表現されます。
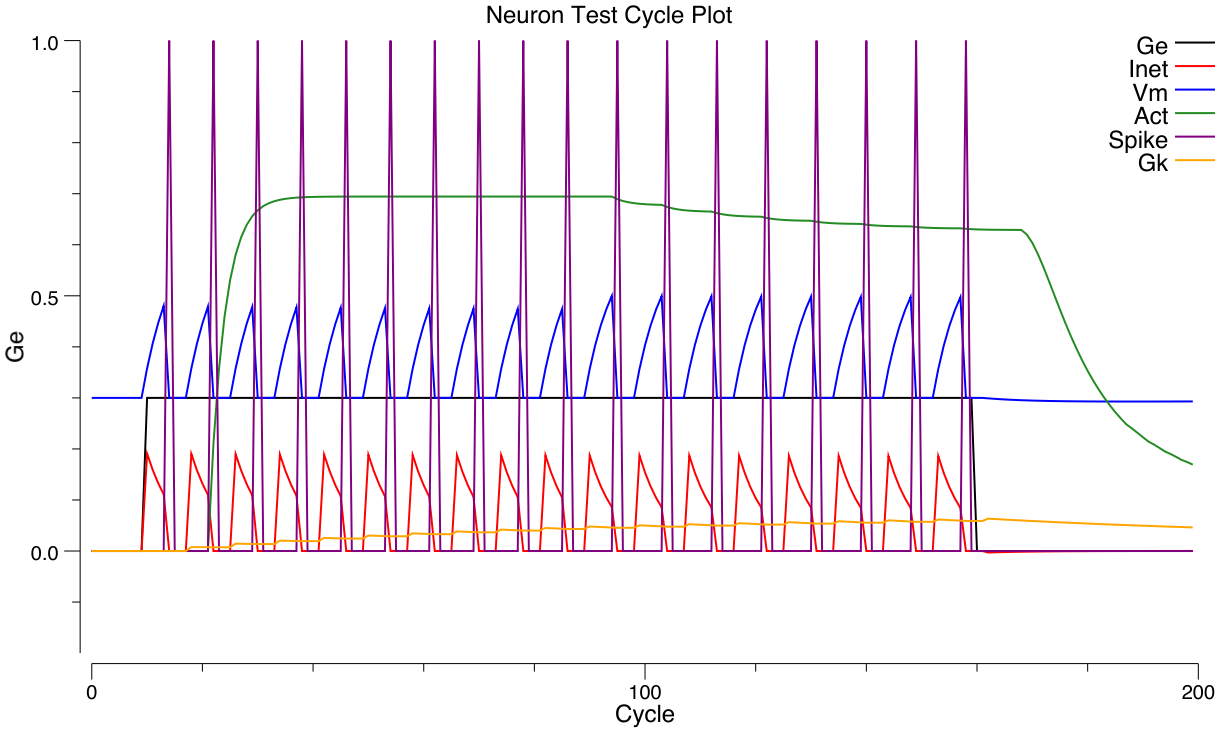
if (Vm > Theta) then: y = 1; Vm = Vm_r; else y = 0
where y is the activation output value of the neuron, and $Vm_r$ is the reset potential that the membrane potential is reset to after a spike is triggered. Biologically, there are special potassium ($K^+$) channels that bring the membrane potential back down after a spike.
This simplest of spiking models is not quite sufficient to account for the detailed spiking behavior of actual cortical neurons. However, a slightly more complex model can account for actual spiking data with great accuracy (as shown by Gerstner and colleagues [@BretteGerstner05], even winning several international competitions!). This model is known as the Adaptive Exponential or AdEx model (Scholarpedia Article on AdEx. We typically use this AdEx model when simulating discrete spiking, although the simpler model described above is also still an option. The critical feature of the AdEx model is that the effective firing threshold adapts over time, as a function of the excitation coming into the cell, and its recent firing history. The net result is a phenomenon called spike rate adaptation, where the rate of spiking tends to decrease over time for otherwise static input levels. Otherwise, however, the AdEx model is identical to the one described above.
Rate Code Approximation to Spiking
Even though actual neurons communicate via discrete spiking (action potential) events, it is often useful in our computational models to adopt a somewhat more abstract rate code approximation, where the neuron continuously outputs a single graded value (typically normalized between 0-1) that reflects the overall rate of spiking that the neuron should be exhibiting given the level of inputs it is receiving. In other words, we could count up the number of discrete spikes the neuron fires, and divide that by the amount of time we did the counting over, and this would give us an average spiking rate. Instead of having the neuron communicate this rate of spiking distributed in discrete spikes over that period of time, we can have it communicate that rate value instantly, as a graded number. Computationally, this should be more efficient, because it is compressing the amount of time required to communicate a particular spiking rate, and it also tends to reduce the overall level of noise in the network, because instead of switching between spiking and not-spiking, the neuron can continuously output a more steady rate code value.
As noted earlier, the rate code value can be thought of in biological terms as the output of a small population (e.g., 100) of neurons that are generally receiving the same inputs, and giving similar output responses — averaging the number of spikes at any given point in time over this population of neurons is roughly equivalent to averaging over time from a single spiking neuron. As such, we can consider our simulated rate code computational neurons to correspond to a small population of actual discrete spiking neurons.
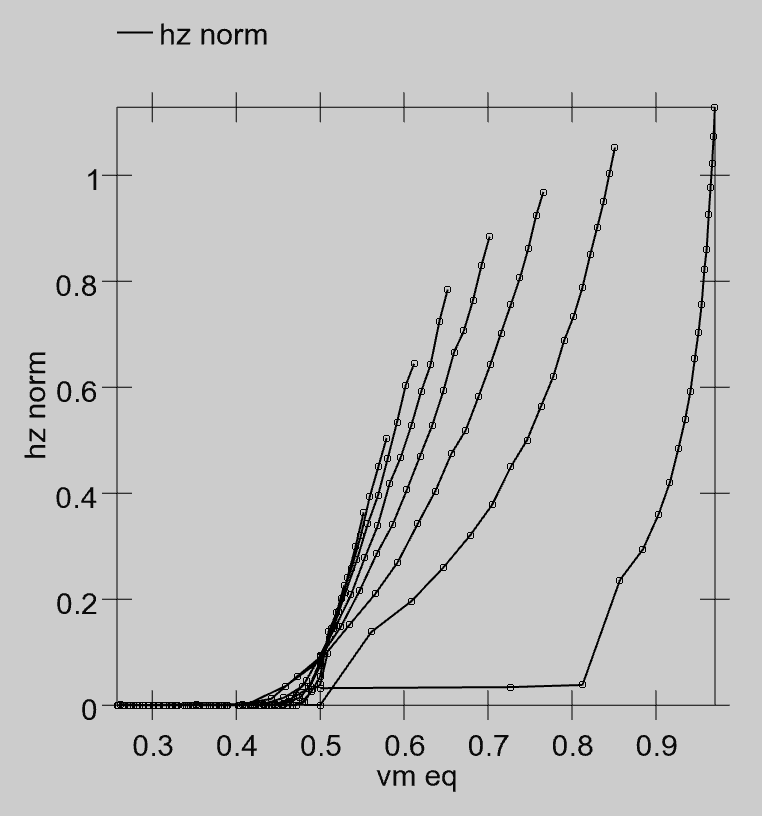
To actually compute the rate code output, we need an equation that provides a real-valued number that matches the number of spikes emitted by a spiking neuron with the same level of inputs. Interestingly, you cannot use the membrane potential $Vm$ as the input to this equation — it does not have a one-to-one relationship with spiking rate! That is, when we run our spiking model and measure the actual rate of spiking for different combinations of excitatory and inhibitory input, and then plot that against the equilibrium $Vm$ value that those input values produce (without any spiking taking place), there are multiple spiking rate values for each $Vm$ value — you cannot predict the correct firing rate value knowing only the $Vm$ ([@fig:fig-adex-vm-vs-hz]).
