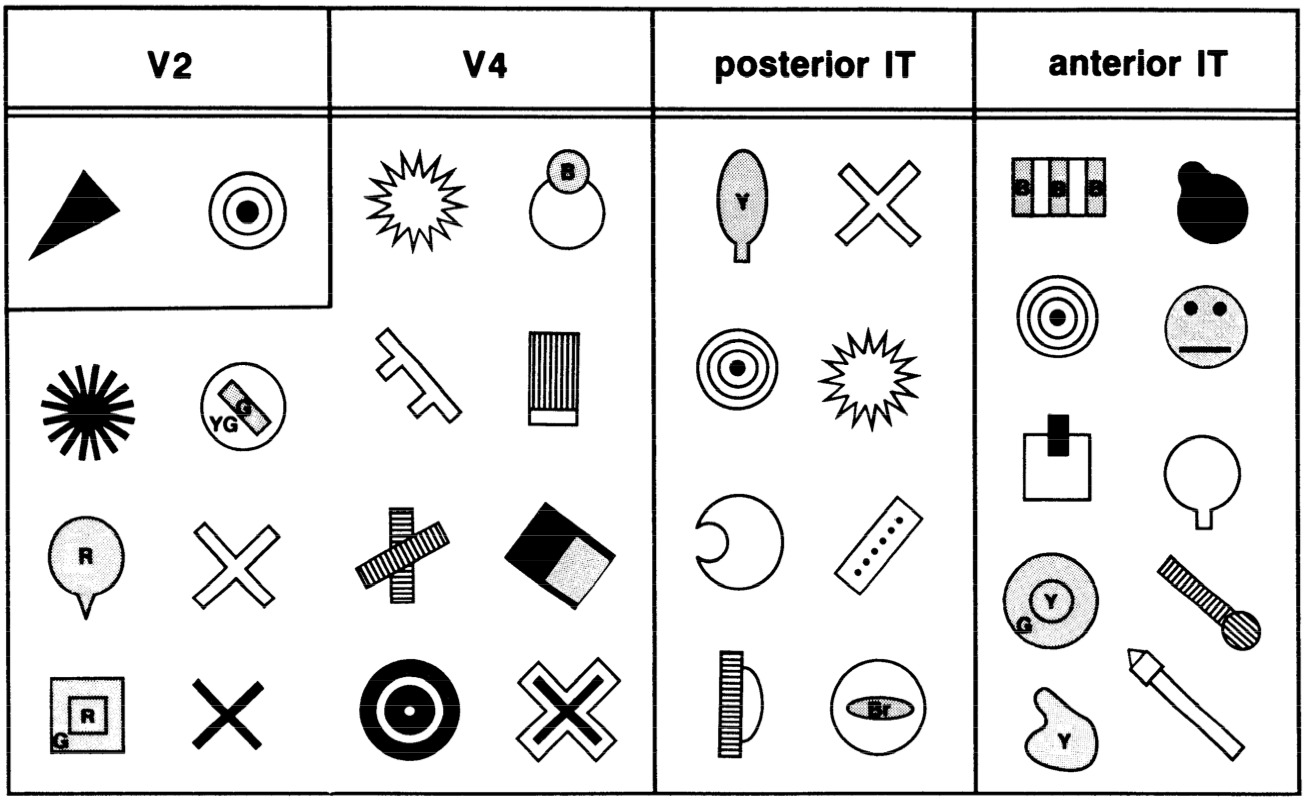
compcogneuro/book: 知覚と注意
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/book/blob/main/chapter-06.md
ライセンス: CC BY 4.0。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
bibfile: ccnlab.bib —
知覚と注意
知覚は明白であると同時に神秘的でもあります。私たちにとってそれは非常に簡単なことなので、内部で行われているすべての驚くべき計算に対する感謝の気持ちがほとんどありません。それにもかかわらず、私たちはより高いレベルの概念の比喩として「ビジョン」のような用語をよく使います (大統領はビジョンを持っていますか?)。おそらくこれは実際に深い真実を反映しています。つまり、私たちのより高いレベルの認知能力の多くは、多くのハードワークを行うための知覚処理システムに依存しているということです。知覚は単なる見る行為ではなく、新しいアイデアや困難な問題の解決策などを想像するときに常に活用されます。最も革新的な科学者の多く(例:アインシュタイン、リチャード・ファインマン)は、視覚的推論プロセスを使用して最大の洞察を導き出しました。アインシュタインは、スピードを上げてくる光線に追いつく様子を視覚化しようとしました(列車が興味深い方法で伸びたり縮んだりすることに加えて)。ファインマンの主な貢献の 1 つは、量子物理学における複雑な数学的操作を視覚的に図式化する手段でした。
教育学的に、知覚は私たちが認知現象に入る基礎として機能します。これは、認知領域の中で最もよく研究されており、生物学的に根拠のある領域です。その結果、私たちは知覚に関する多くの魅力的な現象のうちのほんの一部のみを取り上げ、主に視覚に焦点を当てます。しかし、私たちは他の知覚現象の背後にある一般原理の多くを捉える一連の中核的な問題に焦点を当てています。
まず、一次視覚野 (V1) の計算モデルから始めます。これは、自然画像に存在する主要な統計的規則性を捕捉する指向性エッジ検出器の起源を、自己組織化学習原理がどのように説明できるかを示します。このモデルはまた、興奮性の横方向の接続がどのように V1 の トポグラフィー の発達をもたらす可能性があるかを示しています。隣接するニューロンは互いに活性化する傾向があり、学習は活動によって決定されるため、隣接するニューロンは同様の特徴をコード化する傾向があります。
V1 で学習した機能に基づいて、物体が網膜に投影される際の表面の外観の大きなばらつきに関係なく、腹側何経路のより高いレベルがどのようにして物体を認識できるかを調査します。物体認識は、階層的に構成された一連の特徴カテゴリ検出器が、非常に困難な全体的な問題をどのように段階的に解決できるかを示す典型的な例です。この原理に基づいた計算モデルは、現実的な視覚画像上で高レベルの物体認識パフォーマンスを示すことができるため、おそらくこれが脳がこの問題を解決する方法である可能性が高いという説得力のある示唆を提供します。
次に、空間注意における背側どこ (またはどのように) 経路の役割を検討します。空間的注意は、ビュー内に複数のオブジェクトがある場合のオブジェクト認識など、多くのことにとって重要です。空間的注意は、オブジェクトの 1 つに処理を集中させるのに役立ちますが、他のオブジェクトに関連付けられたフィーチャのアクティビティを低下させ、潜在的な混乱を軽減します。処理ストリームの内容と場所の間のこの相互作用に関する私たちの計算モデルは、「どこ」経路への脳損傷の影響を説明することができ、脳の片側のみの損傷に対する半空間無視、および両側損傷を伴うバリント症候群と呼ばれる現象を引き起こします。神経学的に無傷な行動と脳が損傷した行動の両方を説明できるこの機能は、神経ベースのモデルを使用することの強力な利点です。
