compcogneuro/book: 言語
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/book/blob/main/chapter-10.md
ライセンス: CC BY 4.0。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
bibfile: ccnlab.bib —
言語
本文の他の章で説明されているように、言語は脳のほぼすべての部分に関係します。
-
知覚と注意: 言語には、聴覚の音波と書かれたテキストからの単語の認識が必要です。ページ上の個々の単語や、混雑した部屋で個々の発言者を引き出すには、注意力が非常に重要です。この章では、知覚の章のオブジェクト認識モデルのバージョンが、特にこのモデルの空間不変特性を活用した方法で、書き言葉認識をどのように実行できるかを見ていきます。
-
運動制御: 言語の生成には、発話や筆記などの形での運動出力が必要であることは明らかです。流暢な発話は無傷の小脳に依存し、大脳基底核は多くの言語現象に関与していると考えられています。
-
学習と記憶: 初期の単語学習は海馬のエピソード記憶に依存している可能性が高く、単語の意味の長期記憶は皮質の遅い統合学習に依存しています。最近の談話や読書の話題(小説を読む場合は数か月に及ぶこともある)の記憶には、海馬と側頭皮質の洗練された意味表現が関与している可能性が高い。
-
実行機能: 言語は、前頭前野 (PFC) と大脳基底核からの調整と作業記憶に大きく依存する複雑な精神機能です。たとえば、時間の経過に伴う構文構造のエンコード、代名詞の結合、その他のより一時的な形式の記憶です。
このことから、言語は特別なものではなく、領域一般 認知メカニズムの自然な特殊化を表していると結論付けることができます。もちろん、人間は他の霊長類種にはない、音声を生成するための特殊な調音装置を持っていますが、これに加えて、既存の認知脳構造に感染する言語にすぎないと主張する人もいるでしょう。確かに、読み書きは、それをサポートするための進化的適応をするにはあまりにも最近のことです(しかし、それは、人間が話し言葉を本質的に自動的に吸収する方法と比較して、明確な学校教育を必要とする、言語の最も「自然」でない側面でもあります)。
しかし、言語は、いくつかの重要な点で他の認知活動とは根本的に異なります。
-
シンボル — 言語は、思考を一連のシンボルに還元し、時空を超えて運ばれ、受信者の脳内で再構築されることを必要とします。
-
構文 — 言語は、単語と文字/音素の順序において複雑で抽象的な規則に従います。
-
時間的広がりと複雑さ — 言語は非常に長い時間枠にわたって展開することができ (例: トルストイの 戦争と平和)、言語環境の外で生じる可能性のある自然発生的な経験をはるかに超える複雑さと豊かさのレベルが伝えられます。飛行機の中で音なしで映画を観ていることに気づいたら、視覚的なイメージがほとんどの映画の内容 (とにかく興味深いもの) の下半分を表していることが分かるでしょう。
-
生成性 — 言語は、構築できる異なる文の数が非常に多く、事実上無限であるという意味で「無限」です。言語は新しいアイデアを表現するために日常的に使用されます。ここでそれらのいくつかを見つけることができるかもしれません。
-
文化 — 私たちの知性の多くは文化的伝達、言語を通じて伝えられます。このように、言語は脳の認知を深く形成します。
言語の「特別な」性質と、その言語のドメイン一般メカニズムへの依存は、さまざまな研究者が採用する一連のアプローチの 2 つの極を表します。この幅広い範囲内には、論争や矛盾する意見が存在する余地がたくさんあります。ノーム・チョムスキーは、私たちは皆、生得的に普遍的な文法を持って生まれており、言語学習はその言語インスタンスの特定のパラメータを発見することに等しい、という有名かつ影響力のある理論を立てました。対極として、ジェイ・マクレランドのようなコネクショニスト言語モデラーは、言語に関する特別なこと(の少なくとも一部)を説明するには、完全に構造化されていない一般的な神経機構(例:逆伝播ネットワーク)で十分であると主張しています。
他の幅広い認知現象を探索するために使用されるのと同じ汎用の神経メカニズムがここで言語に適用されていることを考えると、私たちの全体的なアプローチは明らかにドメイン一般的なアプローチに基づいています。しかし、私たちはまた、PFC / 大脳基底核システムの特定の機能が、記号的構文処理において特別な役割を果たしているとも考えています。現時点では、これらの特別な貢献についてはここでは簡単に触れているだけであり、実行機能の章でもう少し詳しく説明されていますが、将来の計画ではさらに詳しく説明する必要があります。これらの特別な貢献を示すヒントの 1 つは、サルの前頭皮質で発見された ミラー ニューロン から来ています。この領域は、人間のブローカ野に類似していると考えられています。これらのニューロンは、他の人 (またはサル) が実行する行動の意図をコード化しているようで、したがって、他の人が何を伝えようとしているかを理解するための重要な能力を構成している可能性があります。