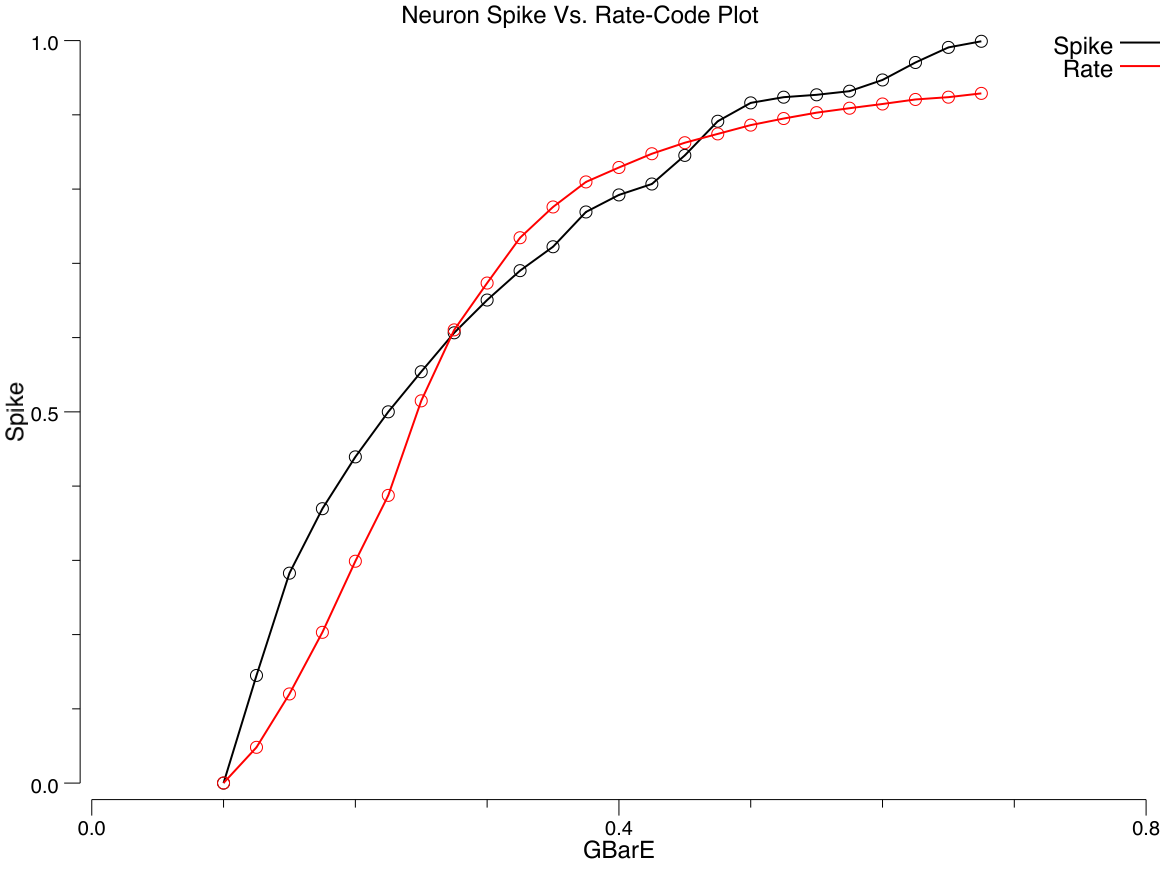
Instead, it turns out that the excitatory net input $g_e$ enables a good prediction of actual spiking rate, when it is compared to an appropriate threshold value ([@fig:fig-neuron-rate-code-approx]). For the membrane potential, we know that $Vm$ is compared to the threshold $\Theta$ to determine when output occurs. What is the appropriate threshold to use for the excitatory net input? We need to somehow convert $\Theta$ into a $g_e^{\Theta}$ value — a threshold in excitatory input terms. Here, we can leverage the equilibrium membrane potential equation, derived above. We can use this equation to solve for the level of excitatory input conductance that would put the equilibrium membrane potential right at the firing threshold $\Theta$: \(\Theta = \frac{g_e^{\Theta} E_e + g_i E_i + g_l E_l}{g_e^{\Theta} + g_i + g_l}\) solved for $g_e^{\Theta}$: \(g_e^{\Theta} = \frac{g_i (E_i - \Theta) + g_l (E_l - \Theta)}{\Theta - E_e}\) (see the Chapter Appendix on Math Derivations for the algebra to derive this solution).
Now, we can say that our rate coded output activation value will be some function of the difference between the excitatory net input $g_e$ and this threshold value: \(y = f(g_e - g_e^{\Theta})\) and all we need to do is figure out what this function f() should look like.
There are three important properties that this function should have:
-
threshold — it should be 0 (or close to it) when $g_e$ is less than its threshold value (neurons should not respond when below threshold).
-
saturation — when $g_e$ gets very strong relative to the threshold, the neuron cannot actually keep firing at increasingly high rates — there is an upper limit to how fast it can spike (typically around 100-200 Hz or spikes per second). Thus, our rate code function also needs to exhibit this leveling-off or saturation at the high end.
-
smoothness — there shouldn’t be any abrupt transitions (sharp edges) to the function, so that the neuron’s behavior is smooth and continuous.
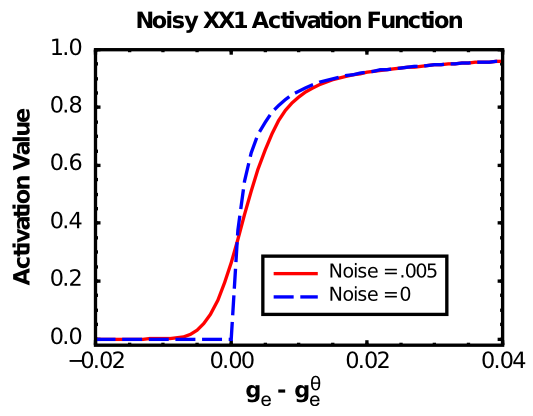
The X-over-X-plus-1 (XX1) function ([@fig:fig-nxx1-fun], Noise=0 case), also known as the Michaelis-Mentin kinetics function — wikipedia link) exhibits the first two of these properties: \(f_{xx1}(x) = \frac{x}{x+1}\)
where x is the positive portion of $g_e - g_e^{\Theta}$, with an extra gain factor $\gamma$, which just multiplies everything: \(x = \gamma [g_e - g_e^{\Theta}]_+\)
So the full equation is: \(y = \frac{\gamma [g_e - g_e^{\Theta}]_+}{\gamma [g_e - g_e^{\Theta}]_+ + 1}\)
Which can also be written as: \(y = \frac{1}{\left(1 + \frac{1}{\gamma [g_e - g_e^{\Theta}]_+} \right)}\)
As you can see in [@fig:fig-nxx1-fun] (Noise=0), the basic XX1 function is not smooth at the point of the threshold. To remedy this problem, we convolve the XX1 function with normally-distributed (gaussian) noise, which smooths it out as shown in the Noise=0.005 case in [@fig:fig-nxx1-fun]. Convolving amounts to adding to each point in the function some contribution from its nearby neighbors, weighted by the gaussian (bell-shaped) curve. It is what photo editing programs do when they do “smoothing” or “blurring” on an image. In the software, we use piecewise approximation function that is very quick to compute and closely approximates the noise-convolved version.