いつものように、知覚に関与する生物学的システムのレビューから始めます。
知覚の生物学
このセクションの目標は、情報が視覚システムをどのように流れるか、およびシステムのさまざまな部分がどのように動作するかについての基本的な事実を全体的に理解できる程度に生物学について理解することです。これは、情報処理の各ステップのより完全な全体像を提供する、後で登場するモデルの位置を特定するのに役立ちます。
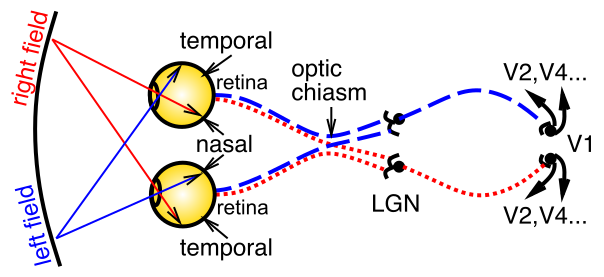
[@fig:fig-vis-optic-path] は、網膜を通って入って視床外側膝状核 (LGN) に進み、次に一次視覚野 (V1) に進む視覚信号の基本的な光学系と伝達経路を示しています。ここで、そして他の知覚様式やより一般的には知覚領域で働いている主な組織化原則は次のとおりです。
-
さまざまな情報の伝達 — 網膜では、光受容体が異なる 波長 (赤 = 長波長、緑 = 中波長、青 = 短波長) に敏感であり、色覚をもたらしますが、網膜信号の 空間周波数 ** (検出する特徴の粗さや細かさなど) も異なります — 中央の 中心窩 領域の光受容体は高い空間周波数 = 細かい解像度を持つことができますが、中央の 中心窩 領域の光受容体は高い空間周波数 = 細かい解像度を持つことができます。周辺部は解像度が低い)、時間応答** (動きに対する感度の違いを含む、速い応答と遅い応答)。
-
地形的な方法での情報の編成 — たとえば、左視野と右視野は皮質の対側半球に編成されます — 図が示すように、視覚空間の左部分からの信号は右半球に送られ、その逆も同様です。 LGN および V1 内の情報も、さまざまな方法で地形的に整理されます。この構成により、一般に、同様の情報を対比して強化された信号を生成することができ、また、より高いレベルでの処理を簡素化するためにグループ化することもできます。
-
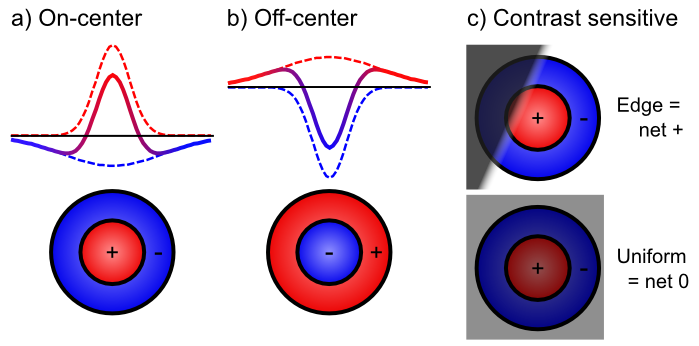
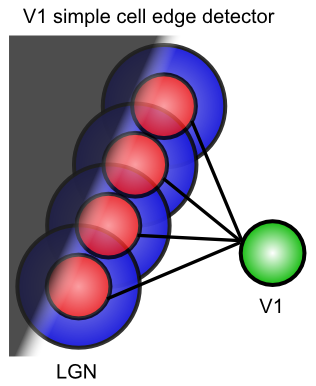
無関係な信号をフィルタリングしながら、関連する信号を抽出する — [@fig:fig-on-off-rfields-edge] は、中心-サラウンド 受容野 (例: オンセンター、オフサラウンド、またはその逆) を使用して、網膜細胞が均一照明ではなく ** コントラスト** にのみどのように反応するかを示しています。この受容野の一部が他の部分と比較して異なる量の光を受けた場合にのみ、これらのニューロンは反応します。通常、これは、図に示すように、照明が明暗の間で遷移するコントラストのエッジで発生します。これらの遷移は、画像の最も有益な側面ですが、一定の照明の領域は無視しても問題ありません。 [@fig:fig-v1-simple-dog-edge] は、これらのセンター サラウンド信号 (LGN にも存在します) を V1 の単純なセルに統合して、これらのエッジの方向を検出する方法を示しています。これらのエッジ検出器は、V1 で画像を記述するための基本語彙を形成します。これらの基本的な線/エッジ要素から、より複雑な形状を構築できます。 V1 には、単純なセル応答 ([@fig:fig-v1-visual-filters-hypercols-basic]) に基づいて構築された複雑なセルも含まれており、より豊富な基本語彙を提供します。
次のビデオは、これらの受容野がどのようなものかを知る方法を示しています。
-