私たちはいつものように、特に重要な脳領域と音声の生物学の観点から、言語に対する生物学的な基礎から始めます。次に、意味論的知識の性質について考えます。潜在意味分析 (LSA) モデルで開発されたように、自己組織化モデル (知覚と注意 章の V1 受容野モデルなど) が単語の共起統計の観点から単語の意味をどのようにエンコードできるかを見ていきます。 知覚と注意 章のオブジェクト認識モデルに基づいて、大規模な読書モデルを検討します。このモデルは、書き言葉 (正書法) を言葉の話し言葉の運動出力 (音韻論) にマッピングし、英語の約 3,000 の単音節単語を発音し、この知識を非単語に一般化することができます。次に、意味論、正書法、音韻論を組み合わせたモデルを探索し、さまざまな領域の損傷が後天性失読症の独特のパターンをどのように引き起こすかを示します。最後に、文ゲシュタルト モデルの文レベルで構文を調査します。ここでは、構文情報と意味情報が時間の経過とともに統合され、文の意味の理解のような「ゲシュタルト」が形成されます。
言語の生物学
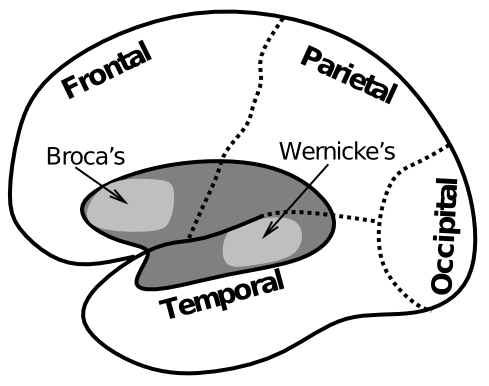
言語に関する古典的な「教科書」の脳領域は ブローカ 野と ウェルニッケ 野 ([@fig:fig-aphasia-areas]) で、それぞれ構文と意味論に関連付けられています。たとえば、脳卒中やその他のウェルニッケ野損傷を受けた人は、本質的に意味のない、流暢で構文的に正しい音声を発することができます。以下に一例を示します。
「あのスムードルがピンク色になったのは知ってるでしょう、私は彼を丸め込んで、以前のように彼の世話をしたいと思っています。」
これは明らかに、「犬が外出する必要があるので、散歩に連れて行きます」という意味を意図していたようです。
対照的に、ブローカ野に損傷がある人は、構文的に正しい音声出力を生成することが困難であり、通常は、「犬…歩く」など、何らかの努力を払って単一の内容の単語を生成します。
ブローカ失語症のより現代的な用語は 表現性失語 であり、言語を表現する際の主な欠陥を示します。通常、理解力は損なわれていませんが、興味深いことに、より構文的に複雑な文の理解に欠陥が生じる可能性があります。ウェルニッケ失語症は 受容性失語 として知られており、理解だけでなく意味の表現にも欠陥があることを示します。
生物学的に、これらの失語症に関連する損傷の位置は、これらの領域についてより一般的に知られている内容と一致しています。ブローカ野として知られる前頭皮質の腹側後部(ブロードマン野44および45に相当)は、口の制御に関連する一次運動野に隣接しているため、音声出力のための補足運動野を表します。ブローカ病患者は、口やその他の調音系を物理的に動かすことはできますが、滑らかな音声を生成するために必要なこれらの運動コマンドの複雑な順序付けを実行することはできません。興味深いことに、これらの高次の運動制御領域は、構文処理、さらには理解にとっても重要であるようです。これは、前頭葉が前方に移動するにつれてますます複雑な計画に従って、時間的に拡張された行動のパターン化に重要であるという考えと一致しています。
側頭葉が物体やその他のものの意味論的な意味を表すことがわかっていることを考えると、側頭葉におけるウェルニッケ野の位置は理にかなっています。
これらの失語症のそれぞれを引き起こすために必要な損傷の正確な性質についてはまだいくつかの議論がありますが(おそらく人によってかなりの個人差があるでしょう)、これらの広範な領域間の基本的な区別は依然として非常に有効です。
調音装置と音韻論
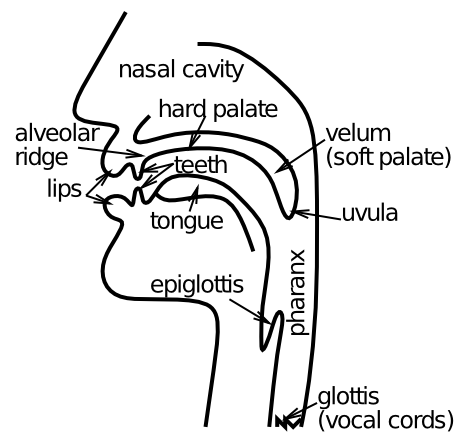
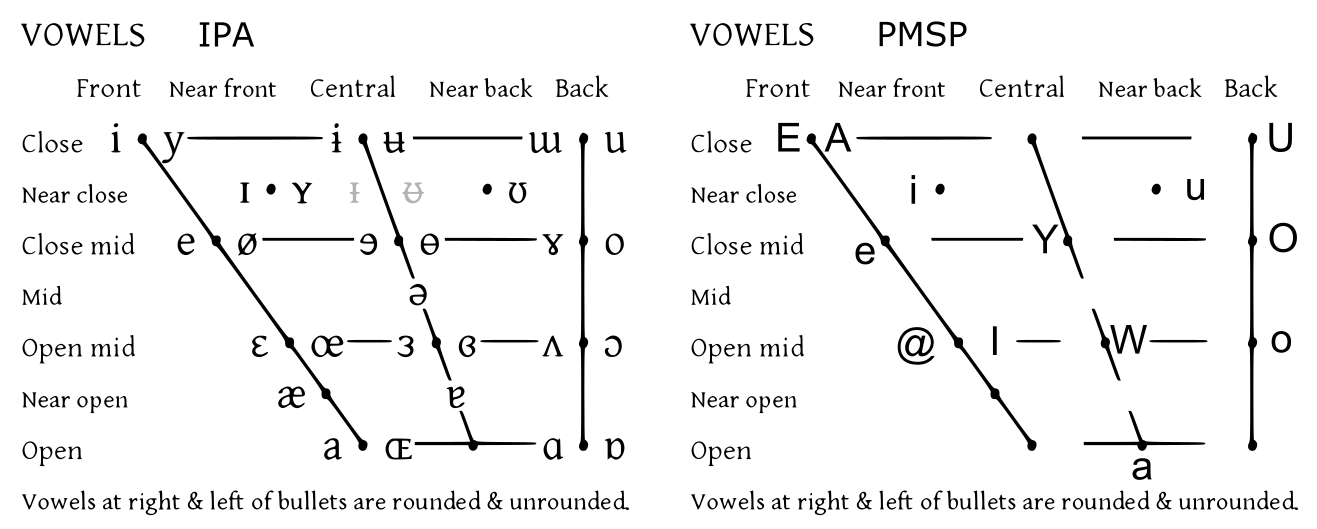
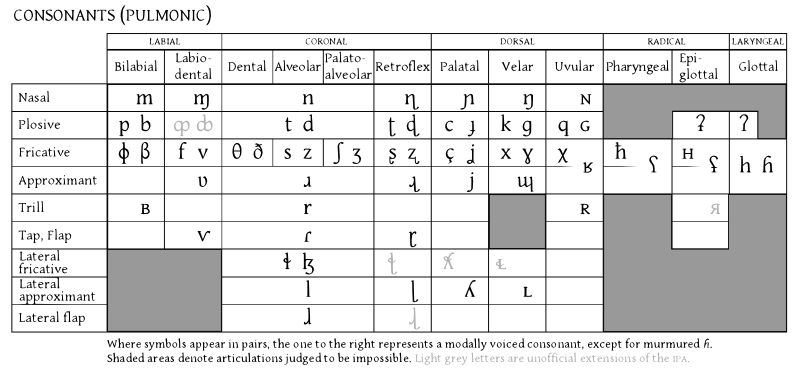
人の声道 ([@fig:fig-vocal-tract]) は、音波を遮断または通過させる位置と方法を制御することにより、広範囲の異なる音声を生成することができます。音声には、母音と子音という 2 つの基本的なカテゴリがあります。母音は空気の流れが妨げられない状態で発声され(母音を長時間歌うことができます)、舌と唇の位置が異なります([@fig:fig-ipa-chart-vowels-ipa-pmsp])。たとえば、「seen」のような長母音「E」は、舌を前に出し、唇を比較的閉じて発音します。子音は、さまざまな場所で、さまざまな方法で気流の遮断に関与します ([@fig:fig-ipa-chart-consonants-simple])。 「s」子音は、舌を唇の尾根に置く「摩擦音」(摩擦のような音の妨害)です。また、無声音でもあり、これは声帯が振動していないことを意味します。「z」の音は、有声音であることを除けば「s」と同じです。
発声時の舌の動きのビデオを見るには、この YouTube リンク を参照してください。