Biologically, this convolution process reflects the fact that neurons experience a large amount of noise (random fluctuations in the inputs and membrane potential), so that even if they are slightly below the firing threshold, a random fluctuation can sometimes push it over threshold and generate a spike. Thus, the spiking rate around the threshold is smooth, not sharp as in the plain XX1 function.
For completeness sake, and strictly for the mathematically inclined, here is the equation for the convolution operation: \(y^*(x) = \int_{z = -\infty}^{\infty} \frac{1}{\sqrt{2 \pi} \sigma} e^{-z^2/(2 \sigma^2)} y(x-z) dz\) where $y(x-z)$ is the XX1 function applied to the $x-z$ input instead of just $x$. In practice, a finite kernel of width $3 \sigma$ on either side of $x$ is used in the numerical convolution.
After convolution, the XX1 function ([@fig:fig-nxx1-fun]) approximates the average firing rate of many neuronal models with discrete spiking, including AdEx ([@fig:fig-neuron-rate-code-approx]). A mathematical explanation is in the Chapter Appendix section Frequency-Current Curve.
Restoring Iterative Dynamics in the Activation
There is just one last problem with the equations as written above. They don’t evolve over time in a graded fashion. In contrast, the $Vm$ value does evolve in a graded fashion by virtue of being iteratively computed, where it incrementally approaches the equilibrium value over a number of time steps of updating. Instead the activation produced by the above equations goes directly to its equilibrium value very quickly, because it is calculated based on excitatory conductance and does not take into account the sluggishness with which changes in conductance lead to changes in membrane potentials (due to capacitance). As discussed in the Introduction Chapter, graded processing is very important, and we can see this very directly in this case, because the above equations do not work very well in many cases because they lack this gradual evolution over time.
To introduce graded iterative dynamics into the activation function, we just use the activation value ($y^(x)$) from the above equation as a *driving force to an iterative temporally-extended update equation: \(y(t) = y(t-1) + dt_{vm} \left(y^*(x) - y(t-1) \right)\)
This causes the actual final rate code activation output at the current time t, y(t) to iteratively approach the driving value given by $y^*(x)$, with the same time constant $dt_{vm}$ that is used in updating the membrane potential. In practice this works extremely well, better than any prior activation function used with Leabra.
Summary of Neuron Equations and Normalized Parameters
| Parameter | Bio Val | Norm Val | Parameter | Bio Val | Norm Val | |
|---|---|---|---|---|---|---|
| Time | 0.001 sec | 1 ms | Voltage | 0.1 V or 100mV | 0..2 | |
| Current | $1x10^{-8}$ A | 10 nA | Conductance | $1x10^{-9}$ S | 1 nS | |
| Capacitance | $1x10^{-12}$ F | 1 pF | C (memb cap) | 281 pF | Dt = .355 | |
| GbarL (leak) | 10 nS | 0.1 | GBarI (inhib) | 100 nS | 1 | |
| GbarE (excite) | 100 nS | 1 | ErevL (leak) | -70mV | 0.3 | |
| ErevI (inhib) | -75mV | 0.25 | ErevE (excite) | 0mV | 1 | |
| $\theta$ (Thr) | -50mV | 0.5 | SpikeThr | 20mV | 1.2 |
Table: The parameters used in our simulations are normalized using the above conversion factors so that the typical values that arise in a simulation fall within the 0..1 normalized range. For example, the membrane potential is represented in the range between 0 and 2 where 0 corresponds to $-100mV$ and $2$ corresponds to $+100mV$ and $1$ is thus $0mV$ (and most membrane potential values stay within $0-1$ in this scale). The biological values given are the default values for the AdEx model.
[@tbl:table-params] shows the normalized values of the parameters used in our simulations. We use these normalized values instead of the normal biological parameters so that everything fits naturally within a 0..1 range, thereby simplifying many practical aspects of working with the simulations.
The final equations used to update the neuron, in computational order, are shown here, with all variables that change over time indicated as a function of (t):
-
Compute the excitatory input conductance (inhibition would be similar, but we’ll discuss this more in the next chapter, so we’ll omit it here): \(g_e(t) = \frac{1}{n} \sum_i x_i(t) w_i\)
-
