compcogneuro/book: モーター制御と強化学習
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/book/blob/main/chapter-08.md
ライセンス: CC BY 4.0。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
bibfile: ccnlab.bib —
モーター制御と強化学習
認知の基礎は、感覚と運動のループ、つまり感覚入力を処理して次に実行する運動動作を決定することによって構築されます。これは神経系の最も基本的な機能です。人間の脳には、末梢神経系の最も原始的な反射から、おそらく前頭前野 (PFC) での最高レベルの処理 (あるいはおそらく何らかの基本的な狂気のレベル…誰にも分からない ;) が関係する、大学院への応募や入学の決定など、最も抽象的で不可解な計画に至るまで、進化のタイムスケールに及ぶ膨大な数のそのようなループがあります。
| 学習信号 | ダイナミクス | |||||
|---|---|---|---|---|---|---|
| エリア | 報酬 | エラー | 自己組織 | 区切り文字 | インテグレーター | アトラクター |
| 大脳基底核 | +++ | — | — | ++ | - | — |
| 小脳 | — | +++ | — | +++ | — | — |
| 海馬 | + | + | +++ | +++ | — | +++ |
| 新皮質 | ++ | +++ | ++ | — | +++ | +++ |
表: 脳の 4 つの主要領域にわたる学習メカニズムと活動/表現のダイナミクスの比較。 +++ は、そのエリアに確実に特定の特性があることを意味し、+ が少ない場合は、この地物に対する信頼性および/または重要性が低いことを示します。 --- は、そのエリアに特定のプロパティが明らかに存在しないことを意味し、やはり - が少ない場合は、信頼度または重要性が低いことを示します。
この章では、最も重要なモーター出力と制御システム、およびそれらの動作を制御する学習メカニズムのいくつかを取り上げることによって、知覚と注意 に関する前の章で開始したループを完了します。皮質下レベルでは、小脳 と 大脳基底核 が 2 つの主要な運動制御領域であり、それぞれが 学習 章 [@tbl:table-learning-8] で説明されている汎用の皮質学習メカニズムとは異なる、特別に適応された学習メカニズムを備えています。大脳基底核は、報酬/罰への期待と比較して報酬/罰シグナルから学習することに特化しており、この学習により、生物がさまざまな状況下で行う行動選択が形成されます(最も報酬のある行動を選択し、罰的な行動を回避する; [@fig:fig-bg-action-sel-dam])。この形式の学習は 強化学習 と呼ばれます。小脳は、エラー、具体的には、運動動作に関連する感覚結果に対する期待に対する、運動動作に関連する感覚結果間のエラーから学習することに特化しています。したがって、小脳は、特定の運動計画の実行を改良して、より正確で、効率的で、よく調整されたものにすることができます。
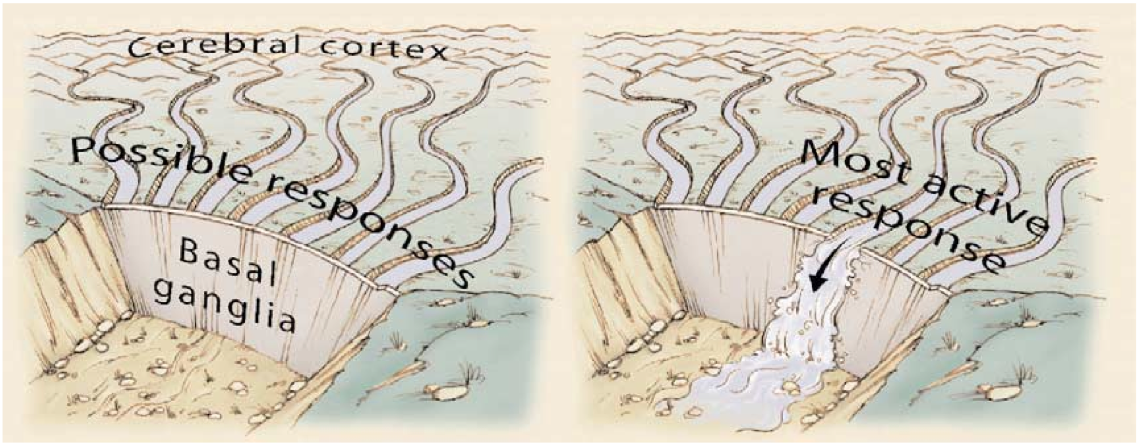
ここには素晴らしい役割分担があり、大脳基底核が実行可能な多くの動作の中から 1 つを選択するのを助け、小脳が選択された動作が適切に実行されることを確認します。このかなり明確な分業と一致して、大脳基底核と小脳の間には直接的なつながりはなく、代わりに、それぞれが皮質のさまざまな領域と相互作用して動作し、そこで行動計画が策定され、調整されます。大脳基底核と小脳は両方とも、後部前頭葉の運動制御領域とその前方の 前頭前皮質を含む 前頭皮質と密に相互接続されています。また、前の章で説明したように、頭頂皮質は、空間マップや環境内の物体間の相対的な空間関係などを計算することによって、感覚情報を運動出力 (つまり、「方法」経路) にマッピングするのに重要です。したがって、頭頂表現は小脳によって調整されるように運動動作の実行を駆動し、小脳は頭頂皮質とも密に相互接続されています。対照的に、大脳基底核は、環境内に存在する可能性のある報酬対象物の種類(特定の種類の食物など)を示す腹側経路の「何を」情報によってはるかに大きく駆動されます。頭頂部からもある程度の入力を受け取りますが、小脳ほどではありません。
小脳と大脳基底核は両方とも複雑な脱抑制出力ダイナミクスを持ち、それが制御する脳領域にゲートのような効果を生み出します。たとえば、大脳基底核は、前頭葉および前頭前皮質領域を通る双方向の興奮回路を持つ視床の特定の核内のニューロンを脱抑制することができます。この抑制解除の最終的な効果は、アクションの実行方法の詳細を指定することなく、アクションの続行を 可能にすることです。これが ゲート の意味するところです。他の形式の活性化の流れを幅広く調整するものです。小脳も同様に、頭頂ニューロンと前頭ニューロンの抑制を解除して、運動動作の形状を正確に制御する形に影響を与えます。また、脳幹の運動出力にも直接投影されますが、これはほとんどの大脳基底核領域には当てはまりません。