詳細な読解モデルの出力でこれらの音韻特徴を利用します。これらの特徴を使用すると、スペルと音の対応が実際に英語の実際の音韻構造を (少なくともかなり抽象的なレベルで) 捕捉することが保証されます。 Frank Guenther によって開発された音声出力のより詳細なモーター モデルは、いつか私たちのモデルに含めたいと考えています。ここ で見つけることができます。
Word の共起における潜在意味論
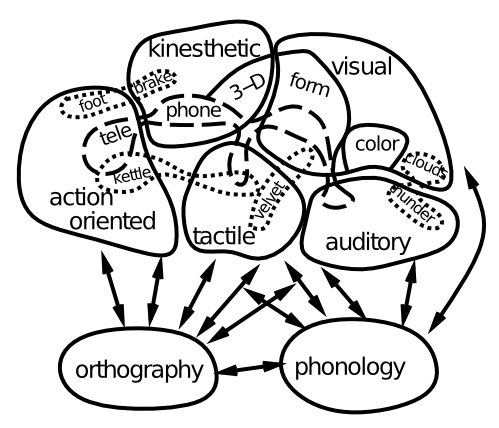
私たちが調査する最初の言語モデルは、セマンティクスに焦点を当てています。単語の意味をエンコードする意味表現の性質は何ですか? [@fig:fig-distrib-sem] で示されたアイデアは、増加するデータによって裏付けられています。つまり、具体的な単語の意味は、感覚情報と運動情報を処理するドメイン固有の脳領域内の活動パターンによってコード化されます。したがって、意味論は脳の広い範囲に分布しており、基本的には私たちが人生で最初に獲得する感覚運動原始に「具体化」され、「基礎付け」られています。したがって、三角形モデルで後ほど示される単一の「意味論」領域は、脳内の意味論的意味が実際に広く分散している性質に比べて大幅に単純化されたものです。
しかし、側頭葉の前端または「極」が、意味論的な情報を表現する上で特に重要な役割を果たしているという証拠も増えており、おそらく最も重要なのは、強い感覚や運動の相関関係を持たないより抽象的な単語の場合です。 1 つの理論は、この領域が、分散されている意味情報 [@PattersonNestorRogers07] を調整するための中央の「ハブ」として機能するというものです。
そもそも、これらのより抽象的な言葉の意味をどうやって学ぶのでしょうか? [@fig:fig-distrib-sem] で示されるより具体的な単語とは異なり、より抽象的な単語の意味は、そう簡単に感覚領域や運動領域に押しやられることはありません。ここでの説得力のあるアイデアの 1 つは、単語はその意味を、部分的にはその単語を保持する仲間から得ているということです。私たちがさらされている大量の言語入力全体にわたる単語の共起の統計は、実際に、さまざまな単語が何を意味するのかについての手がかりを提供する可能性があります。このアイデアを機能するモデルに取り込むための成功したアプローチの 1 つは、潜在意味分析 (LSA) [@LandauerDumais97] と呼ばれます。詳細とこのモデルへのアクセスについては、LSA ウェブサイト を参照してください。
LSA は、意味的に関連するテキストの塊 (通常は段落) 内で単語が互いに共起する頻度の統計を記録することによって機能します。ただし、これらの表面統計自体は十分ではありません。たとえば、単語の同義語が一緒に出現することは、それらがどの程度密接に関連している必要があるかに比べて比較的まれであるためです。そして一般に、単語の選択には多くのばらつきがあり、単語の選択の特異性がこれらの詳細な統計に反映されています。この問題に対処するために LSA が行う重要なステップは、特異値分解 (SVD) と呼ばれる 次元削減 手法を適用することです。これは *主成分分析 * (PCA) と密接に関連しており、さらにニューラル ネットワーク モデルが実行するヘビアン自己組織化学習と密接に関連しています。
この SVD/PCA/Hebbian プロセスの主な結果は、部分的に重複する単語グループの多くのサブセットを統合する方法で、同時に出現する単語の 最強のグループ またはクラスターを抽出することです。したがって、同義語は互いに出現する傾向はありませんが、他の同じ単語のセットの多くと同時出現します。この単語のグループ全体は、次元削減/ヘビアン自己組織化学習プロセスによって引き出される強力な統計的グループ化を表します。
このプロセスは、知覚と注意 の章で V1 受容野モデルで見たものとまったく同じです。このモデルでは、ヘビアン学習により、一連の自然画像から方向付けされたエッジの統計的規則性が抽出されました。通常、特定の画像には、おそらく数ピクセルが隠れたり、ぼやけたり、歪んだりした、方向性のあるエッジのノイズの多い部分バージョンが含まれています。ただし、自己組織化学習プロセスがそのような多くの入力を統合するにつれて、これらの特異性は洗い流され、特徴の最も強力な統計的グループが指向性エッジとして現れます。
ただし、V1 モデルとは異なり、LSA モデル (ヘビアン バージョンを含む) から生成される個々の統計クラスターには、「指向性エッジ」に相当する明確な解釈がありません。探索中にわかるように、通常、単語の小さなサブセットについてはある程度の意味を理解できますが、全体的な意味の要素は明らかではありません。しかし、これは問題ではありません。本当に重要なのは、セマンティック層全体にわたる活動の全体的な分散パターンが単語の意味を適切に捉えることです。そして実際、これが事実であることが判明した。
探検
単語の共起の意味学習を調査するために、CCNシムズ から sem モデルを実行します。ここのモデルは、この教科書の初版の初期草案に基づいてトレーニングされたため、比較的専門的な知識を備えており、その多くが読者に共有されることを願っています。
Word の読み方におけるスペルと音のマッピング