Update the membrane potential one time step at a time, as a function of input conductances (separating conductances into dynamic and constant “g-bar” parts): \(\begin{aligned} V_m(t) = & V_m(t-1) + dt_{vm} \\ & \left[ \bar{g}_e g_e(t) (E_e-V_m) + \bar{g}_i g_i(t) (E_i-V_m) + g_l (E_l-V_m) \right] \end{aligned}\)
3a. For discrete spiking, compare membrane potential to threshold and trigger a spike and reset $Vm$ if above threshold:
if (Vm(t) > Theta) then: y(t) = 1; Vm(t) = Vm_r; else y(t) = 0`
3b.レート コードの近似では、$g_e$ および $Vm$ の NXX1 関数として出力アクティブ化を計算します。 \(y^*(x) = f_{nxx1}(g_e^*(t)) \approx \frac{1}{\left(1 + \frac{1}{\gamma [g_e - g_e^{\Theta}]_+} \right)}\) (ノイズを伴う畳み込みは示されていません) \(y(t) = y(t-1) + dt_{vm} \left(y^*(x) - y(t-1) \right)\) (膜電位変化の時定数に基づいた反復ダイナミクスの復元)
個々のニューロンの探索
実際に作業するには、CCNシムズ で利用可能な ニューロン シミュレーションを実行してください。
検出器に戻る
これで、個々のニューロンが漏出/抑制に関連して特定の興奮性信号をどのように統合するかがわかりました。これを検出プロセスのより大きな視点に置くことが重要です。このシミュレーションでは、ニューロンが一連の入力から特定の入力パターンをどのように選択できるか、またパラメーター (「緩い」または「厳密」) に応じて異なる応答パターンを持つことができることを確認します。
このシミュレーションは、CCNシムズ の 検出器 モデルで実行できます。
## 付録
この章の付録には、オプションで詳細なトピックが多数あります。
-
ニューロン電気生理学: ニューロンの電気生理学と、根底にあるイオンの濃度勾配がニューロンの電気統合特性をどのように引き起こすかについてのより詳細な説明。
-
ネット入力の詳細: 複数の異なる入力投影にわたってネット入力がどのように計算されるかについての詳細。
-
数学的導出: は、更新方程式と $g_e^{\Theta}$ に基づいて平衡 Vm 値を導出する方法を示します。
-
周波数-電流曲線: XX1 関数が離散スパイキングに近似する理由の説明を導き出します (Sergio Verduzco-Flores のご提供)。
-
適応のためのナトリウム依存性カリウムチャネル (kNa Adapt): は、スパイク中に流入するナトリウムが膜電位をどのように低下させるかを説明します。
-
ベイズ最適検出器: ニューロンへのさまざまな入力を統合するベイズ最適方法を平衡膜電位がどのように表すか。
ニューロン電気生理学
このオプションのセクションでは、ニューロンの電気生理学、つまり個々のイオンの濃度の違いがニューロンの電気的ダイナミクスにどのようにつながるかについて完全に説明します。
まず、電気の基本的な事実について説明します。 電子と陽子は(中性子とともに)一緒になって原子を構成し、電荷を持っています(電子はマイナス、陽子はプラス)。 イオンは、これらの正電荷と負電荷のバランスが崩れており、正味電荷を帯びている原子です。 脳は自身の塩水の海を持ち歩いているため、対象となる一次イオンは次のとおりです。
- ナトリウム ($Na^+$)。正味の正電荷を持ちます。
- 塩化物 ($Cl^-$)。正味の負電荷を持ちます。
- カリウム ($K^+$)。正味の正電荷を持ちます。
- カルシウム ($Ca^{++}$)。「2 つの」正味の正電荷を持ちます。
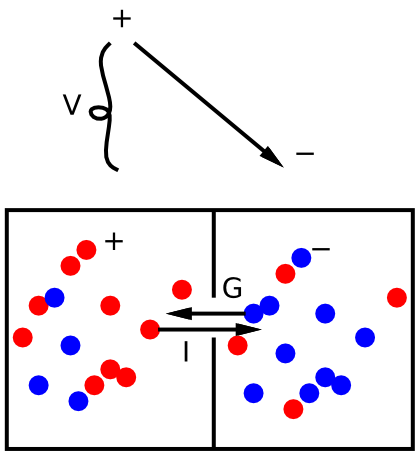
本章で述べたように、これらのイオンは、*反対の電荷は引き付けられ、同じ電荷は反発するという基本原理によって動かされる電位 (電圧) の影響下で流れる傾向があります。 負の電荷よりも正の電荷が多い領域 (電位) がある場合、近くにある負の電荷はすべてこの領域に引き込まれ (電流が生成され)、その不均衡が無効になり、すべてが中性の電位に戻ります。 [@fig:fig-electricity] は、このダイナミクスの簡単な図を示しています。 **コンダクタンスは事実上、不均衡な電荷間の開口部または経路の幅であり、電流がどれだけ早く流れるかを決定します。
オームの法則は、状況を数学的に定式化します。 \(I = G V\) (つまり、電流 = コンダクタンスと電位の積)。
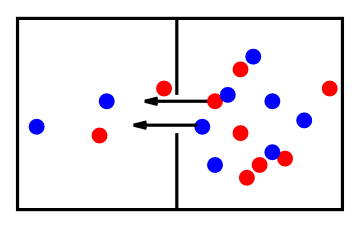
ニューロン内で作用するもう 1 つの主な力は 拡散 です。これにより、個々のイオンが空間全体に均一に分布するまで動き回ります ([@fig:fig-diffusion])。 興味深いことに、拡散力は熱によって駆動されるイオンのランダムな動きから発生します。イオンは常に空間中を飛び回り、平均速度はその環境の温度に比例します。この一定の動きは、系のエントロピーの必然的な増加の結果として拡散力を生み出します。最大のエントロピー状態は各イオンが均一に分布している状態であり、これが実質的に拡散力を表します。 拡散と電気力の主な違いは次のとおりです。
- 拡散は、他のイオンと比較した電荷に関係なく、各イオンに対して個別に作用します。— 各イオンは拡散力によって駆動され、周囲に均一に広がります。 対照的に、電気力はイオンの正体を無視し、正味の電荷のみを考慮します。 電気の観点から見ると、$Na^+$ と $K^+$ は事実上同等です。
拡散力と電気力との間のこの重要な違いにより、異なるイオンが異なる駆動電位を持ち、したがってニューロンに異なる影響を及ぼします。
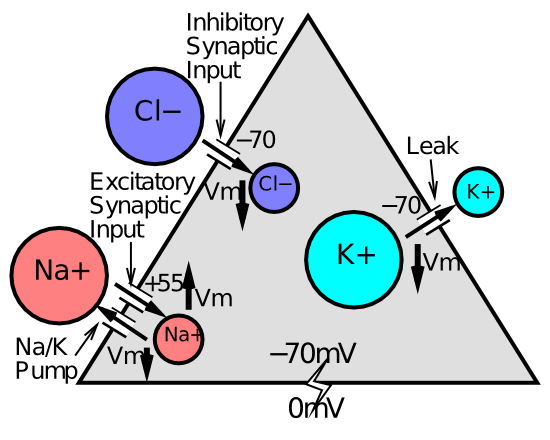
[@fig:fig-ions] は、主要なイオン タイプのニューロンの内部と外部の状況を示します。 濃度の不均衡はすべて、$Na^+$ イオンを細胞の外に送り出す定常的な ナトリウム ポンプ ** に起因します。 これにより、電荷の不均衡が生じ、ニューロンの内側はより負($Na^+$ イオンがすべて欠けている)になり、外側はより正(これらの $Na^+$ イオンが過剰になる)になります。 約 -70mV のこの負の正味電荷 (負の静止電位**) は、負の $Cl^-$ イオンを細胞の外側にも押し出します (同様に、イオンは細胞の外側の正電荷に引き寄せられます)。これにより、塩化物にも濃度の不均衡が生じます。 同様に、$K^+$ イオンは、内部の余分な負電荷によって細胞の「中に」引き込まれ、カリウム イオンに対して反対の濃度の不均衡が生じます。
これらの濃度の不均衡はすべて強い拡散力を生み出し、これらのイオンはより均一に分散しようとします。 しかし、この拡散力は電気力によって打ち消され、ニューロンが静止しているときは、電気力と拡散力が正確にバランスして互いに打ち消し合う平衡状態に達します。 イオンのダイビングポテンシャル (つまり、イオンが細胞の膜電位をどの方向に引っ張るか) の別名は 平衡ポテンシャル です。つまり、拡散と電気力が正確に釣り合う電位です。
[@fig:fig-ions] に示すように、$Cl^-$ イオンと $K^+$ イオンの駆動電位は、基本的に静止電位 -70mV と同等です。 これは、細胞の膜電位がこの -70mV にあるとき、これらのイオンの膜を横切る正味の電流は存在しないことを意味します。基本的にすべてがそのままになります。
数学的には、綱引きのアナロジーから導き出したのと同じ方程式を使用して、この現象を捉えることができます。 \(I = G (E-V)\) これはオームの法則の単純な修正であることに注意してください。E 値 (駆動電位) は、濃度の不均衡とそれが引き起こす拡散力を考慮に入れるためにオームの法則を「修正」します。 濃度の不均衡がない場合、E = 0 となり、オームの法則が得られます (後で扱うマイナス記号のモジュロ)。
-70mV の E 値をこの式に代入すると、V = -70mV のときに電流が 0 になることがわかります。 これが平衡状態の定義です。 正味電流はありません。
ここで、$Na^+$ イオンについて考えてみましょう。 ニューロン内の負の電位と濃度の不均衡の両方が、このイオンを細胞内に移動させようとします。 したがって、-70mV の静止電位では、このイオンがセルに流入できる場合、このイオンの電流は非常に大きくなります。 実際、膜電位が $+55mV$ 程度に達するまで、細胞内への侵入は止まりません。 $Na^+$ のこの平衡または駆動電位は正です。これは、$Na^+$ イオンをそれらの濃度差に抗して押し戻すにはかなりの正の電位が必要となるためです。
これらすべての結論は、$Na^+$ イオンの流れを可能にするシナプス チャネルによって $Na^+$ がニューロンに「流入」し、それによって受信ニューロンが興奮するということです。 実際、ナトリウムポンプはこれらの濃度の不均衡を作り出すことによってニューロンを「巻き上げ」、その結果、負の静止電位のデフォルトの背景に対して興奮が細胞に入る可能性が生じます。
最後に、興奮性入力によって膜電位が上昇すると、より多くの $Cl^-$ イオンが細胞内に引き戻され、-70mV の静止値に抑制性のプルバックが生じます。また、同様に $K^+$ イオンが細胞の外に押し出され、細胞内がさらに負になり、正味の抑制効果が生じます。 $Cl^-$ イオンは抑制性 GABA チャネルが開いているときにのみ流れ、$K^+$ イオンは常に開いているリーク チャネルを通って流れます。