この章は、強化学習メカニズム (他の脳領域も関係する) を含む大脳基底核システムから始まります。次に、小脳システムと、その独特な形式のエラー主導型学習を紹介します。各セクションは、各システムに関連する神経生物学のレビューから始まります。
大脳基底核、行動選択と強化学習
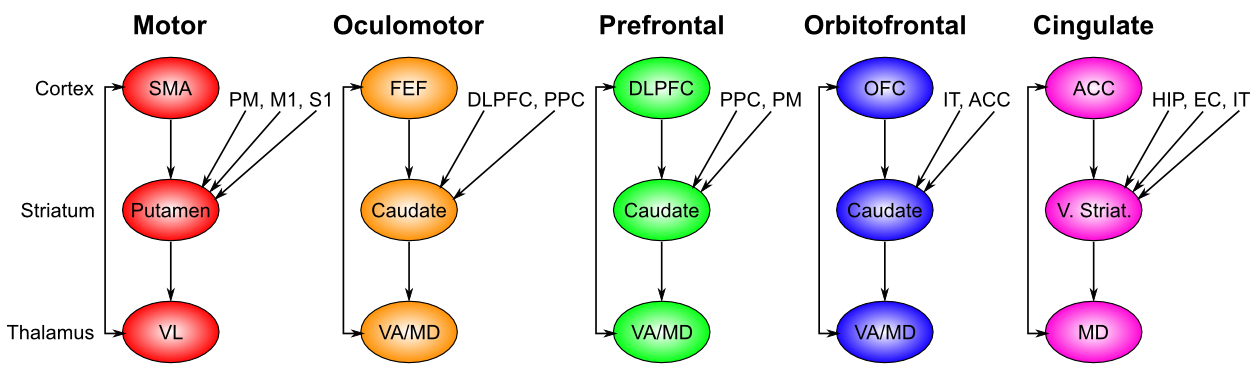
大脳基底核は、接続性 [@fig:fig-bg_loops_ads86-8] のいくつかの並列ループによって、広範囲の前頭皮質領域にわたってその動作選択機能を実行します。これらの領域には、運動 (骨格筋制御) および眼球運動 (眼球運動制御) が含まれますが、直接運動制御領域ではない前頭前野、眼窩前頭皮質、および前帯状皮質も含まれます。したがって、私たちは行動選択の概念を、認知行動選択、つまり前頭前皮質のより高次の認知領域で機能する、より抽象的な形式の選択を含めるように一般化する必要があります。たとえば、大脳基底核は前頭前野との接続において大規模な行動計画や戦略の選択を制御することができます。眼窩前頭葉皮質は、起こり得るさまざまな刺激結果に関連する報酬値をコード化するのに重要であるため、ここでの大脳基底核の接続は、環境における偶発性の関数としてこれらの表現の更新を促進するために重要です。前帯状皮質は、運動行動のコスト(時間、労力、不確実性)をコード化するのに重要であり、大脳基底核も同様に、さまざまな行動が考慮されるときにこれらのコストの更新を制御するのに役立ちます。 実行機能の章でさらに説明するように、これらのより抽象的な前頭野における大脳基底核の役割は、作業記憶の更新を制御するものであると要約できます。
興味深いことに、特定の領域の大脳基底核に集中する追加の入力はすべて理にかなっています。運動制御には、現在の体性感覚の状態と、運動前野として知られるわずかに高次の運動制御領域からの入力について知る必要があります。眼窩前頭皮質は、刺激の報酬値をエンコードすることがすべてであるため、環境内の関連するオブジェクトの識別情報を提供する IT 皮質から入力を取得する必要があります。
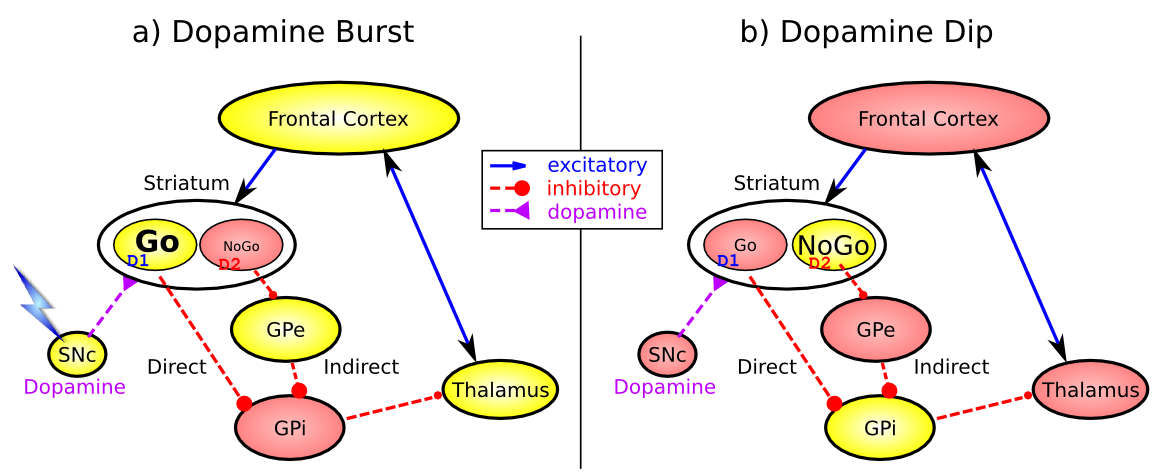
これらのループのいずれかにズームインすると、大脳基底核系の重要な要素が [@fig:fig-bg-frontal-da-burst-dip] に図示され、2 つの重要な活性化パターンが示されます。まず、大脳基底核系には次のサブ領域が含まれます。
-
線条体。主要な入力領域であり、尾状と被殻の下位区分で構成されます ([@fig:fig-bg_loops_ads86-8] に示すように)。線条体は解剖学的に多数の小さなニューロンのクラスターに細分されており、クラスターには主に パッチ/ストリオソーム と マトリックス/マトリソーム の 2 つのタイプがあります。マトリックス クラスターには 直接 (Go) および 間接 (NoGo) 経路 中棘状 ニューロンが含まれており、これらは合わせて線条体細胞の 95% を構成し、どちらも皮質全体から興奮性入力を受け取りますが、次に説明するように淡蒼球の下流の標的に対しては抑制性を示します。パッチ細胞はドーパミン作動性システムに投射するため、学習信号の調節においてより間接的な役割を果たしていると考えられます。また、顕著な結果または刺激が存在するときにその活動を一時停止することによって脱抑制調節を提供する、広範囲に配置されたコリン作動性介在ニューロン (CIN) が比較的少数存在します。
-
淡蒼球、内節 (GPi)。これは線条体よりもはるかに小さい構造であり、追加の入力がなくても常に (緊張的に) 活動しているニューロンが含まれています。これらのニューロンは、視床の特定の核に抑制を送ります。 Direct/Go 経路の線条体ニューロンが発火すると、これらの GPi ニューロンが抑制され、その結果視床が「抑制解除」され、最終的には特定の運動または認知行動 (どの回路が関与しているかに応じて) が開始されます。他の前頭大脳基底核回路では、GPi の役割は黒質網様体 (SNr) によって担われていることに注意してください。SNr は解剖学的には GPi と同じ位置にありますが、線条体の他の領域から信号を受け取り、他の動作 (たとえば、上丘での眼球運動) を調節する出力に投射されます。
-
淡蒼球、外節 (GPe)。これも小さく、対応する GPi ニューロンに集中した抑制性の投射を送信する緊張的に活動するニューロンが含まれています。線条体の間接/NoGo 経路ニューロンが発火すると、GPe ニューロンが抑制され、GPi ニューロンが脱抑制され、視床に対してさらに大きな抑制が行われます。これにより、アクティブな NoGo ニューロンの集団によってコード化された特定のアクションの開始がブロックされます。