次に、英語の単音節単語の大部分 (約 3,000 単語) を構成する大規模な単語セットを使用して、視覚的な単語入力 (正書法) と口頭音声出力 (音韻論) の間の経路に目を向けます。英語での出現頻度に従ってサンプリングされた、このような大規模な単語の選択を学習することにより、ネットワークは英語のスペルと音声の間のマッピングを管理する「ルール」を抽出する機会を得ることができ、その結果、非単語を正常に発音できるようになります。
英語を第二言語として習得しようとした人なら誰でも知っているように、英語は発音の観点から特に難しい言語です。絶対的なルールは (あるとしても) ほとんどありません。すべては、部分的な、文脈に依存した規則性に近く、部分規則性とも呼ばれます。たとえば、mint および hint の文字 i の発音 (短い i 音) を、mind および find の文字 i (長い I 音) と比較してください。最後の子音 (t 対 d) が発音を決定します。もちろん、pint (I の長い音) などの例外は常にあります。
規則性の強さを分類する 1 つの方法は、発音が依存する他の文字の数を数えることです。 pint や yacht のような完全な例外は単語内の すべて の文字に依存しますが、mint と mind は単語内の他の 1 文字 (最後の t または d) に依存します。多くの単語の最後の e など、無音文字の例が多数あります。優れた準規則性は文字 m です。これは、その隣に n があるかどうかによって決まります。その場合、damn、column、または mnemonic のように沈黙します。他の多くの子音は、b (借金)、d (ハンサム)、h (正直)、l (半分)、p (クーデター)、r (イギリス英語の鉄)、s (通路)、t (城)、w (剣)、z など、さまざまな程度の準規則性で沈黙することがあります。 (ランデブー)。
特定の文字を発音するためにどの程度のコンテキストが必要かを決定するもう 1 つの要因は、th (think) のような複数の文字グループが優勢であることです。これらのグループは、個々の文字とは個別に異なる特定の規則的な発音を持ちます。その他の例としては、sch (school)、tch (batch)、gh (ghost)、ght (right)、kn (knock)、ph (photo)、wh (what) などがあります。最も文脈に依存する文字セットの 1 つは、ought、tough、cough、prough、through、nought などの ough グループで、発音は大きく異なります。
だから英語はめちゃくちゃなんです。造語 ghoti は、それがいかにクレイジーになるかを示す有名な例です。これは「フィッシュ」と発音され、gh は tough の f 音、o は women の i 音、ti は nation の sh 音です。
あらゆるシステムが英語の正しい発音を生成できるようにするには、単語自体に至るまで、単語内の特定の文字に関するさまざまなコンテキストを考慮できなければなりません。ニューラル ネットワーク [@SeidenbergMcClelland89] でスペルを音声にシミュレートするための影響力のある初期のアプローチでは、いわゆる Wickelfeature 表現 (ウェイン ウィッケルグレンにちなんで命名) が使用され、書かれた文字は 3 つのグループにエンコードされました。たとえば、「think」という単語は、thi、hin、および ink としてエンコードされます。これはコンテキストを把握するのには適していますが、少し厳密であり、個々の文字自体にかなりの規則性が認められません (ほとんどの場合、m は単なる m です)。結果として、このモデルは、トレーニングで使用される実際の単語とは異なる文字が表示される非単語にはあまり一般化できませんでした。 [@PlautMcClellandSeidenbergEtAl96] (以下 PMSP) による後続のモデルは、個々の文字単位と有用な複数文字のコンテキスト (番目 単位など) を手作業でコーディングした組み合わせを通じて入力単語を表すことにより、良好な非単語一般化を達成しました。
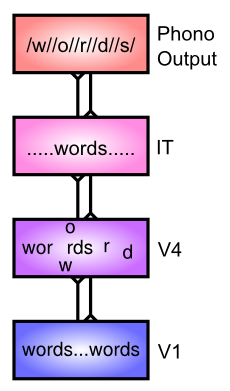
スペルと音のモデル ([@fig:fig-reading-model]) では、知覚と注意 の章で検討したオブジェクト認識モデルのアイデアを活用して、異なるアプローチを採用しています。具体的には、物体認識モデルは、V1 から IT までの階層内の複数のレベルの処理にわたって、空間的不変性を発展させながら、ますます複雑な特徴の組み合わせを構築することを学習できることがわかりました。単語認識のコンテキストでは、これらの複雑な特徴には文字の組み合わせが含まれる可能性がありますが、空間的不変性により、システムは任意の場所にある m が (ほとんどの場合) 他の m と同じであることを認識できます。
読書における空間的不変性の重要性を示す説得力のある実証の 1 つは、数年前に電子メールで広まった次の例から得られます。