正味入力の詳細
ここでは、特定のニューロンへのさまざまな入力ソース間の差異を考慮して、ニューロンへの興奮性コンダクタンス $Ge$ または 正味入力 がどのように計算されるかを詳細に説明します。 メインの章では、コアの計算が、重みと送信アクティベーションの平均として要約されています。 \(g_e(t) = \frac{1}{n} \sum_i x_i w_i\) ここで、n はチャネルの総数、$x_i$ は下付き文字 i でインデックス付けされた特定の送信ニューロンの アクティビティ、$w_i$ は送信ニューロン i を受信ニューロンに接続する シナプス重み強度 です。
ここで説明するより精巧なネット入力計算 (緊急 ソフトウェアで実際に使用されているもの) の全体的な目標は、アクティビティの全体的なレベルが異なるさまざまな層からの入力が、ネット入力の全体的な大きさという点で受信ニューロンに同様の影響を与えることを保証すると同時に、機能的に動作し続ける方法でこれらのさまざまな入力の強度を操作できるようにすることです。 たとえば、「ローカリスト」入力層は 100 のうち 1 つのユニット (1%) だけをアクティブにすることができますが、隠れ層は 25% のアクティビティ (たとえば、100 のうち 25) を持つことができます。全体的なアクティビティ レベルのこの大きな違いにより、別の方法で補償しない場合、これらの層は受信層に対して非常に異なる影響を与えることになります。 用語的には、特定の送信層からの接続のセットを プロジェクション と呼びます。
ネット入力の完全な方程式は次のとおりです。これには、最初に文字 k でインデックス付けされたさまざまな投影にわたる二重和が含まれ、次に文字 i でインデックス付けされた各投影の受信接続による二重和が含まれます (これらは外側の投影ループに応じて変化すると理解されています)。 \(g_e(t) = \sum_k \left[ s_k \left(\frac{r_k}{\sum_p r_p}\right) \frac{1}{\alpha_k} \frac{1}{n_k} \sum_i \left( x_i w_i \right) \right]\) この方程式の係数は次のとおりです。
-
$s_k$ = 投影の絶対スケーリング パラメーター (ユーザーの裁量で設定)。緊急 の LeabraConSpec の
WtScale.Absパラメーターで表されます。 -
$r_k$ = 投影の相対スケーリング パラメータ。他のすべての投影の相対パラメータの合計によって常に正規化されます。これが相対的なものになります — 合計は一定で、相対的な寄与のみを変更できます — 緊急 では
WtScale.Relで表されます。 -
$\alpha_k$ = 送信層の実効予測アクティビティ レベル。以下で説明するように計算されます。これは、予測アクティビティ レベルの違いに関係なく予測を均等化するのに役立ちます。
-
$n_k$ = この投影内の接続数
効果的な予想されるアクティビティ レベル $\alpha_k$ を計算するための方程式は、特定の投影で予想されるアクティブな入力数の整数カウントに基づいています。これには、送信層の予想されるアクティブ化と、受信される接続の数の両方が考慮されます。 たとえば、アクティビティが 1% (100 ユニット中 1 ユニットがアクティブ) で、その層からの受信接続が 1 つだけある層からの投影を考えてみましょう。 この 1 つの着信接続がアクティブな送信ユニットを持つ確率は平均 1% ですが、層内の いくつかの 受信ユニットがその 1 つの送信ユニットをアクティブにする可能性が高くなります。 したがって、平均予想送信確率 (1%) ではなく、レイヤー上の「最高予想アクティビティ レベル」(1) を使用します。
具体的には、難読な数学記号の代わりに長い名前を持つ疑似プログラミング変数を使用した方程式は次のとおりです。
-
alpha_k = MIN(%_activity * n_recv_cons + sem_extra, r_max_act_n)%_activity= % expected activity on sending layern_recv_cons= number of receiving connections in projectionsem_extra= standard error of the mean (SEM) extra buffer, set to 2 by default — this makes it the highest expected activity level by including effectively 4 SEM’s above the mean, where the real SEM depends on%_activityand is a maximum of .5 when%_activity= .5.r_max_act_n = MIN(n_recv_cons, %_activity * n_units_in_layer)= hard upper limit maximum on number of active inputs — can’t be any more than either the number of connections we receive, or the total number of active units in the layer
パラメーターの詳細、さまざまな予測からの実際の相対純入力寄与の監視などについては、エマー/リーブラ README ドキュメントを参照してください。
数学の導出
これは、更新方程式から平衡膜電位を導出するすべての代数を示しています。PDF バージョンでのみ表示されます。
反復 Vm 更新式: \(V_m(t) = V_m(t-1) + dt_{vm} \left[ g_e (E_e-V_m) + g_i (E_i-V_m) + g_l (E_l-V_m) \right]\) 変更部分だけ: \(\Delta Vm = g_e \left(E_e-V_m\right) + g_i (E_i-V_m) + g_l (E_l-V_m)\) それをゼロに設定します。 \(0 = g_e \left(E_e-V_m\right) + g_i (E_i-V_m) + g_l (E_l-V_m)\) Vm を解く: (すべての g を乗算します) \(0 = g_e E_e - g_e V_m + g_i E_i - g_i V_m + g_l E_l - g_l V_m\) Vm を解く: (反対側の Vm 項を収集) \(g_e V_m + g_i V_m + g_l V_m = g_e E_e + g_i E_i + g_l E_l\) Vm を解きます: (Vm ガイを 1 つだけ取得し、各辺を g で割って取得します。) \(V_m (g_e + g_i + g_l ) = g_e E_e + g_i E_i + g_l E_l\) 解決策! \(V_m = \frac{g_e E_e + g_i E_i + g_l E_l}{g_e + g_i + g_l}\)
このソリューションを別の方法で記述すると、その意味がもう少し明確になります。 \(V_m = \frac{g_e}{g_e + g_i + g_l} E_e + \frac{g_i}{g_e + g_i + g_l} E_i + \frac{g_l}{g_e + g_i + g_l} E_l\)
適応指数関数には、膜更新方程式に入る適応係数 $\omega$ (ギリシャ語オメガ) があり、これを平衡計算に含めることができます。
反復 Vm 更新式: \(V_m(t) = V_m(t-1) + dt_{vm} \left[ g_e (E_e-V_m) + g_i (E_i-V_m) + g_l (E_l-V_m) - \omega \right]\) 変更部分だけ: \(\Delta Vm = g_e \left(E_e-V_m\right) + g_i (E_i-V_m) + g_l (E_l-V_m) - \omega\) それをゼロに設定します。 \(0 = g_e \left(E_e-V_m\right) + g_i (E_i-V_m) + g_l (E_l-V_m) - \omega\) Vm を解く: (すべての g を乗算します) \(0 = g_e E_e - g_e V_m + g_i E_i - g_i V_m + g_l E_l - g_l V_m - \omega\) Vm を解く: (反対側の Vm 項を収集) \(g_e V_m + g_i V_m + g_l V_m = g_e E_e + g_i E_i + g_l E_l - \omega\) Vm を解きます: (Vm ガイを 1 つだけ取得し、各辺を g で割って取得します。) \(V_m (g_e + g_i + g_l ) = g_e E_e + g_i E_i + g_l E_l - \omega\) 解決策: \(V_m = \frac{g_e E_e + g_i E_i + g_l E_l - \omega}{g_e + g_i + g_l}\)
$g_e^{\Theta}$ の方程式の導出は次のとおりです。
閾値における平衡 Vm: \(\Theta = \frac{g_e^{\Theta} E_e + g_i E_i + g_l E_l}{g_e^{\Theta} + g_i + g_l}\) g_e を解く: \(\Theta (g_e^{\Theta} + g_i + g_l) = g_e^{\Theta} E_e + g_i E_i + g_l E_l\) (両辺に g を掛けます)、g_e を求めます。 \(\Theta g_e^{\Theta} = g_e^{\Theta} E_e + g_i E_i + g_l E_l - \Theta g_i - \Theta g_l\) (非 g_e を反対側に戻して)、g_e を解きます。 \(g_e^{\Theta} \Theta - g_e^{\Theta} E_e = g_i (E_i - \Theta) + g_l (E_l - \Theta)\) (他の g_e を持ってきて反対側を統合し、次に両側を分割して g_e を分離して取得します)、解決策: \(g_e^{\Theta} = \frac{g_i (E_i - \Theta) + g_l (E_l - \Theta)}{\Theta - E_e}\)