古い学校のプロジェクター刺激を使用した古典的な Hubel & Wiesel V1 受容野マッピング: YouTubeビデオ
-
新しい逆相関 V1 受容野マッピング: YouTubeビデオ
![V1 内の複雑な細胞タイプと単純な細胞タイプ: 複雑な細胞 (図の上半分) は、複数の位置にわたって統合することによってより大きな受容野を作成すること (V1-Simple-Max 細胞はこの空間統合のみを行います)、および極性 (オンとオフのコーディング領域の位置) 全体で抽象化することを含む、単純な細胞のプロパティを統合します。エンドストップ セルは最も複雑で、特定の単純なセルに隣接するあらゆる形式の対照的な方向を検出します。 V1 単純セル (図の下半分) は、[@fig:fig-v1-simple-dog-edge] で説明されているように、コントラストの方向性のあるエッジを検出します。シミュレーターでは、V1 シンプル セルはガボール フィルターを使用してより直接的にエンコードされ、指向性エッジ感度が数学的に記述されます。](https://raw.githubusercontent.com/compcogneuro/book/main/figures/fig_v1_visual_filters_hypercols_basic.png)
聴覚経路において、蝸牛膜は網膜と同様の役割を果たし、音の周波数に応じた地形的な組織化も行っており、音をスペクトログラムにフーリエ変換したものと大まかに等価なものを生成します。この基本的な音声信号は聴覚経路で処理され、視覚で発生するのとほぼ同じ方法で、時間の経過とともに関連する音のパターンが抽出されます。
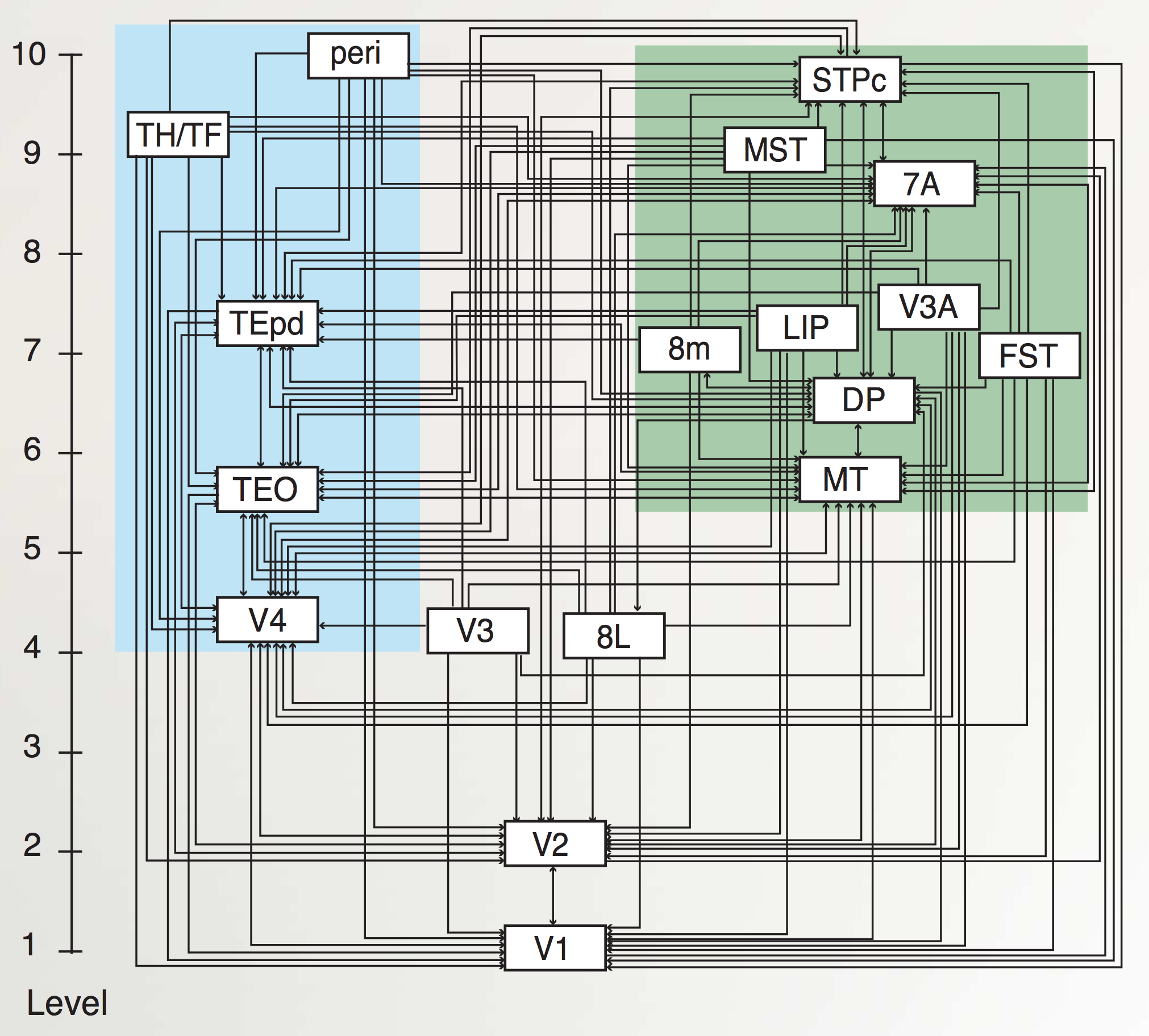
ネットワークの章で説明したように、一次視覚野を超えて、知覚システムは、階層的に組織された神経検出器層の力の優れた例を提供します。 [@fig:fig-markov_cort_hier-6] は、V1 以降 [@MarkovVezoliChameauEtAl14; @FellemanVanEssen91] までのすべての主要な視覚野の解剖学的接続パターンを示します。厳密な階層の外側にも多くの相互接続があるにもかかわらず、図に示すように、接続の特定のパターンにより階層構造を抽出できます。
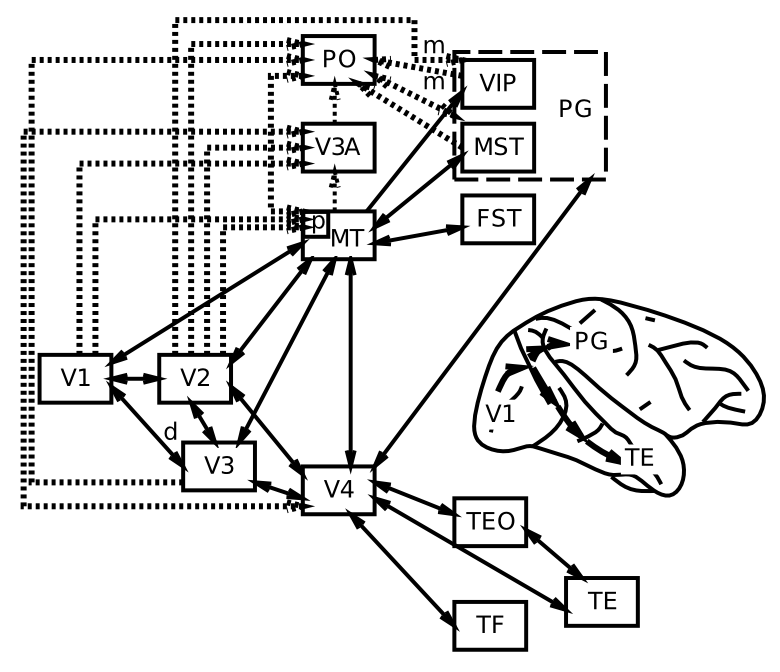
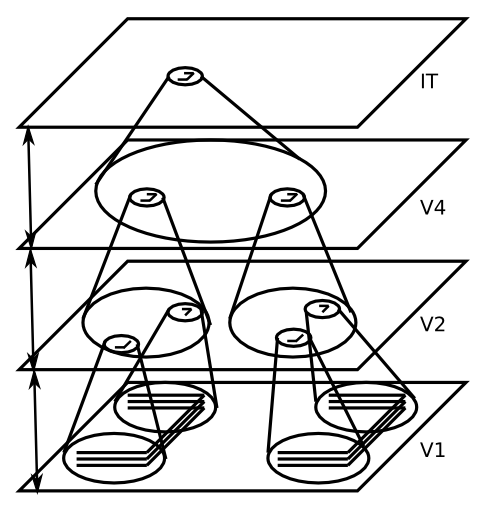
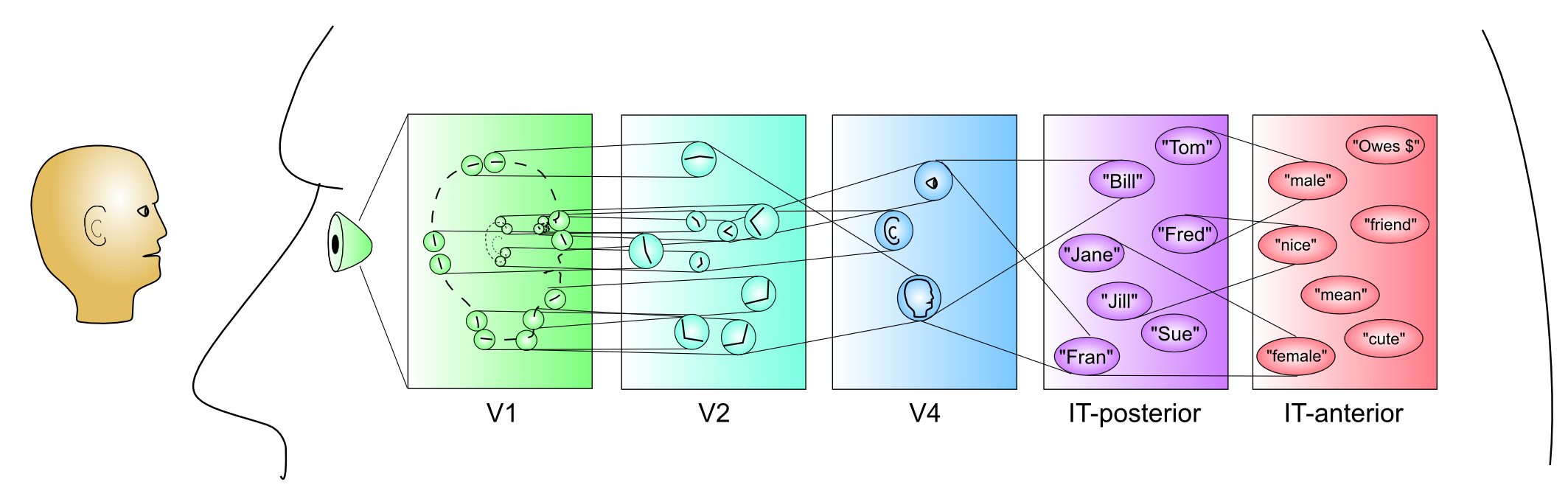
[@fig:fig-vis_system_bio-6] は、これらの領域を解剖学的位置に配置し、視覚処理 [@UngerleiderMishkin82] における 何を対どこ (腹側と背側) の分割をより明確に示します。 V1 から V4 まで腹側方向に下側頭皮質 (IT) の領域に向かう投影 (TE、TEO、前の図では後部 IT の PIT とラベル付けされている) は、視覚入力内の物体の同一性 (「何を」) を認識するのに重要ですが、頭頂皮質を通過する投影は、MT および MST 領域の運動信号を含む空間 (「どこ」) 情報を抽出します。この章の後半では、これらの視覚的な処理ストリームがそれぞれどのように独立して機能するのか、また相互に作用して知覚における重要な計算問題を解決するのかを見ていきます。
以下は、視覚経路の 何を 側に上る情報の流れの簡単な概要です (図 6.5 の左側に図示):
-
V1 — 一次視覚野。さまざまな配向角度に沿ったエッジ (照明の遷移) に応答する配向エッジ検出器の観点から画像をエンコードします。この章の最初のシミュレーションでは、これらのエッジ検出器が自然画像の信頼できる統計によって駆動される自己組織化学習を通じてどのように発展するかを見ていきます。