私は、私がそのような状況に陥ったことを知りませんでした。フムアン ムニドの障害を認識し、Cmabrigde Uinervtisy での監視を開始しても、その内容がどのようなものであるかはわかりません。適切な情報が適切に設定されているかどうかを確認する必要があります。 rset は taotl ms にすることができ、pboerlm を使用してそれを読み込むことができます。これは、istlef によって raed ervey ltteer ではなく、wlohe としての wrod です。アーズンミグ、ね?イェーと私は、とても良いことを考えていました! yuor fdreins も raed できるかどうかを確認してください。
これは明らかに、正しく綴られたテキストよりも手間がかかりますが、それでもテキストを読むことができるということは、個々の文字を不変の方法で抽出するだけでもかなりの効果があることを示しています。
このオブジェクト認識ベースのアプローチのパフォーマンスをテストするために、非単語のさまざまな標準セットを通じてそれを実行しました。そのうちのいくつかは、PMSP モデルのテストにも使用されました。結果は [@tbl:table-nonword] に表示されます。
-
Glushko の正規 — 強力な規則性と一致するように構築された非単語。たとえば、完全に規則的な nust (must、bust、trust など)。
-
Glushko 例外 — bint (mint のような場合もありますが、pint のような場合もあります) など、同様の英語の例外と矛盾する規則性を持つ非単語。これらの項目は、主な規則性に従って、またはほぼ例外的なケースも含めてスコア付けされます (表では alt OK)。
-
McCann & Besner Ctrls — これらは擬似同音異義語と一致するコントロールで、実際の単語のように聞こえますが、斬新な方法で綴られています。たとえば、choyce (チョイス のように発音)、一致するコントロールは phoyce です。
-
Taraban & McClelland — 頻度が一致する通常の非単語と例外の非単語があります。たとえば poes (高頻度の単語 goes または does など)、および mose (低頻度の pose や lose など) です。
結果は、このモデルがこれらの非単語読解セットに対する人々のパフォーマンスを非常にうまく捉えていることを示しています。これは、このモデルが英語の発音の統計に存在する適切な規則性と副規則性を学習できることを示唆しています。
| 非単語セット | ssモデル | PMSP | 人 |
|---|---|---|---|
| グルシュコの常連 | 95.3 | 97.7 | 93.8 |
| Glushko 例外生 | 79.0 | 72.1 | 78.3 |
| Glushko の例外 alt OK | 97.6 | 100.0 | 95.9 |
| マッキャン&ベズナーコントロール | 85.9 | 85.0 | 88.6 |
| マッキャンとベズナーの同音異義語 | 92.3 | 該当なし | 94.3 |
| タラバン&マクレランド | 97.9 | 該当なし | 100.0 |
表: 本文で説明されているさまざまな非単語データセットにわたる、スペル・トゥ・サウンド・モデル (ss モデル)、PMSP モデル、および人々からのデータの非単語読み取りパフォーマンスの比較。私たちのモデルは、約 3,000 個の英語の単音節単語を学習した後、人間と同等のパフォーマンスを発揮します。
探検
CCNシムズ で ss (スペルを音声に変換) を実行して、スペルを音声に変換するモデルを調査し、単語と非単語の両方の刺激に対するパフォーマンスをテストします。
三角形モデルにおける読書と失読症
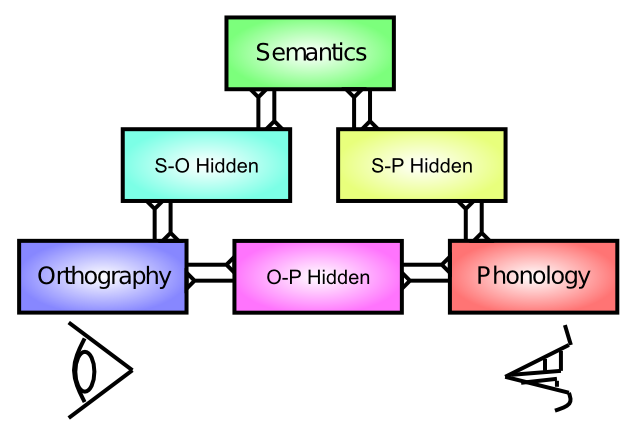
私たちが調査する次の言語モデルは、いわゆる トライアングル モデル ([@fig:fig-lang-paths]) [@PlautShallice93] に従って、セマンティクスとスペルから音へのモデルのコンポーネントをまとめて、読み取りに関与する主要な経路をシミュレートします。このモデルは、書かれた単語の視覚的認識 (正書法)、単語の音声運動出力 音韻、およびその間の単語の意味の 意味論的 表現の機能的役割の基本的な理解を提供します。この一連の言語経路は、単語を音読する際のプロセスをシミュレートするには十分であり、これらの経路が損傷すると、さまざまなタイプの後天性失読症の重要な特徴をシミュレートできます。脳卒中やその他の脳損傷に起因する後天性ディスレクシアは、ディスレクシア (一般的にあらゆる形態の読解障害を指す) という用語から多くの人が連想する、より一般的な形態である 発達性 ディスレクシアとは異なります。
このモデルでシミュレートできる後天性失読症には、次の 3 つの主要な形態があります。
-
音韻 — 非単語 (例: “nust” または “mave”) を読むのが難しいことを特徴とします。これは、正書法と音韻論の間の直接経路が損傷することによって発生する可能性があり(非単語の意味論には活性化が存在しないはずです)、非単語に適用できる学習された規則性に従って、人々が綴りを音にマッピングすることが困難になります。次回のシミュレーションでは、この現象をさらに詳しく調査します。