AdEx 関数には、膜更新方程式に入る適応係数 $\omega$ (ギリシャ語のオメガ) があり、上記のように平衡計算に含めることができます。
閾値における平衡 Vm: \(\Theta = \frac{g_e^{\Theta} E_e + g_i E_i + g_l E_l - \omega}{g_e^{\Theta} + g_i + g_l}\) g_e を解く: \(\Theta (g_e^{\Theta} + g_i + g_l) = g_e^{\Theta} E_e + g_i E_i + g_l E_l - \omega\) (両辺に g を掛けます)、g_e を求めます。 \(\Theta g_e^{\Theta} = g_e^{\Theta} E_e + g_i E_i + g_l E_l - \Theta g_i - \Theta g_l - \omega\) (非 g_e を反対側に戻す)、次に g_e を解きます。 \(g_e^{\Theta} \Theta - g_e^{\Theta} E_e = g_i (E_i - \Theta) + g_l (E_l - \Theta) - \omega\) (他の g_e を持ってきて反対側を統合し、両側を分割して g_e を分離して取得します)、 解決策: \(g_e^{\Theta} = \frac{g_i (E_i - \Theta) + g_l (E_l - \Theta) - \omega}{\Theta - E_e}\)
周波数電流曲線
これはセルジオ・ヴェルドゥスコ=フローレスによって書かれています。
XX1 関数の平滑化バージョンは、1 つの一定の興奮性刺激とある程度のノイズが与えられた場合の離散スパイク ニューロンの集団の平均発火率を表すシグモイド形状を持っています。ある程度までは、一定の入力を受け取る単一のスパイク ニューロンの平均発火率を表すこともできます。簡単にするために、平滑化 XX1 関数が単一ニューロンの発火率を近似できる理由についてのみ説明します。
一定の入力から得られる発火率は、数値シミュレーションを使用し、場合によっては数学を使用して (以下に示すように)、あらゆるスパイク ニューロン モデルで取得できるものです。この周波数応答は実際のニューロンでも測定でき、ニューロンの動作を特徴付けるのに役立ちます。生理学者は、非常に鋭利なガラス製ピペットを使用してニューロンに電流を注入し、その結果生じるスパイクの周波数を測定します。各定電流入力を対応する定常状態の周波数にマップする関数は、周波数-電流曲線 (または f-I 曲線) と呼ばれます。
大きなクラスのニューロン モデル (および実際のニューロン) の f-I 曲線の特性の 1 つは、平滑化された XX1 関数の形状に似た形状を持つことです。これは、平滑化 XX1 関数を使用して、このクラスのニューロンの発火率を近似できることを意味します。以下の説明は、f-I カーブの形状がどこから来たのかを示すことを目的としています。 XX1 モデルへの入力はコンダクタンスであるため、興奮性コンダクタンス $g_e$ を応答周波数 $f$ にマッピングする関数 $f(g_e)$ の形状を実際に解析します。現在の入力の場合も定性的には同様です。
膜電圧が閾値に達するたびにスパイクを放出する、前に説明した単純化されたスパイク モデルを考えてみましょう。これは、「統合して発射」モデルとして知られています。私たちの場合、膜電位は次の微分方程式に従います。 \(C_m \frac{d V_m}{dt} = g_e (E_e-V_m) + g_i (E_i-V_m) + g_l (E_l-V_m)\) ここで、$C_m$ は膜容量です。
ニューロンへの興奮性入力はコンダクタンス $g_e$ を増加させ、膜電位を増加させる電流 $I = g_e(E_e - Vm)$ をもたらし、$V_m > \Theta$ のときにスパイクを引き起こします。 $g_e > g_e^\Theta$ のような定数入力の場合、ニューロンは周波数 $f$ で周期的に発火します。ここで $f(g_e)$ を取得します。
Vm 方程式を書き換えます。 \(C_m \frac{d V_m}{dt} = -(g_e+g_i+g_l)V_m +(g_e E_e + g_i E_i + g_l E_l).\) \(\frac{d V_m}{dt} = -AV_m + B\) どこで \(A=(g_e+g_i+g_l)/C_m, B=(g_e E_e + g_i E_i + g_l E_l)/C_m.\)
これは 1 次の線形微分方程式であり、さまざまな方法を使用して解くことができます。すべてのコンダクタンスが一定であると仮定し、変数の分離を使用して微分方程式を解きます。追加の仮定は、$V_m(0)=V_r$ で $V_r$ がリセット電位であるということです。
微分方程式を解きます。 \(\frac{d V_m}{B-AV_m} = dt,\) \(\int_0^t \frac{d V_m}{B-AV_m} = \int_0^t dt .\)
左側の積分は、置換 $Y = AV_m + B$ を使用して解くことができます。 \(\int_0^t \frac{d V_m}{B-AV_m} = -\frac{1}{A} \int_{B-AV_r}^{B-AV_m(t)} \frac{dY}{Y}\) \(= ln \left(\frac{B-AV_m(t)}{B-AV_r} \right) = t .\)
$V_m(t)$ に関して最後の方程式を解くと、次の結果が得られます。 \(V_m(t) = \left(V_r - \frac{B}{A} \right)e^{-At} + \frac{B}{A} .\)
$t \rightarrow \infty$、$V_m(t) \rightarrow B/A$ であることに注意してください。したがって、スパイクの条件は $B/A > \Theta$ となります。これは $g_e > g_e^\Theta$ とまったく同じであり、次のステップで仮定します。
しきい値に到達する時間を求めます。 $T$ を、リセット電圧からスパイクしきい値に達するまでに必要な時間とします。微分方程式の解から次のことが得られます。 \(\Theta = \left(V_r - \frac{B}{A} \right)e^{-AT} + \frac{B}{A} .\) $T$ を解くと次のようになります。 \(T = (1/A) ln \left(\frac{Vr - (B/A)}{\Theta - (B/A)} \right) .\) \(f = \frac{1}{T} = \frac{A}{ln \left(\frac{Vr - (B/A)}{\Theta - (B/A)} \right)}.\)
得られた関数 $f$ が漸近線形であることが簡単にわかります。次の用語に注目してください。 \(B/A = \frac{(g_e E_e + g_i E_i + g_l E_l)}{(g_e + g_i + g_l)}\) $g_e$ が増加するにつれて、定数 $E_e$ に近づく傾向があります。したがって、$f$ 関数の分母全体は、$g_e$ が大きくなるにつれてほぼ定数になり、$f$ は直線になります。
積分および発射ニューロンの発火率は、興奮性コンダクタンスの値が大きくなるほど線形になります。これは実際のニューロンとは異なります。$g_e$ の値が大きい場合、モデル ニューロンは速度に制限がなく、常により大きな発火率で応答するためです。一方、実際のニューロンは、最大周波数よりも常に小さい周波数で応答するように制限されています。発射速度の飽和を引き起こす主な要因は 3 つあります。
-
ニューロンの不応期。スパイク直後の短い期間であり、その間ニューロンは反応しなくなります。
-
ニューロンが閾値電圧に達した後、スパイクを生成してリセット値に戻るまでに必要な時間。
※細胞内の電気イオンのバランス。
ニューロンがスパイク後 $T_r$ ミリ秒間リセット電圧 $V_r$ に留まるように要求することで、積分と発射のモデルに不応期を簡単に追加できます。この新しいモデルの期間 $T^*$ は、単純に古い統合発射モデルの期間に $T_r$ 項を加えたものになります。 \(T^* = T + T_r,\) \(f^* = \frac{1}{T + T_r}.\)
これにより、発火速度の直線応答が曲がり、不応期の導入により平坦になります。明らかに、周波数は $f_{max}^* = 1/T_r$ より大きくなりません。スパイクしてリセット値に戻るまでの時間を導入することによる定性的効果も同様です。
AdEx モデルには不応期が明示的に導入されていませんが、f-I 曲線を平坦化し、恣意的に高い発火率を回避する 2 つの機能があります。最初の特徴は、活動電位の上昇を生成する電圧方程式内の項で、スパイクが瞬時に発生しないようにします。 2 番目の特徴は、スパイク周波数適応を導入する項です。実際のニューロンが定電流注入で刺激されると、多くの場合、すぐに発火し始め、その後徐々に発火速度が低下します。この現象は 周波数適応として知られています。
AdEx モデルの場合、上記のように解析的に $f(g_e)$ を求めることはできませんが、シミュレーションを使用して数値的に近似することは可能です。これらのシミュレーションは、特定のパラメーター領域の周波数応答が、滑らかな XX1 関数 ([@fig:fig-neuron-rate-code-approx] を参照) で近似できる周波数応答と同様であることを示しています。