-
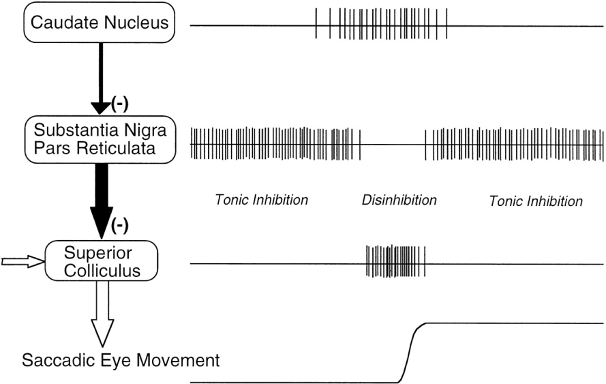
視床、具体的には内側背側 (MD)、腹側前側 (VA)、および腹外側側 (VL) 核 ([@HikosakaTakikawaKawagoe00] から [@fig:fig-hikosaka-gating] に示されているように)。視床ニューロンは、Go 経路の発火によって抑制が解除されると発火することができますが、それは前頭皮質からのトップダウンの興奮性入力によって駆動される場合に限られます。このように、大脳基底核は視床皮質回路上のゲートの役割を果たします。Go発火はゲートを開き、NoGo発火はゲートを閉じますが、ゲートを通過する情報の内容(例えば、運動行動計画の詳細など)は視床皮質系に依存します。眼球運動回路では ([@fig:fig-hikosaka-gating] に示すように、視床の役割は上丘によって担われ、そのバースト発火によって眼球運動が開始されます)。
-
黒質緻密部 (SNc) には、神経調節物質であるドーパミンを放出し、特に線条体を神経支配するニューロンがあります。興味深いことに、線条体には 2 種類の異なるドーパミン受容体が存在します。 D1 受容体は Go 経路ニューロンに広く存在しており、ドーパミンは D1 受容体を持つニューロン (特に皮質から収束するグルタミン酸作動性興奮性入力を受け取っているニューロン) に対して興奮作用を及ぼします。対照的に、D2 受容体は NoGo 経路ニューロンに広く存在しており、ドーパミンは D2 受容体を介して抑制効果を持っています。したがって、ドーパミンのバーストが線条体に到達すると、アクティブな Go ユニットがさらに興奮し、NoGo ユニットが抑制されます。この活動の変化は活動に依存した可塑性をもたらし、したがって運動および認知活動を開始する傾向の増加につながります。対照的に、ドーパミン発火のディップが発生すると、Go ニューロンの興奮が低下し、NoGo ニューロンの抑制が解除されます。そのため、皮質から興奮性入力 (現在の状態と行動を表す) を受け取った NoGo ニューロンは、ドーパミンのディップによってより興奮します。繰り返しますが、この活動の変化はシナプスの増強をもたらし、その結果、この特定の NoGo ニューロン集団は、将来この感覚状態と候補となる運動行動に遭遇した際に活動的になる可能性が高くなります。ドーパミン バーストとディップのこれらの効果はどちらも完全に理にかなっています。ドーパミン バーストは、プラスの報酬予測誤差 (報酬が予想よりも優れている場合) と関連しており、そのため、良い結果につながる行動の選択が強化されます。逆に、ドーパミンの低下は負の報酬予測エラー (予想よりも悪い) に関連しており、そのため、これらの悪い結果をもたらす傾向のある行動の回避 (NoGo) につながります。また、ドーパミンの強壮レベルは、これらの経路の活動の相対的なバランスに影響を与える可能性があるため、学習がすでに行われている場合でも、ドーパミンの変化は、行動の選択が主に学習された Go 値と学習された NoGo 値に影響されるかどうかに影響を与える可能性があります。大まかに言うと、ドーパミンが高いほど、選択のリスクが高くなります (否定的な結果に対する鈍感さ)。
-
視床下核は、大脳基底核 (図には示されていない) の主要な構成要素でもあり、第 3 の ハイパーダイレクト経路 として機能し、前頭皮質から直接入力を受け取り、線条体を完全にバイパスして興奮性投射を BG 出力 (GPi) に直接送信するため、この名前が付けられました。これらの STN-GPi 投影は拡散しています。これは、単一の STN ニューロンが多くの GPi ニューロンに広く投影することを意味します。そのため、STN は、運動または認知動作のゲート制御を防止する (技術的には、ゲート制御の閾値を上げる) グローバル NoGo 機能を提供すると考えられています。この領域は、反応抑制の要求が高まるにつれて、または代替の皮質行動計画間に矛盾がある場合に、より活性化することがモデルや経験的データで示されており、その結果、STN は線条体ゲーティングが最良の行動 [@Frank06] に落ち着くまでにより多くの時間を稼いでいます。
これはかなり複雑な回路であり、すべての部品がどのように組み合わされるかを実際に理解するには、おそらく数回の反復が必要です。それでも、肝心なことは理解しやすいはずです。大脳基底核は、前頭皮質のさまざまな領域との脱抑制ゲート関係を介して、報酬のある行動(より抽象的な認知行動を含む)を選択することを学習します。さらに、上記の一般的な描写は、計算上の考察と多くの詳細な解剖学的、生理学的、薬理学的データに基づいており、種を超えた経験的データによって圧倒的に裏付けられています。たとえば、マウスでは、D1 線条体ニューロンの選択的刺激は BG 出力核の抑制と運動活動の脱抑制をもたらしましたが、D2 線条体ニューロンの選択的刺激は出力核の興奮と運動活動の抑制をもたらしました。運動後のこれらの経路の一時的な刺激により、マウスが将来同じ運動を繰り返す可能性が高くなる (go 単位刺激) か、または低くなる (nogo 単位刺激) ことが生じ、これは学習効果 [@KravitzTyeKreitzer12] と一致します。