-
ディープ — 音韻失読症のより重篤な形態であり、人々が時々単語の意味を置き換えてしまうという顕著な特徴を持ち、たとえば「オーケストラ」という単語を「シンフォニー」と発音します。また、「視覚的」エラーもあり、単語入力の誤った認識を反映しているように見えるため、このように名付けられました (たとえば、単語「dog」を「dot」と読むなど)。興味深いことに、直接経路へのより重大な損傷がどのようにしてこのプロファイルを引き起こす可能性があるかがわかります。意味論的エラーは、すべてが意味論的層を通過するために発生し、関連する意味論的表現がアクティブ化される可能性があります。正常な正常な脳では、直接経路は実際に書かれた単語を生成するための関連する制約を提供しますが、この制約がないと、まったく異なるが意味的に関連する単語が出力される可能性があります。
-
表面 — ここでは、非単語の読み取りは無傷ですが、意味論へのアクセスが損なわれており(ウェルニッケ失語症のように)、意味論的経路の損傷が強く示唆されています。興味深いことに、例外単語 (「ヨット」など) の発音は障害されています。これは、人々は通常、ヨットなどの奇妙な単語の発音方法を「記憶」するために意味論的経路に依存し、通常の単語の発音には直接経路がより多く使用されることを示唆しています。
これらのさまざまな形態の失読症がさまざまな患者で確実に観察され、三角形モデルに従って予想される読解障害のパターンに非常によく適合することは、モデルの妥当性に対する強力な裏付けとなります。これらのさまざまな形態のディスレクシアに関連する特定の損傷焦点が、三角形モデルの脳領域へのマッピングに従って解剖学的に意味をなすことができれば、さらに説得力があるでしょう。
探検
三角形モデルおよび関連する失読症の形態のシミュレーションのために、CCNシムズ から dyslexia を実行します。このモデルを使用すると、[@fig:fig-dyslex-sem-clust] に示すように、小さな単語コーパスを使用して、通常の読解に加えて、後天性失読症のさまざまな形態をシミュレートできます。
文ゲシュタルトの構文と意味論
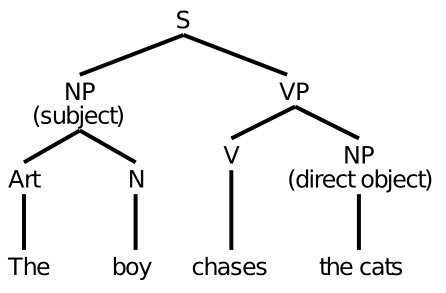
個々の単語のレベルで言語の興味深い特性のいくつかを説明したので、次は一歩上の文のレベルに進みます。このステップでは、構文という厄介な問題に直面します。構文に対する従来のアプローチでは、人々が学校で学んだ (または学ばなかったかもしれない) ツリー状の構文構造 ([@fig:fig-lang-phrase-stru]) に似たものを組み立てることを前提としています。しかし、これらのことは明確に教える必要があり、多くの人にとって最も自然な考え方ではないようであることを考えると、おそらくこれが私たちの脳が実際に言語を処理する方法である可能性は低いように思えます。
これらの構文構造は、実際にはニューラル ネットワークで達成するのがかなり困難なロールフィラー バインディングの能力も想定しています。たとえば、文の主語を含むように指定された変数スロットに名詞 boy を何らかの方法で「バインド」すると仮定します。次の文に進むと、このバインディングは次のバインディングに置き換えられます。この絶え間ない結合と結合解除は、むしろ車の車輪の回転に似ています。車輪に付着しようとするあらゆるものを引き裂く傾向があります。人間が車輪の代わりに脚を持っている重要な理由の 1 つは、車輪の回転には耐えられない血液供給や神経などを脚に供給する必要があるためです。同様に、私たちのニューロンは物理的なシナプスを介して長期的に安定した接続を発達させることで成長し、この急速な結合と結合解除のプロセスは苦手です。 執行機能 の章では、これらの問題にさらに詳しく焦点を当てます。
ニューラル ネットワークの原則に直接基づいた、文章処理に関する別の考え方が、[@StJohnMcClelland90] の Sentence Gestalt モデルに取り入れられています。重要なアイデアは、構文と意味論の両方が、従来のアプローチで想定されていたすべての正確な構文結合を必要とせずに、文の全体的なゲシュタルト意味を捉える進化する分散表現に統合されるということです。 boy を主語に明示的にバインドするのではなく、文全体のより大きな意味をエンコードします。これは、少年が追いかけているため、少年が主語 (より正確には、エージェント) であることを暗示します。
この考え方の利点の 1 つは、単語の集合の特定の意味論が構文解釈を劇的に変える可能性がある場合に、構文解析プロセスを取り巻くすべてのあいまいさをより自然に処理できることです。この曖昧さを典型的に示すのが次の文です。
時間は矢のように過ぎていきます。
次のような代替案を検討するまでは、これはそれほど曖昧ではないように思えるかもしれません。
果物はバナナのように飛びます。