適応のためのナトリウム依存性カリウムチャネル (kNa Adapt)
私たちのモデルにおける神経発火の長期的な適応 (調節/疲労) ダイナミクスは、ナトリウム (Na) ゲートのカリウム (K) 電流に基づいています。 ニューロンがスパイクして Na の流入を促進すると、K チャネルが活性化され、リークチャネルと同様に膜電位を静止方向 (またはそれ以下) に引き下げます。 複数の異なる時定数が特定されており、この実装では、M タイプ (高速)、Slick (中)、および Slack (低速) [@Kaczmarek13; @Kohn07; @Sanchez-VivesNowakMcCormick00a; @BendaMalerLongtin10] の 3 つがサポートされています。
スパイクの場合のロジックは最も単純で、条件付きプログラム コードで表現できます。 「」 スパイクの場合{ gKNa += 上昇 * (最大 - gKNa) } それ以外の場合は { gKNa -= 1/タウ * gKNa } 「」
KNa コンダクタンス (数学用語では $g_{kna}$、プログラムでは gKNa) は、ニューロンがスパイクすると、速度定数 Rise を持つ Max 値まで上昇します。それ以外の場合は、別の時定数 Tau でゼロに減衰します。
同等のレート コード方程式は、レート コード化された活性化変数を上昇項の乗数として置き換えるだけです。
gKNa += act * Rise * (Max - gKNa) - (1/Tau * gKNa)
The default parameters, which were fit to various empirical firing patterns and also have proven useful in simulations, are:
| Channel Type | Tau (ms) | Rise | Max |
|---|---|---|---|
| Fast (M-type) | 50 | 0.05 | 0.1 |
| Medium (Slick) | 200 | 0.02 | 0.1 |
| Slow (Slack) | 1000 | 0.001 | 1.0 |
Bayesian Optimal Detector
This optional section shows how the equilibrium membrane potential equation, derived based on the biology of the neuron, can also be understood in terms of Bayesian hypothesis testing [@HintonSejnowski83; @McClelland98]. In this framework, one is comparing different hypotheses in the face of relevant data, which is analogous to how the detector is testing whether the signal it is looking for is present ($h$), or not ($\bar{h}$). The probability of $h$ given the current input data $d$ (which is written as $P(h|d)$) is a simple ratio function of two other functions of the relationship between the hypotheses and the data (written here as $f(h,d)$ and $f(\bar{h},d)$): \(P(h|d) = \frac{f(h,d)}{f(h,d) + f(\bar{h},d)}\) Thus, the resulting probability is just a function of how strong the support for the detection hypothesis $h$ is over the support for the null hypothesis $\bar{h}$. This ratio function may be familiar to some psychologists as the Luce choice ratio used in mathematical psychology models for a number of years.
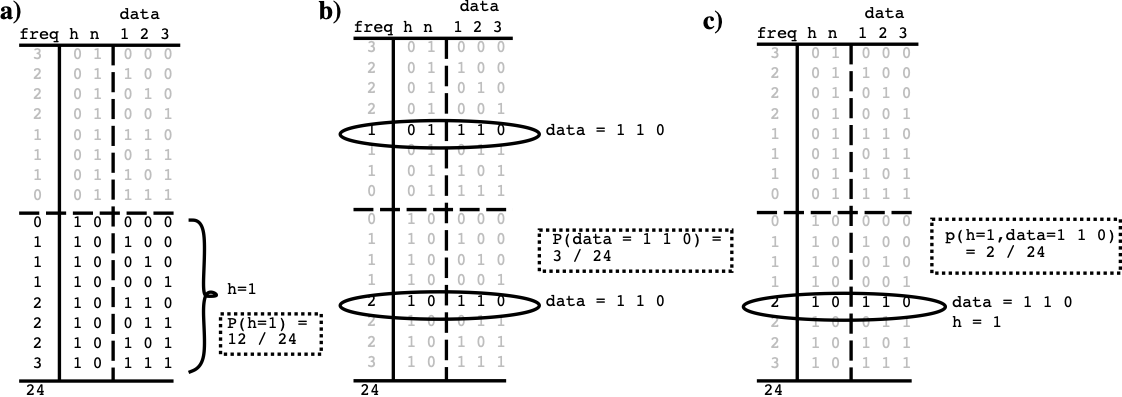
To have a concrete example to work with, consider a detector that receives inputs from three sources, such that when a vertical line is present (which is what it is trying to detect), all three sources are likely to be activated ([@fig:fig-vert-line-detector-probs]). The hypothesis $h$ is thus that a vertical line is actually present in the world, and $\bar{h}$ is that it is not. $h$ and $\bar{h}$ are mutually exclusive alternatives: their summed probability is always 1. There are three basic probabilities that we are interested in that can be computed directly from the world state table — you just add up the number of cases where a given situation is true, and divide by the total number of cases (with explicit and complete data, probability computations are just accounting):
-
The probability that the hypothesis $h$ is true, or $P(h=1)$ or just $P(h)$ for short = 12/24 or .5.
-
The probability of the current input data, e.g., $d=1 1 0$, which is $P(d=1 1 0)$ or $P(d)$ for short = 3/24 (.125) because it occurs 1 time when the hypothesis is false, and 2 times when it is true.
-
The intersection of the first two, known as the joint probability of the hypothesis and the data, written $P(h=1, d=1 1 0)$ or $P(h,d)$, which is 2/24 (.083).
| The joint probability tells us how often two different states co-occur compared to all other possible states, but we really just want to know how often the hypothesis is true when we receive the particular input data we just got. This is the conditional probability of the hypothesis given the data, which is written as $P(h | d)$, and is defined as follows: |
| $$ P(h | d) = \frac{P(h, d)}{P(d)} $$ |
So, in our example where we got $d=1 1 0$, we want to know: \(P(h=1 | d=1 1 0) = \frac{P(h=1, d=1 1 0)}{P(d=1 1 0)}\) which is (2/24) / (3/24), or .67 according to our table. Thus, matching our intuitions, this tells us that having 2 out of 3 inputs active indicates that it is more likely than not that the hypothesis of a vertical line being present is true. The basic information about how well correlated this input data and the hypothesis are comes from the joint probability in the numerator, but the denominator is critical for scoping this information to the appropriate context (cases where the particular input data actually occurred).