他の研究では、マウスが負の報酬予測エラーを経験した場合(つまり、報酬を期待していたのに報酬が得られなかった場合)、D2ニューロンが活動レベルを高めることで反応し、その程度が、その後の一定の報酬[@ZalocuskyRamakrishnanLernerEtAl16]につながるより安全な選択肢を優先して行動を回避することに関連していることが示されました。 D1 受容体と D2 受容体が 2 つの経路 [@ShenFlajoletGreengardEtAl08] におけるシナプス可塑性を逆に調節するというモデル予測の証拠もあります。さらに、Go 経路に沿った神経伝達を選択的に遮断すると、報酬となる行動を選択する学習に障害が生じたが、罰的な行動を回避することには障害が生じず、NoGo 経路 [@HikidaKimuraWadaEtAl10] の遮断後にはまったく逆のパターンの障害が観察された。ヒトでは、パーキンソン病に関連する線条体ドーパミンの枯渇により、確率的強化学習タスクにおける「Go学習」が障害されるが、「NoGo学習」が強化され、線条体ドーパミン[@FrankSeebergerOReilly04]を増加させる薬剤によって誘発される逆のパターンの所見が見られる。健康な若者の Go 学習と NoGo 学習における個人差さえも、PET 研究 [@CoxFrankLarcherEtAl15; @FrankFossella11] における線条体の D1 および D2 受容体機能と D1 対 D2 受容体の発現に影響を与える遺伝的変異と関連しています。
前頭皮質と大脳基底核の間の分業は、他の皮質領域からの豊富な接続パターンのおかげで、前頭葉皮質がさまざまな可能な行動を取り込み、現在の環境の高レベルの概要を提供し、それによってさまざまな可能な行動が活性化され、大脳基底核がこれらの行動の中から最良の (最も報酬が得られる可能性が高い) ものを選択して実際に実行します。もっと擬人化した言葉で言えば、前頭葉は曖昧でクリエイティブなタイプで、100万ものアイデアを持っていますが、現実世界に集中する能力がなく、実際に何かをするところまで物事を絞り込むのが苦手で、一種の夢想家です。一方、大脳基底核は真の責任者タイプで、常に最終的なことを念頭に置き、難しい決断を下して物事をやり遂げることができます。私たちの頭の中にこれらの性格の両方が必要です(ただし、それぞれの性格をどの程度持っているかは人によって明らかに異なります)。そして、これらの異なる行動様式をサポートする神経システムは明らかに異なります。おそらくこれが、2 つの分離可能なシステム (前頭皮質と大脳基底核) がありながら、全体的な行動選択の問題を解決するために非常に緊密に連携している理由と考えられます。
大脳基底核の探索
CCNシムズ から bg シミュレーションを開いて、大脳基底核における go vs nogo アクション選択と学習ダイナミクスの基本モデルを調査します。このモデルを使用すると、パーキンソン病とドーパミン作動薬の影響を調査することもできます。
ドーパミンと時間差の強化学習
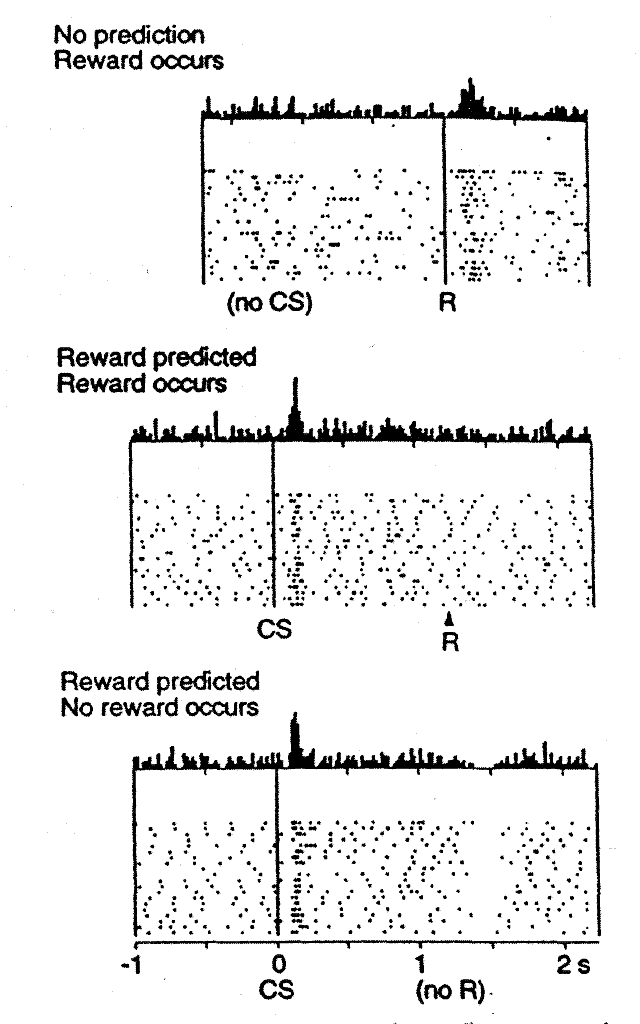
ドーパミンの位相的(強壮的ではなくバースト的なという意味)変化がどのようにGoとNoGoの学習を促進して、最もやりがいのある行動を選択し、あまりやりがいのない行動を避けることができるかについては上記で考察しましたが、ドーパミンニューロンが学習を促進するためのこれらの位相信号をどのように表現するようになるかについては触れていませんでした。近年の最も刺激的な発見の 1 つは、腹側被蓋野 (VTA) と黒質緻密部 (SNc) のドーパミン ニューロンが、報酬予測誤差に基づく強化学習モデルに従って動作するという発見でした。いくつかの一般的な誤解とは異なり、これらのドーパミン ニューロンは生の報酬値を直接エンコードしません。代わりに、受け取った報酬と報酬の期待との「差」をエンコードします。これは [@fig:fig-schultz97-vta-td] [@SchultzDayanMontague97] に示されています。報酬の期待がない場合、ドーパミン ニューロンは報酬に向かって発火し、正の報酬予測誤差 (期待ゼロ、正の報酬) を反映します。条件刺激(CS、例:音や光)が次の報酬を確実に予測する場合、報酬予測誤差(期待 = 報酬)の欠如を反映して、ニューロンはもはや報酬自体に発火しません。代わりに、ドーパミンニューロンが発火してCSが始まります。 CS の後に報酬が省略された場合、ドーパミン ニューロンは実際には別の方向に進み (そうでなければドーパミン ニューロン発火の持続性レベルが低い「落ち込み」または「一時停止」)、負の報酬予測誤差 (正の報酬予測、報酬ゼロ) を反映します。