-
V2 — 二次視覚野。より複雑な形状を検出するための基盤を提供する、他の多くの基本的な視覚機能 (例: 3D 深さの選択性、基本的なテクスチャなど) とともに、交差点や接合部のボキャブラリーを開発するためのエッジ検出器の組み合わせをエンコードします。これらの V2 ニューロンは、これらの特徴をより広範囲の場所でエンコードし、最終的に IT ニューロンが視野内のどこに現れるかに関係なく、物体を認識できるようになるプロセスを開始します (つまり、不変 物体認識)。
-
V4 — より広い範囲の位置 (およびサイズ、角度など) にわたって、より複雑な形状特徴を検出します。
-
IT-posterior (PIT) — 広範囲の位置、サイズ、角度にわたってオブジェクト全体の形状を検出します。たとえば、側頭葉の下面の紡錘状回の近くには、紡錘状顔面領域 (FFA) と呼ばれる領域があり、特に顔に反応すると思われます。ただし、ネットワーク の章で見たように、オブジェクトは IT の幅広い領域にわたって分散表現でエンコードされます。
-
IT-anterior (AIT) — これは、視覚情報が本質的に非常に抽象的で 意味論的になる場所です — それは、さまざまな人、場所、物に関するあらゆる種類の重要な情報をエンコードできます。
対照的に、背側から頭頂皮質(MT、VIP、LIP、MSTの領域)に直接上る視覚処理の場所の側面には、動き、深さ、およびその他の空間的特徴の処理に重要な領域が含まれています。
一次視覚野の指向性エッジ検出器
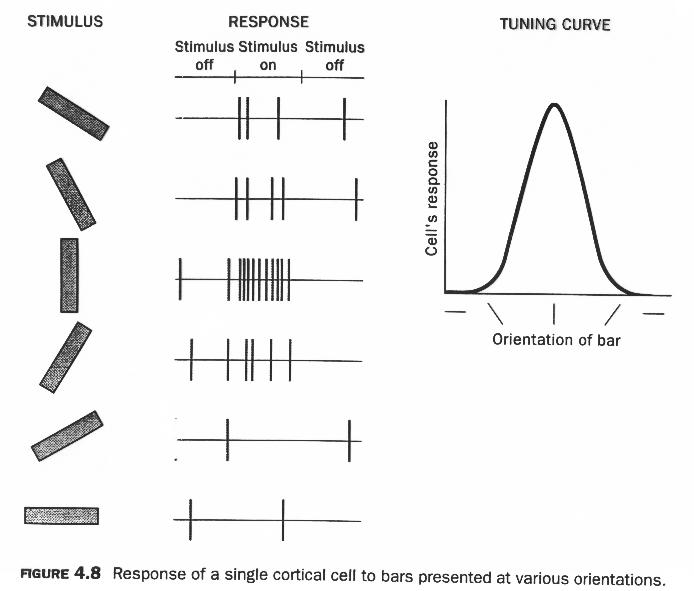
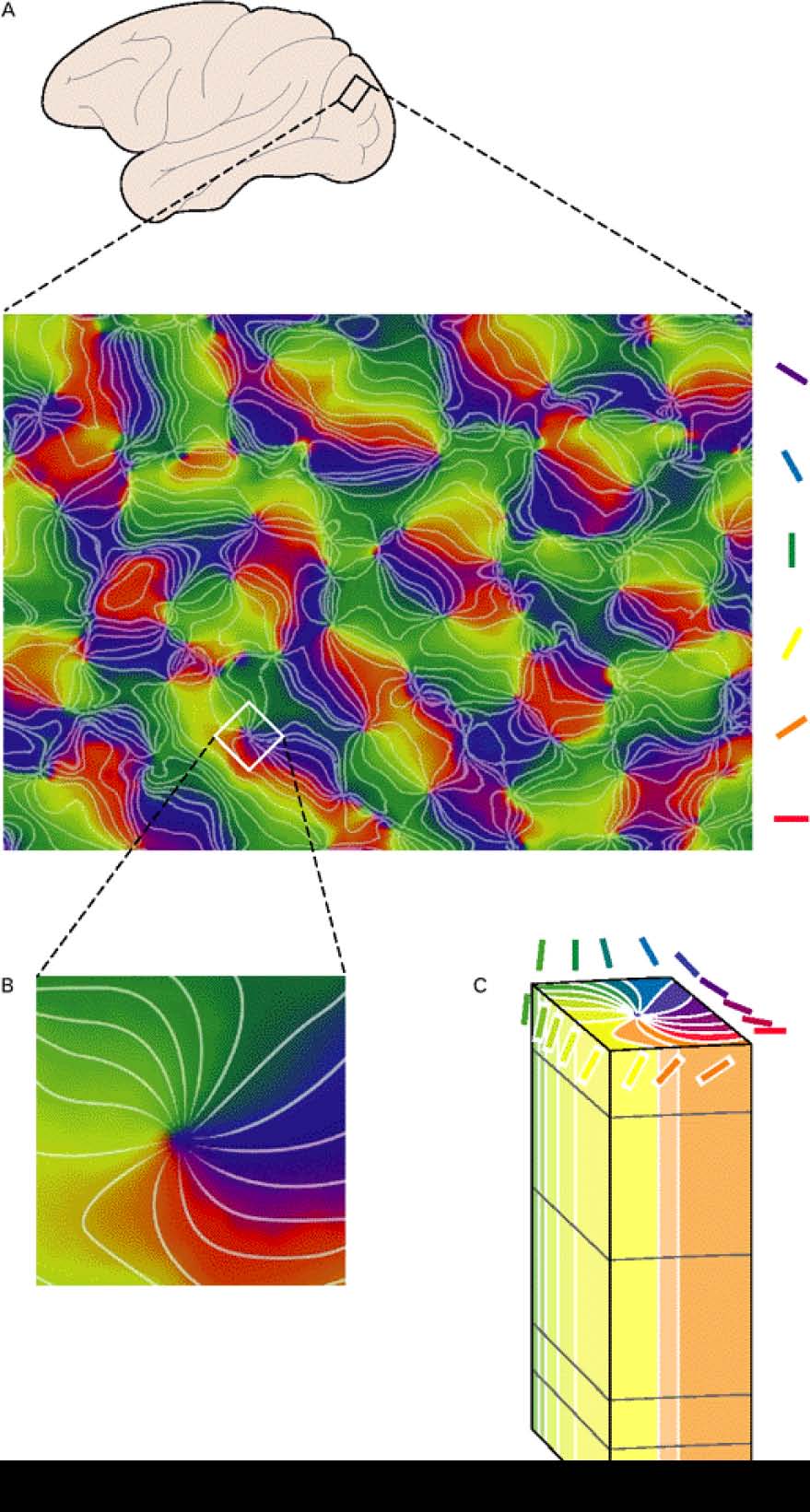
一次視覚野(V1)のニューロンは、その受容野(RF — 特定のニューロンが入力を受け取る視野の領域)内の光のエッジまたはバーの方向を検出します。 [@fig:fig-v1-orientation-tuning-data] は、配向バーに応答した個々の V1 ニューロンの電気生理学的記録からの特徴的なデータを示します。このニューロンは垂直方向に最大限に反応し、その両側で段階的に減衰します。これは、チューニング カーブの非常に典型的な形式です。 [@fig:fig-v1-orientation-cols-data] は、これらの方向調整されたニューロンが*地形学的**に組織化されており、隣接するニューロンが同様の方向をコード化する傾向があり、方向調整が皮質の表面にわたってかなり連続的に変化することを示しています。
このセクションで私たちが取り組もうとしている疑問は、なぜこのような指向性エッジ検出器の地形的組織が一次視覚野に存在するのかということです。この質問には複数のレベルの答えがあります。最も抽象的なレベルでは、これらの方向性のあるエッジは、通常私たちの網膜に映る種類の画像の基本構成要素です。これらは、自然画像 [@OlshausenField96] の最も明らかな *統計的規則性 ** です。これが実際に当てはまる場合、(学習* の章で説明したように) モデルで使用されている XCAL 学習アルゴリズムの自己組織化の側面により、これらの統計的規則性が自然に抽出され、別のレベルの説明が提供されることが期待されます。V1 は、学習メカニズムが自然に開発するものであるため、指向性エッジ検出器を表します。
ここでの状況は、学習 章で検討した自己組織化学習モデルと本質的に同等です。このモデルは、水平線と垂直線にさらされ、環境におけるこれらの強力な統計的規則性を表すことを学習しました。