flies という単語は、意味論的な文脈に応じて動詞または名詞のいずれかになります。さらに熟考すると、最初の文のさらに曖昧な解釈がいくつか明らかになり、文を再読するときにそれらが脳に定着するのは楽しいことです。 [@Rohde02] の別の例は次のとおりです。
そのスリッパはおせっかいな犬が見つけました。
スリッパは寝ている犬に見つかりました。
たった 1 つの単語を微妙に変えるだけで、犬が代理人であるものから、犬がより周辺的な役割を果たすものへと文全体の意味が書き換えられます。
そもそも構文解析を気にせず、文の意味を理解しようとするだけであれば、このような曖昧さはまったく問題になりません。一般に、文の意味は構文解析よりもはるかに曖昧ではありません。構文を正確に理解するには、多くのきめ細かい区別を行う必要がありますが、実際には気にしないかもしれません。しかし、意味は単語の正確な組み合わせに依存するため、文には多くの創発的な意味が存在します。[@Rohde02] の別の例では、2 つの文は構文的には同じですが、意味が大きく異なります。
ようやく赤ちゃんを寝かしつけました。
ようやく犬を寝かしつけました。
文を意味論的に指向したゲシュタルト表現という概念は魅力的に思えますが、実装されたモデルがそのようなものが実際に機能することを実際に示すまでは、それはすべて単なる良い話にすぎません。 St. John & McClelland (1990) モデルは、文内の単語が処理されるにつれて段階的に形成される分散表現を使用して、その文に関するさまざまな理解の質問に答えることができることを示しています。ただし、これは非常に小さな言語空間を使用して行われており、新しい単語にどの程度一般化できるか、またはより現実的に複雑な言語に拡張できるかは不明です。同様の全体的な戦略を採用した [@Rohde02] によるより洗練されたモデルは、これらの課題に対する前向きな答えをある程度約束します。 Rohde モデルのトレーニングでは、文のさまざまな要素の主題上の役割に関するスロットフィラー命題の形式で構造化された意味表現が使用されます。これらには、エージェント、経験者、目標、手段、患者、情報源、テーマ、受益者、同行者、場所、作成者、所有物、サブタイプ、所有物、if、 because、while、while の役割が含まれます。このテーマ役割結合アプローチは、セマンティクスをエンコードするための自然言語処理分野で広く使用されていますが、意味論的な意味の非構造化ゲシュタルト表現の概念からは離れています。文のゲシュタルト モデルは、このテーマ別役割トレーニングのより単純な形式を使用しており、この点ではあまり議論の余地がないようです。
文章のゲシュタルト モデル
センテンス ゲシュタルト (SG) モデルは、次の要素で構成される非常に小さなおもちゃの世界でトレーニングされます。
-
人物: バス運転手 (成人男性)、教師、(成人女性)、女子高生、投手 (少年)。 大人、子供、誰かとも使われます。
-
アクション: 食べる、飲む、かき混ぜる、広げる、キスする、与える、叩く、投げる、運転する、立ち上がる。
-
オブジェクト: スポット (犬)、ステーキ、スープ、アイスクリーム、クラッカー、ゼリー、アイスティー、クールエイド、スプーン、ナイフ、指、バラ、バット (動物)、バット (野球)、ボール (球体)、ボール (パーティー)、バス、ピッチャー、毛皮。
-
場所: キッチン、リビングルーム、小屋、公園。
トレーニング中にネットワークを調査するために使用される意味論的な役割は次のとおりです: エージェント、アクション、患者、機器、共同エージェント、共同患者、場所、副詞、受信者。
主な構文変数は、能動的な構文と受動的な構文の存在、およびイベントをさらに指定する句です。また、ご覧のとおり、単語のいくつかは曖昧であるため、曖昧さを解消するには文脈を使用する必要があります。
このモデルは、どの単語が共起する傾向があるかを指定する意味論的および構文文法に従って、ランダムに生成された文でトレーニングされます。その後、一連の主要なテスト文でテストされ、さまざまな方法でその動作が調査されます。
-
能動的意味論: 女子高生はスプーンでクールエイドをかき混ぜました。 (クールエイドは患者のみであり、この文のエージェントではありません)
-
能動構文: バス運転手は先生にバラを与えました。 (教師は患者またはエージェントのいずれかになります – 語順構文がそれを決定します)。
-
受動的な意味: * ゼリーはバス運転手によってナイフで広げられました。* (ゼリーはエージェントではないので、忍耐強くなければなりません)
-
受動的な構文: 先生はバス運転手にキスされました 対 バス運転手は先生にキスされました (教師またはバス運転手のどちらかがエージェントになる可能性があり、構文だけでどちらであるかが決まります)。
-
単語のあいまいさ: バス運転手は公園にボールを投げました。、先生はリビングルームにボールを投げました。 (ボールは曖昧ですが、意味的には、バス運転手は公園にボールを投げ、教師はリビングルームにボールを投げます)
-
概念のインスタンス化: 先生は誰かにキスしました。 (男性)。 (先生はいつも男性とキスします — モデルはこれに気づきましたか?)