計算上、報酬予測誤差の最も単純なモデルは Rescorla-Wagner 条件付けモデル [@RescorlaWagner72] です。これは、学習 の章で説明した デルタ ルールと数学的に同一であり、実際の報酬と期待される報酬の差にすぎません。 \(\delta = r - \hat{r}\) \(\delta = r - \sum x w\) ここで、$\delta$ (「デルタ」) は報酬予測誤差、r は実際に受け取った報酬の量、$\hat{r}=\sum x w$ は報酬の 期待 量で、重み w を持つ入力刺激 x の重み付き合計として計算されます。重みは実際の報酬値を正確に予測するように適応され、実際、このデルタ値は重みが変化する方向を指定します。 \(\Delta w = \delta x\)
これは、刺激アクティビティ x への重要な依存性を含め、デルタ学習ルールと同じです。実際に存在する刺激 (つまり、ゼロ以外の x) の重みのみを変更する必要があります。
報酬予測が正しい場合、[@fig:fig-schultz97-vta-td] の 2 番目のパネルに示すように、実際の報酬値は予測によって 相殺されます。このルールは、図に示されている他のケース (正および負の報酬予測誤差) も正確に予測します。
Rescorla-Wagner モデルが捉えていないのは、[@fig:fig-schultz97-vta-td] の 2 番目のパネルにある CS の開始までのドーパミンの発火です。ただし、時間差 (TD) 学習ルールとして知られるもう少し複雑なモデルは、(名前が示すように) [@SuttonBarto81; @SuttonBarto98] の方程式に時間を導入することで、この CS 発症の発火を捕捉します。 Rescorla-Wagner と比較して、TD はデルタ方程式に 1 つの追加項を追加するだけで、後で来る可能性のある 将来 の報酬値を表します。 \(\delta = (r + f) - \hat{r}\) ここで f は将来の報酬を表し、報酬期待値 $\hat{r}=\sum x w$ は現在の報酬 r とこの将来の報酬 f の両方を予測する必要があります。 CS がその後の報酬を確実に予測する単純な条件付けタスクでは、CS が到着すると、近い将来に報酬が得られる可能性が高いため、CS の開始により f 値が増加します。さらに、CS の開始は以前のどの合図によっても予測されないため、この f 自体は予測可能ではありません (もし予測できた場合、その初期の合図が実際の CS であり、ドーパミン バーストを駆動することになります)。したがって、r-hat の期待値は f 値を打ち消すことができず、ドーパミンのバーストが発生します。
この f 値はCS開始時のドーパミン発火を説明していますが、システムは将来どのような報酬が得られるかをどのようにして知ることができるのでしょうか?という疑問が生じます。未来に関係するものと同様に、基本的には、可能な限り過去をガイドとして使用して、推測する必要があります。 TD は、報酬推定値の長期にわたる一貫性を確保することによってこれを実現します。実際には、時間 t での推定値は、時間 t+1 での推定値のトレーニングに使用されるなど、時間の経過とともにすべての一貫性を可能な限り維持し、時間の経過とともに受け取られる実際の報酬との一貫性が保たれます。
これはすべて、現在と将来のすべての報酬の合計である 値関数 V(t) を指定することによって、非常に満足のいく方法で導出できます。将来の報酬は「ガンマ」係数で 割引されます。これは、将来の報酬は、より早く発生する報酬よりも価値が低いという直感的な概念を捉えています。ポパイの中でウィンピーのキャラクターが言うように、「今日のハンバーガーの代金は火曜日に喜んで払います。」これは、将来に向かう無限和である値関数です。 \(V(t) = \left. r(t) + \gamma^1 r(t+1) + \gamma^2 r(t+2) ... \right.\) この方程式を再帰的に書くことで無限大を取り除くことができます。 \(V(t) = \left. r(t) + \gamma V(t+1) \right.\) そして、確かなことは何も分からないため、これらの値の用語はすべて実際には推定値であり、その上の小さな「帽子」で示されています。 \(\hat{V}(t) = r(t) + \gamma \hat{V}(t+1)\)
したがって、この方程式は、時刻 t+1 における将来の推定値に関して、現在の時刻 t における推定値がどのようになるべきかを示します。次に、両辺から V ハットを差し引きます。これにより、上記の等式を別の方法で表現する式が得られます。つまり、これらの項の差はゼロに等しくなるはずです。 \(0 = \left( r(t) + \gamma \hat{V}(t+1) \right) - \hat{V}(t)\)