しかし、その初期のシミュレーションでは、V1 ニューロンのトポグラフィーに対処することはできませんでした。なぜ隣接するニューロンが同様の情報をエンコードする傾向があるのでしょうか?次のシミュレーションで私たちが探求する答えは、近隣レベルの接続により、近くのニューロンが一緒に活性化する傾向があり、活動が学習を促進するため、同様のことを学習する傾向があるということです。
シミュレーションの探索
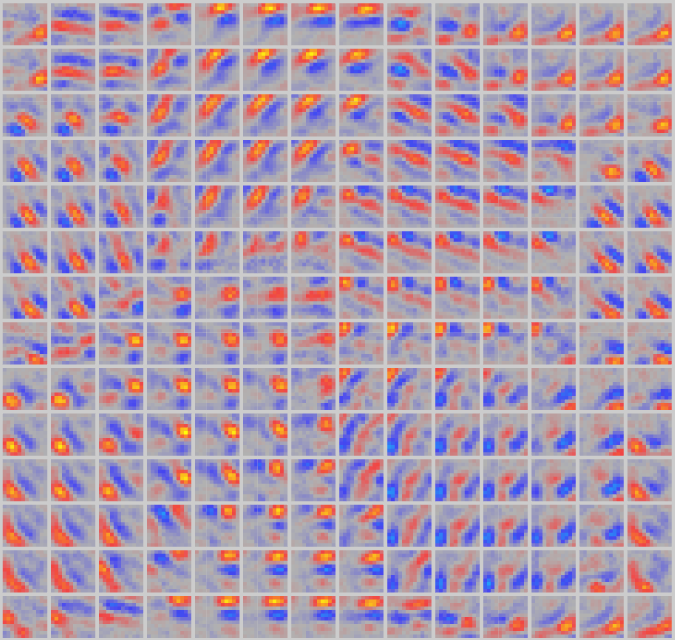
CCNシムズ の v1rf を開いて、V1 での指向性エッジ検出器の開発を調べます。このモデルは一連の自然画像にさらされ、方向性のあるエッジをエンコードすることを学習します。これは、これらの画像に存在する統計的規則性であるためです。 [@fig:fig-v1rf-map] は、展開される方向の結果マップを示します。
What 経路における不変オブジェクト認識
物体認識は、視覚処理の腹側「何を」経路の定義的な機能であり、見ているものを識別します。下側頭 (IT) 皮質のニューロンは、視覚空間の広い領域にわたって、顔、車などの物体全体を検出できます。この 空間的不変性 (神経反応が空間的位置にわたって同じまたは不変である場合) は、世界における効果的な動作にとって重要です。物体はあらゆる異なる場所に現れる可能性があり、私たちはそれらがどこに現れるかに関係なく認識する必要があります。この結果を達成することは非常に困難なプロセスであり、人工知能 (AI) 研究者を長い間悩ませてきました。AI の初期の 1960 年代には、物体認識は夏の研究プロジェクトとして解決できると楽観的に考えられていました。50 年経った今でも私たちは多くの進歩を遂げていますが、人間は依然として私たちのモデルよりもはるかに優れているという意味では未解決のままです。近年の大幅な進歩と、現在のモデルが実際に人間の物体認識能力を超えているという主張にもかかわらず、人間の視覚は世界の基礎となる 3D 構造を実際に見るのにはるかに優れた仕事をしているのに対し、現在の AI モデルは通常、よりテクスチャベースのエンコーディングのレベルでパターン識別を行うだけであることに変わりはありません。 そのため、人間では決して犯さないような分類上の間違いを犯しやすくなります。 いずれにせよ、私たちの脳は常に物体認識を楽々と行っているため、それがどれほど難しい問題であるかはあまり理解されていません。
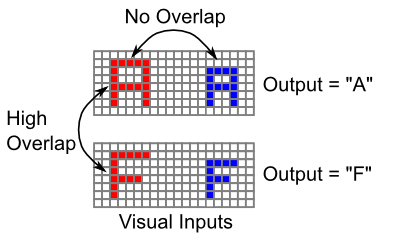
物体認識が非常に難しい理由は、異なる場所にある同じ物体の視覚入力 (サイズ、回転、色など) の間にはまったく重なりがないことがよくある一方で、同じ場所にある異なる物体の間には高レベルの重なりが存在する可能性があるためです ([@fig:fig-objrec-difficulty])。したがって、ボトムアップの視覚的類似性構造に依存することはできません。代わりに、多くの場合、これらの刺激の目的の出力分類に対して直接作用します。 学習 の章で見たように、自己組織化学習は入力の類似構造によって強く駆動される傾向があるため、この状況で学習を成功させるにはエラー駆動型の学習が必要です。
[@Fukushima80] によって最初にモデルで提唱された、物体認識問題に対する最も成功したアプローチは、階層的に組織された一連の層 [@fig:fig-invar-trans; @fig:fig-category-hierarch-dist-reps-6] にわたって 2 つの問題を段階的に解決することです。
-
不変性の問題。各層を前の層の特徴の 位置範囲 (およびサイズ、回転など) で統合することで、階層が上がるにつれてニューロンがますます不変になります。
-