The above equation is what we want the detector to solve, and if we had a table like the one in [@fig:fig-vert-line-detector-probs], then we have just seen that this equation is easy to solve. However, having such a table is nearly impossible in the real world, and that is the problem that Bayesian math helps to solve, by flipping around the conditional probability the other way, using what is called the likelihood: \(P(d | h) = \frac{P(h, d)}{P(h)}\)
It is a little bit strange to think about computing the probability of the data, which is, after all, just what was given to you by your inputs (or your experiment), based on your hypothesis, which is the thing you aren’t so sure about! However, think of it instead as how likely you would have predicted the data based on the assumptions of your hypothesis. In other words, the likelihood computes how well the data fit with the hypothesis.
Mathematically, the likelihood depends on the same joint probability of the hypothesis and the data, we used before, but it is scoped in a different way. This time, we scope by all the cases where the hypothesis was true, and determine what fraction of this total had the particular input data state: \(P(d=1 1 0 | h=1) = \frac{P(h=1, d=1 1 0)}{P(h=1)}\) which is (2/24) / (12/24) or .167. Thus, one would expect to receive this data .167 of the time when the hypothesis is true, which tells you how likely it is you would predict getting this data knowing only that the hypothesis is true.
The main advantage of a likelihood function is that we can often compute it directly as a function of the way our hypothesis is specified, without requiring that we actually know the joint probability $P(h,d)$ (i.e., without requiring a table of all possible events and their frequencies). Assuming that we have a likelihood function that can be computed directly, Bayes formula is just a simple bit of algebra that eliminates the need for the joint probability: \(P(h, d) = P(d | h) P(h)\) such that: \(P(h|d) = \frac{P(d|h) P(h)}{P(d)}\) It allows you to write $P(h|d)$, which is called the posterior in Bayesian terminology, in terms of the likelihood times the prior, which is what $P(h)$ is called. The prior indicates how likely the hypothesis is to be true without having seen any data at all — some hypotheses are just more plausible (true more often) than others, and this can be reflected in this term. Priors are often used to favor simpler hypotheses as more likely, but this is not necessary. In our application here, the prior terms will end up being constants, which can actually be measured (at least approximately) from the underlying biology.
The last barrier to actually using Bayes formula is the denominator $P(d)$, which requires somehow knowing how likely this data is compared to any other. Conveniently, we can replace $P(d)$ with an expression involving only likelihood and prior terms if we make use of the null hypothesis $\bar{h}$. Because the hypothesis and null hypothesis are mutually exclusive and sum to 1, we can write the probability of the data in terms of the part of it that overlaps with the hypothesis plus the part that overlaps with the null hypothesis: \(P(d) = P(h,d) + P(\bar{h},d)\) In [@fig:fig-vert-line-detector-probs], this amounts to computing $P(d)$ in the top and bottom halves separately, and then adding these results to get the overall result: \(P(d) = P(d|h) P(h) + P(d|\bar{h}) P(\bar{h})\) which can then be substituted into Bayes formula, resulting in: \(P(h|d) = \frac{P(d|h) P(h)}{P(d|h) P(h) + P(d|\bar{h}) P(\bar{h})}\)
| This is now an expression that is strictly in terms of just the likelihoods and priors for the two hypotheses! Furthermore, it is this is the same equation that we showed at the outset, with $f(h,d) = P(d | h) P(h)$ and $f(\bar{h},d) = P(d | \bar{h}) P(\bar{h})$. It has a very simple $\frac{h}{h+\bar{h}}$ form, which reflects a balancing of the likelihood in favor of the hypothesis with that against it. It is this form that the biological properties of the neuron implement. You can use the table in [@fig:fig-vert-line-detector-probs] to verify that this equation gives the same results (.67) as we got using the joint probability directly. |
The reason we cannot use something like the table in [@fig:fig-vert-line-detector-probs] in the real world is that it quickly becomes intractably large due to the huge number of different unique combinations of input states. For example, if the inputs are binary (which is not actually true for neurons, so it’s even worse), the table requires $2^{n+1}$ entries for $n$ inputs, with the extra factor of two (accounting for the $+1$ in the exponent) reflecting the fact that all possibilities must be considered twice, once under each hypothesis. This is roughly $1.1 x 10^{301}$ for just 1,000 inputs (and our calculator gives $Inf$ as a result if we plug in a conservative guess of 5,000 inputs for a cortical neuron).
In lieu of the real data, we have to fall back on coming up with plausible ways of directly computing the likelihood terms. One plausible assumption for a detector is that the likelihood is directly (linearly) proportional to the number of inputs that match what the detector is trying to detect, with a linear factor to specify to what extent each input source is representative of the hypothesis. These parameters are just our standard weight parameters $w$. Together with the linear proportionality assumption, this gives a likelihood function that is a normalized linear function of the weighted inputs: \(P(d|h) = \frac{1}{z} \sum_i d_i w_i\) where $d_i$ is the value of one input source $i$ (e.g., $d_i = 1$ if that source detected something, and 0 otherwise), and the normalizing term $\frac{1}{z}$ ensures that the result is a valid probability between 0 and 1.
The fact that we are defining probabilities, not measuring them, makes these probabilities subjective, as compared to frequencies of objectively measurable events in the world. Nevertheless, the Bayesian math ensures that you’re integrating the relevant information in the mathematically correct way, at least.
To proceed, one could define the following likelihood function: \(P(d|h) = \frac{1}{12} \sum_i x_i w_i\) and similarly for the null hypothesis, which is effectively the negation: \(P(d|\bar{h}) = \frac{1}{12} \sum_i (1 - x_i) w_i\) If you plug these into the Bayesian equation, together with the simple assumption that the prior probabilities are equal, $P(h) = P(\bar{h}) = .5$, you get the same results we got from the table.
Finally, we compare the equilibrium membrane potential equation: \(V_m = \frac{g_e \bar{g}_e E_e + g_i \bar{g}_i E_i + \bar{g}_l E_l} {g_e \bar{g}_e + g_i \bar{g}_i + \bar{g}_l}\) ot the Bayesian formula, where the excitatory input plays the role of the likelihood or support for the hypothesis, and the inhibitory input and leak current both play the role of support for null hypotheses. Because we have considered only one null hypothesis in the preceding analysis (though it is easy to extend it to two), we will just ignore the leak current for the time being, so that the inhibitory input will play the role of the null hypothesis.
Interestingly, the reversal potentials have to be 0’s and 1’s to fit the numerical values of probabilities, such that excitatory input drives the potential toward 1 (i.e., $E_e = 1$), and that the inhibitory (and leak) currents drive the potential toward 0 (i.e., $E_i = E_l = 0$). \(V_m \approx P(h|d)\frac{g_e \bar{g}_e}{g_e \bar{g}_e + g_i \bar{g}_i}\) \(V_m \approx \frac{P(d|h) P(h)}{P(d|h) P(h) + P(d|\bar{h}) P(\bar{h})}\)
The full equation for $V_m$ with the leak current can be interpreted as reflecting the case where there are two different (and independent) null hypotheses, represented by inhibition and leak. As we will see in more detail in the Network Chapter, inhibition dynamically changes as a function of the activation of other units in the network, whereas leak is a constant that sets a basic minimum standard against which the detection hypothesis is compared. Thus, each of these can be seen as supporting a different kind of null hypothesis.
Taken together, this analysis provides a satisfying computational-level interpretation of the biological activation mechanism, and assures us that the neuron is integrating its information in a way that makes good statistical sense.