これは、TD が時間の経過とともに推定値の一貫性を維持しようとする点を数学的に示しています。つまり、推定値の差はゼロである必要があります。しかし、V ハットの推定値を学習しているとき、この差は「ゼロ」ではなく、実際、ゼロではない程度が、報酬予測誤差の程度となります。 \(\delta = \left( r(t) + \gamma \hat{V}(t+1) \right) - \hat{V}(t)\) これを上記の f を含む方程式と比較すると、次のことがわかります。 \(f = \gamma \hat{V}(t+1)\) すべての変数の時間依存性を明確にし、報酬の期待値が代わりに「値の期待値」になったことを除いて、他のすべては同じです (r ハットを V ハットに置き換えます)。また、Rescorla-Wagner と同様に、ここでのデルタ値は値の期待値の学習を促進します。
TD 学習ルールは、多数のさまざまな条件付け現象を説明するために使用でき、脳内のドーパミン ニューロンの発火との適合性により、多くの研究が進歩しました。これは、脳機能を理解 (および予測) するための計算モデリング アプローチの真の勝利を表しています。
TD 学習の探求
シンプルな条件付けパラダイムにおける TD ベースの強化学習を調べるために、CCNシムズ から rl シミュレーションを開きます。この探求は、強化学習、報酬予測誤差、および単純な古典的条件付けについての理解を確実にするのに役立ちます。
運動学習のためのアクターと批評のアーキテクチャ
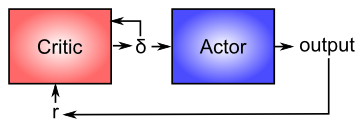
ドーパミンがどのように機能するかについてよりよく理解できたので、大脳基底核における学習の調節におけるドーパミンの役割を再検討します ([@fig:fig-bg-frontal-da-burst-dip] に示すように)。計算上の観点から見ると、重要な考え方は 俳優と批評家 ([@fig:fig-actor-critic-basic]) の区別であり、報酬は少なくとも部分的に俳優による正しいパフォーマンスから得られると想定されています。この場合、大脳基底核は俳優であり、ドーパミン信号は批評家の出力であり、それが俳優 (先ほど見たように批評家も) のトレーニング信号として機能します。ドーパミン システムによって生成される報酬予測誤差信号は、報酬がより予測不可能であるスキル習得プロセスの初期に強力な学習を促進し、スキルが完成するにつれて学習が減少し、報酬がより予測可能になるため、優れたトレーニング信号です。代わりにシステムが外部報酬に基づいて直接学習した場合、長い間習得されてきたスキルについて学習し続けることになり、これは多くの悪い結果 (シナプスの重みがますます強くなる、他の新しい学習への干渉など) を引き起こす可能性があります。
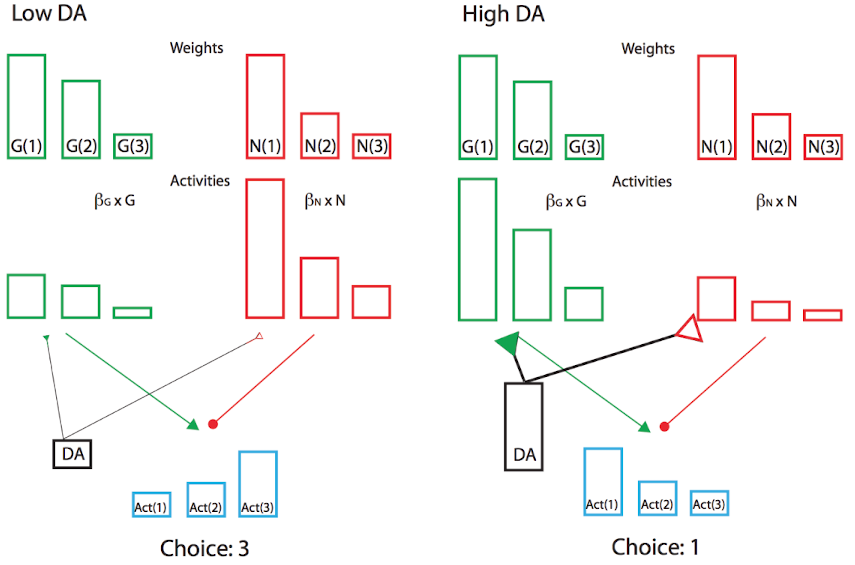
さらに、上記の BG モデル プロジェクトで見たように、報酬予測誤差の符号は、線条体の Go および NoGo 経路に対するドーパミンの効果に適切です。予期せぬ報酬が受け取られた場合の正の報酬予測エラーは、選択されたアクションが予想よりも優れていたことを示しており、そのため、将来的にはそのアクションに対する Go の発火が増加するはずです。これらの Go ニューロン上のドーパミンによって引き起こされる活性化の増加は、学習がこれらの活性化レベルによって駆動されると仮定すると、この効果をもたらします。逆に、負の報酬予測エラーは NoGo の発火を促進し、システムが将来そのアクションを回避する原因になります。実際、BG Go/NoGo 回路の複雑なニューラル ネットワーク モデルは、相手アクター学習 (OpAL; [@fig:fig-bg-opal-hilow]) と呼ばれる修正されたアクター-クリティカル アーキテクチャでのより正式な分析によって簡素化できます。この場合、アクターは独立した G と N の対戦相手の重みに分割され、それらの相対的な寄与自体が、学習中と選択中のドーパミン レベルによって影響されます [@CollinsFrank14]。
最後に、ドーパミン信号が時間的に逆方向に伝播する能力は、運動動作とそれに続く報酬の間の避けられない遅延に対処するために重要です。具体的には、ドーパミン反応は、古典的な条件付けパラダイムでCSの開始に時間的に移行するのと同じように、報酬の時点から報酬を確実に予測する行動の時点に移行する必要があります。
ドーパミン生物学の PVLV モデル
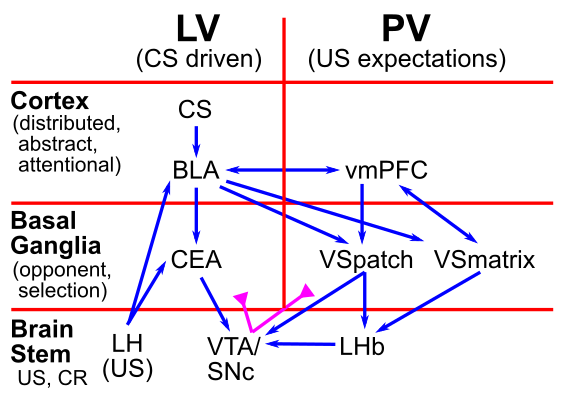