パターン識別問題 (たとえば、A と F を区別する)。前の層に存在する * 特徴の組み合わせ* を検出した結果として、各層に特徴検出器のより複雑な組み合わせを構築させることで、階層が上がるにつれてニューロンが類似の入力パターンでもよりよく識別できるようになります。
これらのモデルから得られる重要な洞察は、これら 2 つの問題を段階的な階層的なステップに分割することで、システムは一方が他方に問題を引き起こすことなく両方の問題を解決できるということです。たとえば、任意の場所の垂直線に応答する単純で完全に不変の垂直線検出器がある場合、この線が他の入力フィーチャとどのような空間的関係を持っているかを知ることは不可能であり、この関係情報は異なるオブジェクトを区別するために重要です (たとえば、T と L は 2 つの線要素の関係のみが異なります)。したがって、最初の 1 回のパスで不変性の問題を解決し、その上でパターン識別問題を解決しようとすることはできません。これらは段階的にインターリーブする必要があります。同様に、視覚入力内の考えられる各位置で非常に複雑なオブジェクト パターンを認識しようと試み、その後、位置全体にわたって空間不変性の統合を行うことは完全に非現実的です。区別するにはさまざまなオブジェクトが多すぎるため、異なる視覚的な場所ごとにそれらについて改めて学習する必要があります。ますます不変になる視覚的特徴の「パーツ ライブラリ」を段階的に構築する方がはるかに実用的です。これにより、すでに空間的に不変であり、一度学習するだけで済む方法で、階層の最上位に向かってのみ複雑なオブジェクトについて学習できるようになります。
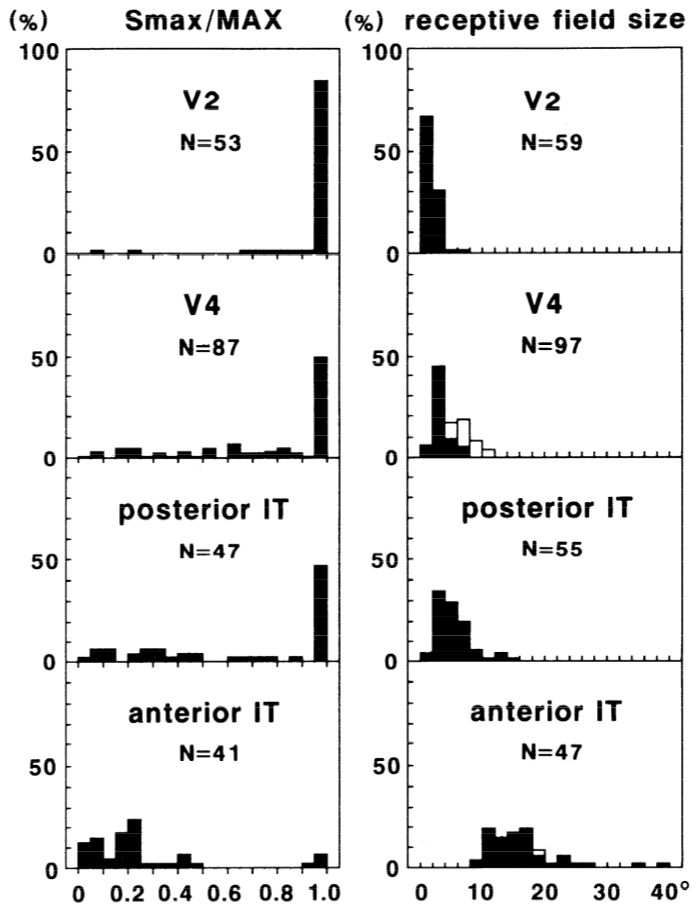
トップダウンの計算動機とボトムアップの神経科学データの満足のいく収束において、この漸進的で階層的なソリューションは、腹側経路 (V1、V2、V4、IT) に沿った視覚野の既知の特性にうまく適合します。 [@fig:fig-kobatake-tanaka-94-invariance] は、マカクザル [@KobatakeTanaka94] のこれらの領域からの神経記録をまとめたもので、領域の階層が上がるにつれて、ニューロンの反応を促す刺激の複雑さと、これらの刺激に対して不変の反応を示す受容野のサイズが増加することを示しています。 [@fig:fig-kobatake-tanaka-94-v2-v4-it] は、これらのニューロンがどのような種類の複雑な特徴の結合を検出できるかを示すために、これらの領域のそれぞれで最大の反応を引き起こした複雑な刺激の例を示しています。
物体認識の探求
CCNシムズ でオブジェクト認識の計算モデルの objrec シミュレーションを開きます。これは、オブジェクト認識問題に対する増分階層ソリューションを示します。垂直線要素と水平線要素から構成される単純化された「オブジェクト」セット ([@fig:fig-objrec-objs]) を使用します。この単純化された一連の視覚的特徴により、モデルがどのように機能するかをより深く理解できるようになり、これらの同じ特徴セットから構成される新しいオブジェクトへの一般化をテストすることも可能になります。モデルが領域 V4 の線要素のより単純な組み合わせと、IT の特徴のより複雑な組み合わせを学習することがわかります。これらはまた、完全な受容野にわたって不変です。これらの IT 表現は、オブジェクト全体と同一ではありません。代わりに、オブジェクトの構成要素の特徴に関して、オブジェクトの不変の分散コードを表します。一般化テストは、この一連の機能を共有する限り、この分散コードが新しいオブジェクトの迅速な学習をどのようにサポートできるかを示します。それらはおそらくはるかに複雑で、あまり明確に定義されていませんが、視覚的な形状の特徴に関する同様の語彙が霊長類のIT表現で学習されているようです。