お気づきかもしれませんが、VTA と SNc のドーパミン ニューロンが実際にどのようにして報酬予測誤差の発火を示すようになるのか、生物学的レベルではまだ説明されていません。 [@fig:fig-pvlv] に示されているように、比較的多数の異なる脳領域の関与を裏付けるデータが増えています。 PVLV モデルは、これらのさまざまな脳領域がそれぞれ、TD 学習ルールによってより抽象的なレベルで前述した一時的なドーパミン発火にどのように寄与するかを示す計算フレームワークを提供します。
PVLV は、これらの領域を PV (Primary Value) と LV (Learned Value) という 2 つの全体的なシステムに編成します。これは、CS の発症時の段階的ドーパミン発火の駆動に関与する脳システム (LV システム) と、その後の US の予測に関与する脳システム (PV システム) に異なる脳システムが関与しているという証拠と一致しています。
基底外側扁桃体 (BLA) は、LV システムの中核要素です。 それは、皮質および他の皮質下感覚経路からの広範な感覚入力と、視床下部外側部 (LH) からの US コーディング入力を受け取ることによって、CS 感覚入力をその後の US 結果と関連付けることを学習します。 LH は、食物、水などの主要な報酬信号の主要な供給源です。
腹側線条体 (VS) のニューロン集団は、VTA および SNc のドーパミン (DA) ニューロンを直接阻害する能力により、PV システムの中心となっており、それによって DA の発火を予測された US 結果に迂回させることができます。 さらに、VS は、予期された報酬が受け取られない場合 (およびネガティブな US が受け取られた場合) に、DA 発火の位相低下/一時停止の主な原因となる重要な中脳核である 外側手綱核 (LHb) に投射します。
より抽象的な数学用語では、PVLV の PV コンポーネントは、変数に異なるラベルを使用しているだけで、Rescorla-Wagner と同じです。 \(\delta_{pv} = r - \hat{r}\) \(\delta_{pv} = US - PV\)
$PV$ 値は、このデルタを反映するドーパミン信号に基づいて、デルタ ルールまたは Rescorla-Wagner と同じ方法で学習されます。 重要なのは、これらの PV 値が US 信号の前にアクティブになると、将来はアクティブにならないことを学習するため、以前の CS に応答できなくなることです。
LV システムも PV システムと同様の方法で学習します。 \(\delta_{lv} = US - LV\)
しかし、PV システムとは異なり、LV システムは CS 発症時に起動することができ、US 発症時に一次学習を経験します。
PVLV システムの学習制約には興味深い特性が多数あります。たとえば、$LV$ システムがそれについて学習し、BLA が直接 CS と US の関連付けを形成できるようにするには、外部報酬の時点で CS がまだアクティブである必要があります。 したがって、CS 自体が停止した場合でも、CS の記憶がある程度保持されなければなりません。これは、条件付けパラダイム (トレース 条件付けとして知られる) における CS 学習の既知の制約によく適合します。 PVLV フレームワーク [@MollickHazyKruegerEtAl20; @HazyFrankOReilly10; @OReillyFrankHazyEtAl07] と一致する、学習に関連する条件付き刺激と無条件刺激の違いに関する具体的なデータが豊富にあります。
つまり、PVLV システムは、さまざまな生物学的システムが報酬関連の関数としての一過性ドーパミン反応の生成にどのように関与しているかを、システム上のやや特殊な制約に適合すると思われる方法で説明できます。また、実行機能 の章では、PVLV が前頭前皮質の作業記憶システムにおける大脳基底核の役割を制御するためのよりクリーンな学習信号を提供することがわかります。
PVLVの探索
CCNシムズ で pvlv シミュレーションを開きます。これにより、TD モデルで検討したものと同じ条件付けパラダイムが実行されます。
小脳とエラー駆動学習
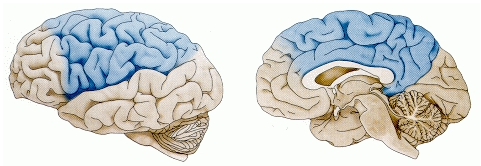
大脳基底核が強化学習に基づいて実行するアクションをどのように選択できるかが理解できたので、次は小脳に注目します。小脳は、アクションが開始されると引き継ぎ、エラー駆動学習を使用して、アクションのパフォーマンスを正確で適切に調整されるように形成します。 [@fig:fig-cerebellum-cortex-inputs] に示すように、小脳は、頭頂皮質や前頭皮質の運動野など、運動生成に直接関与する皮質領域からのみ情報を受け取ります。大脳基底核とは異なり、前頭前野や側頭葉皮質からは受信しませんが、それぞれの機能に応じて意味があります。前頭前野と側頭葉皮質は、高度な計画と行動の選択には非常に重要ですが、行動の実行には重要ではありません。しかし、神経画像実験から、小脳が多くの認知タスクに従事していることがわかっています。これは、小脳と頭頂皮質との広範な接続を反映しているに違いありません。頭頂皮質は、多くの認知タスクでも活性化されています。 1 つのアイデアは、小脳がその強力なエラー駆動型学習メカニズムのおかげで、頭頂皮質における学習と処理の形成を助けることができるというものです。これは、頭頂皮質が行うすべての複雑な動作をどのように学習できるかを説明するのに役立つかもしれません。しかし、現時点では、頭頂皮質と小脳はどちらも、認知的な観点よりも運動的な観点からはるかによく理解されています。