どこで/どのように 経路における空間的注意と無視
頭頂皮質に入る背側の視覚経路は、その経路の主な機能であると思われる腹側の「何」経路で行われる物体認識処理に比べて、その機能がより不均一です。もともと、背側経路は、腹側の「何を」経路 [@UngerleiderMishkin82] とは対照的に、「どこで」経路として説明されていました。しかし、[@GoodaleMilner92] は、この経路を「どのように」機能、つまり知覚から行動へのマッピングを実行するものとして、説得力のある広範な解釈を提供します。この「方法」機能の 1 つの側面には、空間位置情報が含まれます。この情報は 3D 空間での運動動作の制御に非常に関連していますが、空間情報は、頭頂葉によってサポートされる幅広い機能にとって定義が狭すぎます。頭頂部は、数値的および数学的処理や、抽象的な関係情報の表現などに重要です。頭頂皮質の領域は、内側側頭葉のエピソード記憶機能やその他のさまざまな機能を調節するのにも重要であると考えられます。この後者の例は、前頭前皮質の認知制御に関連するより広範な一連の機能を表す可能性があります。頭頂皮質の領域は、ほとんどの場合、要求の高い認知制御タスクにおいて前頭前野と組み合わせて活動しますが、通常、それらがどのような正確な役割を果たしているのかについてはほとんど理解されていません。

この章では、頭頂部機能の確立された「場所」の側面に焦点を当て、運動制御に関する次の章で「どのように」機能の一部を取り上げます。空間処理の領域内でも、頭頂部の空間表現を使用して実行できる認知機能は数多くありますが、ここでは空間位置に注意を集中させる際の頭頂部の空間表現の役割に焦点を当てます。前のセクションに関連して、空間的注意の重要な機能の 1 つは、複数の異なるオブジェクトが存在する視覚的なシーンでオブジェクト認識が機能できるようにすることです。たとえば、豊富な視覚的詳細が詰め込まれた「ウォーリーどこ」パズル ([@fig:fig-wheres-waldo]) について考えてみましょう。このようなシーンをワンテイクですべて認識することは可能でしょうか?いいえ。視覚的注意の「スポットライト」を使用して画像全体をスキャンして、画像の小さな領域に焦点を合わせる必要があります。これにより、オブジェクト認識経路によって効果的に処理できるようになります。この注目のスポットライトを向ける能力は、背側経路の空間表現に依存しており、背側経路の空間表現は、物体認識経路の下位レベル (V1、V2、V4) と相互作用して、この注目のスポットライト内から来る視覚的特徴のみを反映するように入力を制約します。
半側空間無視
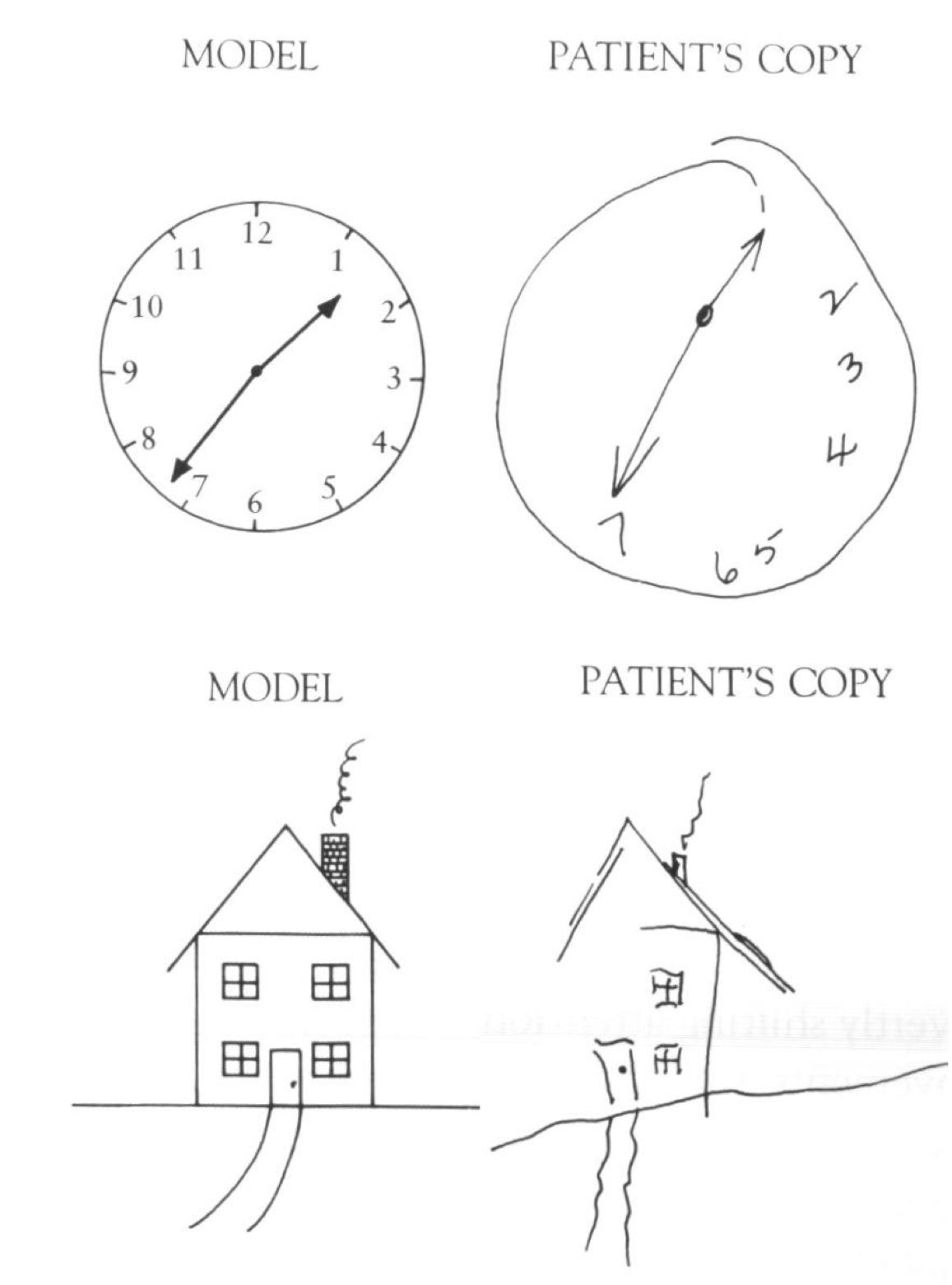

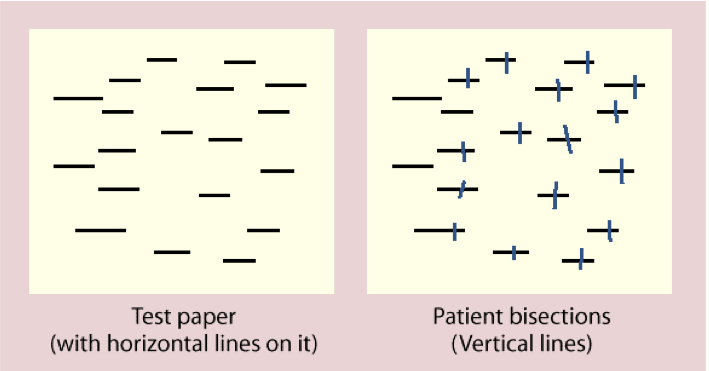
頭頂皮質が空間的注意にとって重要であるという最も顕著な証拠のいくつかは、空間の片側を無視または軽視する傾向がある半側空間無視の患者から得られます(図6.17、6.18、6.19)。この状態は通常、右頭頂皮質に影響を与える脳卒中または他の形態の脳損傷によって発生し、その結果、空間の左半分が無視されます(生物学のセクションで示される視覚情報の交差により)。興味深いことに、[@fig:fig-neglect-line-bisect] に示すように、この無視は複数の異なる空間参照フレームに適用されます。ここでは、画像の左側の線が無視される傾向があり、また、個々の線がより右に向かって二等分されており、各線の左側の部分が無視されていることを示しています。
Posner 空間キューイング タスク
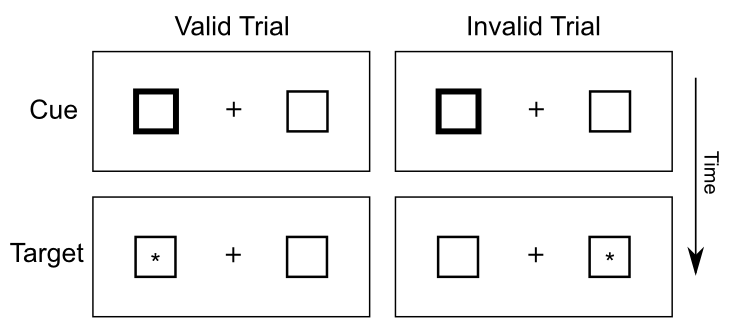
空間的注意のスポットライトを研究するために最も広く使用されているタスクの 1 つは、Michael Posner [@Posner80] ([@fig:fig-posner-task]) によって開発された Posner 空間キューイング タスクです。視覚空間の片側が合図され、その後の目標検出に対するこの合図の効果が測定されます。キューとターゲットが空間の同じ側に表示される場合 (有効 キュー条件)、空間の異なる側に表示される場合 (無効 キュー条件) に比べて反応時間は速くなります。この反応時間 (RT) の違いは、空間の注意が空間の合図側に集められ、ターゲットの検出が容易になることを示唆しています。実際、無効なケースは、手がかりがまったくない中立状態よりも悪く、空間の注意を空間の正しい側に再割り当てするプロセスにある程度の時間がかかることを示しています。興味深いことに、このタスクは通常、合図に向かって視線が移動するのを防ぐために、合図とターゲットの間の時間間隔を十分に短くして実行されます。したがって、これらの注意効果は 隠れた注意 として説明されます。
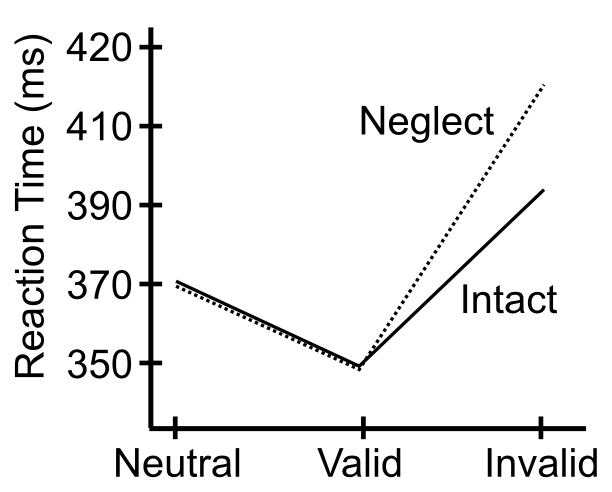
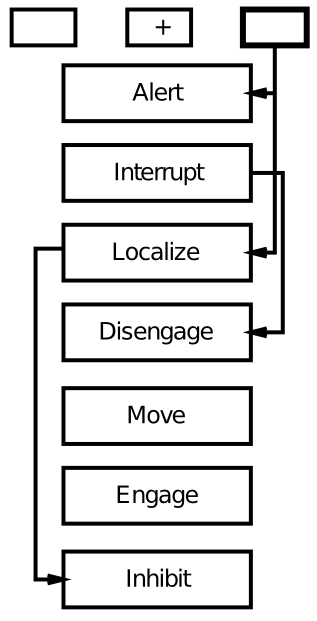
[@fig:fig-posner-graph] に示されているように、半側空間無視の患者は、無効な手がかりの場合、特に標的が左側に表示されているのに良好な視野 (通常は右側) に手がかりが提示された場合、反応時間の不釣り合いな増加を示します。ポズナー博士は、空間手がかりタスクのボックスアンドアローモデル ([@fig:fig-posner-disengage-mech]) によれば、このデータを利用して、これらの患者は注意を解くことが困難であることを示唆しています。
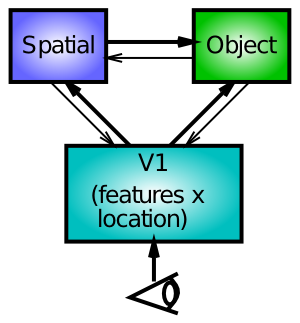
ここでは、空間処理経路とオブジェクト処理経路の間の双方向の相互作用に基づいた代替アカウントを検討します ([@fig:fig-spat-attn-lateral])。この説明では、空間処理経路の半分が損傷すると、その側はネットワークの無傷の側と競合できなくなります。したがって、競合するものがあるとき(たとえば、キューイングパラダイムにおけるキュー)、ダメージの影響が最も顕著になります。
重要なのは、これらのモデルは、両側頭頂部損傷の影響に関して明確な予測を行うことです。この症状を持つ患者は、視野 [@CoslettSaffran91] 内に複数の物体が存在する場合に、物体を認識する能力が著しく低下することを特徴とするバリント症候群に罹患していることが知られています。これは、混雑した視覚シーンにおける物体認識を促進する上で、空間的注意が重要な役割を果たすことを示唆しています。ポズナーの離脱モデルによれば、両側の損傷により空間の「両側」からの離脱が困難になり、空間の両側での無効な試行が遅くなるはずです。対照的に、競争ベースのモデルは逆の予測をします。つまり、損傷は空間の「両側」での競争を減少させる役割を果たし、その結果、両側で注意力の効果が減少するはずです。つまり、無効なキューの効果は実際には減少します。データは競合モデルと一致しており、Posner のモデル [@VerfaellieRapcsakHeilman90] とは一致しません。
空間的注意の探求
CCNシムズ で attn_simpl を開き、複数の物体の知覚などの複数の空間注意タスクと Posner 空間キューイング タスクのコンテキストで相互作用する空間経路と物体経路を含むモデルを探索します。これは上記の行動データを再現しており、バリント患者の注意力の低下という観察されたパターンを正確に示しています。