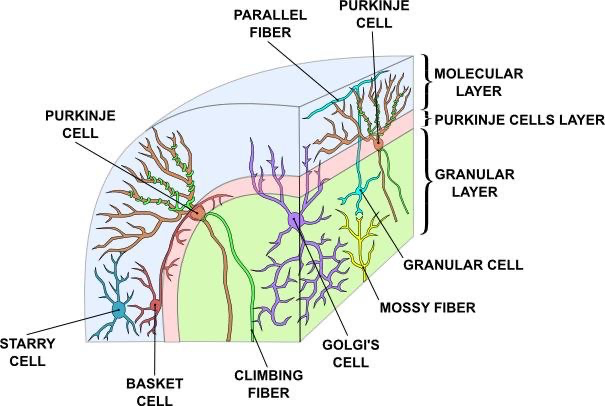
小脳は非常に明確に定義された解剖学的構造 ([@fig:fig-cerebellum]) を持ち、同じ基本回路が全体にわたって複製されています。したがって、大脳基底核と同様に、広範な異なる内容領域(例えば、異なる運動効果器、および頭頂葉皮質および前頭葉皮質の異なる領域)にわたって複製された同じ基本機能を実行していると思われる。基本的な回路には、さまざまなソースからの入力信号が含まれており、苔状線維軸索を介して小脳に伝達されます。これらは 顆粒細胞 で終わります。その細胞は人間の脳におよそ 400 億個あります。各顆粒細胞は 4 ~ 5 個の苔状線維入力のみを受け取りますが、約 2 億本の苔状線維入力があり、各苔状線維は約 500 個の顆粒細胞とシナプスを形成します。したがって、入力に比べて顆粒細胞内の情報コーディングが大幅に拡張されています。この重要な事実については後ほど再検討します。回路を完成させるために、顆粒細胞は 平行線維 軸索を送り出し、プルキンエ細胞の非常に密な樹状突起にシナプスを形成し、顆粒細胞から 200,000 もの入力を受け取ることができます。人間の脳には約 1,500 万個のプルキンエ細胞があり、これらの細胞は小脳からの出力信号を生成します。したがって、顆粒細胞からプルキンエ細胞への大規模な収束操作が行われます。プルキンエ細胞は強壮的に活動しており、顆粒細胞はプルキンエ細胞に対して興奮性であるため、顆粒細胞がどのように有用なシグナルをプルキンエ細胞に伝えるのかを理解するのは少し不可解です。小脳の他の細胞タイプ (星状細胞、バスケット細胞、ゴルジ細胞) は、顆粒細胞とプルキンエ細胞の両方の発火を抑制的に制御する抑制性介在ニューロンです。顆粒細胞がこれらの抑制性細胞と協力してプルキンエ細胞の興奮と抑制のバランスを変化させる可能性がありますが、これについてはまだ不明瞭です。
小脳パズルの最後のピースは、下オリーブ核からの登攀線維入力です。このような登攀線維はプルキンエ細胞ごとに1本だけあり、ニューロンに非常に強力な影響を及ぼし、一連の複雑なスパイクを生成します。登攀線維入力はプルキンエ線にトレーニング信号またはエラー信号を伝え、それが関連する顆粒細胞入力におけるシナプス可塑性を駆動すると考えられています。 1 つの顕著なアイデアは、このシナプス可塑性が顆粒細胞が活動しているシナプス入力の LTD (重量減少) を引き起こす傾向があり、その結果、これらのニューロンが将来プルキンエ細胞を発火する可能性が低くなるというものです。プルキンエ細胞が 深部小脳核 ニューロンを抑制していることを考えると、これは理にかなっています。そのため、プルキンエ細胞から出力を生成するには、プルキンエ細胞をオフにする必要があります。
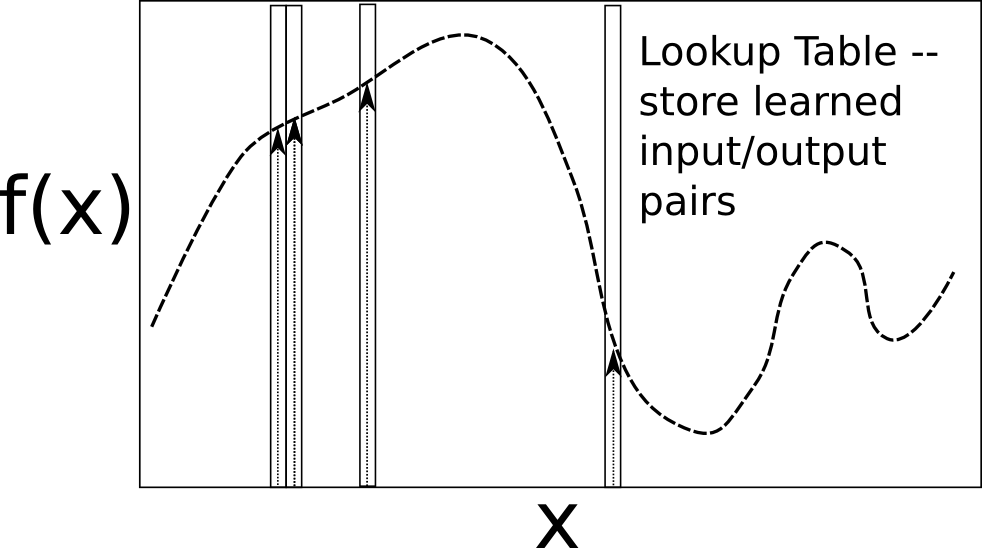
これらすべての断片をまとめると、デビッド マー [@Marr69] とジェームス アルバス [@Albus71] は、小脳は誤差信号が登坂繊維から来る、誤差駆動学習のシステムであると主張しました。登攀繊維入力の命令の下で、刺激入力をモーター出力コマンドに関連付ける機械を備えていることは明らかです。小脳機能の重要な原理の 1 つは、顆粒細胞上の非常に高次元の空間への入力の投影です。これにより、計算的には「分離」形式の学習が実現され、入力の各組み合わせが顆粒細胞ニューロンの固有のパターンを活性化します。この独特のパターンは、小脳からの異なる出力信号と関連付けられ、入出力値の ルックアップ テーブル に近似したものを生成します ([@fig:fig-lookup-table-function-approximator])。ルックアップ テーブルは、非常に複雑な任意の関数を学習するための堅牢なソリューションを提供します。ルックアップ テーブルは、常にあらゆる種類の関数をエンコードできます。欠点は、新しい入力パターンにあまりうまく一般化できないことです。ただし、モータ制御においては、何らかの形で一般化して効率を高めるよりも、不適切な一般化を避ける方が全体的には良い場合があります。この高次元拡張は、最も成功した機械学習アルゴリズムの 1 つであるサポート ベクター マシン (SVM) でもうまく使用されています。
小脳の探索
運動学習の CCNシムズ で cereb モデルを開きます。