-
役割の詳細: 女子高生はクラッカーを食べました。 (指で)。 女子高生が食べた (スープ) (これらが主なケースです)
-
オンライン更新: 子供はスープを上品に食べました 対 ピッチャーはスープを上品に食べました (女子高生は通常スープを食べるので、スープを見た後、最初のケースでは曖昧な 子供 が女子高生として解決されますが、2 番目のケースで ピッチャー という特定の入力がこの更新を妨げます)。
-
対立: * 大人はキッチンでアイスティーを飲みました。* (リビングルーム) (アイスティーは常にリビングルームで飲まれます)。
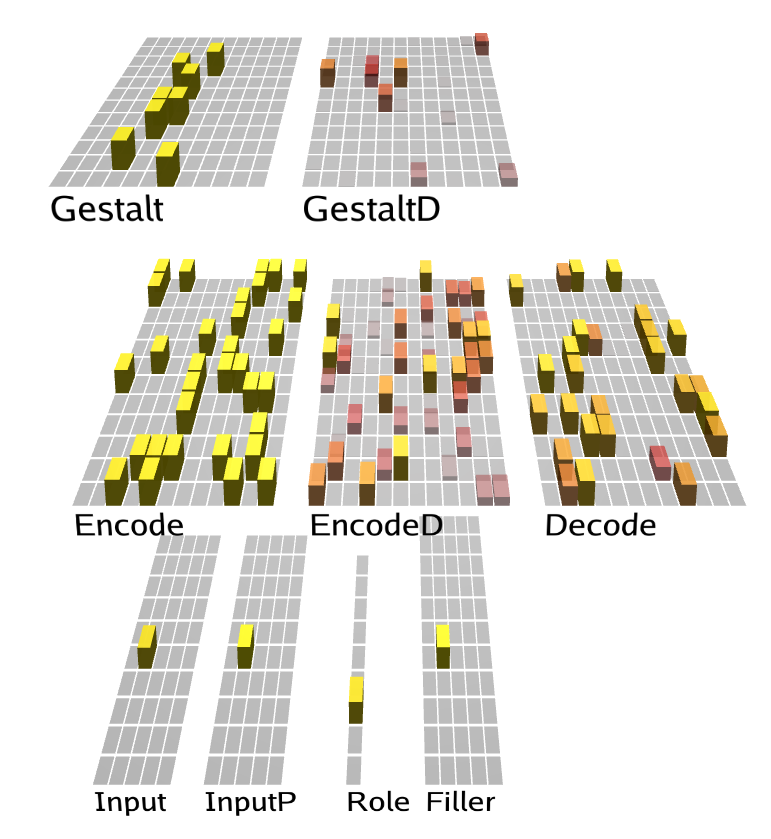
モデル構造 ([@fig:fig-sg-net-deepleabra]) には、エンコーディングの隠れ層を介してゲシュタルト層に投影される単一の単語入力 (単語のローカリスト単一単位表現を使用) があり、そこで文の意味の分散表現が開発されます。前の単語と文の意味解釈のメモリはコンテキスト層を介してエンコードされ、前の単語入力からのゲシュタルト層の活性化状態のコピーが効果的に保持されます。 歴史的に、このコンテキスト層は 単純再帰ネットワーク (SRN) として知られており、時間的に拡張されたタスク [@Elman90; @Jordan89; @CleeremansMcClelland91; @MunakataMcClellandJohnsonEtAl97] のニューラル ネットワーク モデルで広く使用されています。 このモデルでは、視床の髄核と皮質の深層 [@OReillyWyatteRohrlich17] の間の視床皮質接続に基づいた、生物学に基づいたバージョンの SRN を使用しています。これは、Leabra の DeepLeabra バージョンに実装されています。 ネットワークのトレーニングは、上で列挙したさまざまな意味論的役割 (たとえば、エージェント 対 患者) についてネットワークを繰り返し調査することによって得られます。 役割入力ユニットがアクティブ化され、その後、フィラー出力層で適切な応答をアクティブ化するようにネットワークがトレーニングされます。 さらに、他の DeepLeabra モデル (および他の SRN モデル) と同様に、エンコーダー層は次の入力の予測を試み、これらの予測のエラーから学習します。
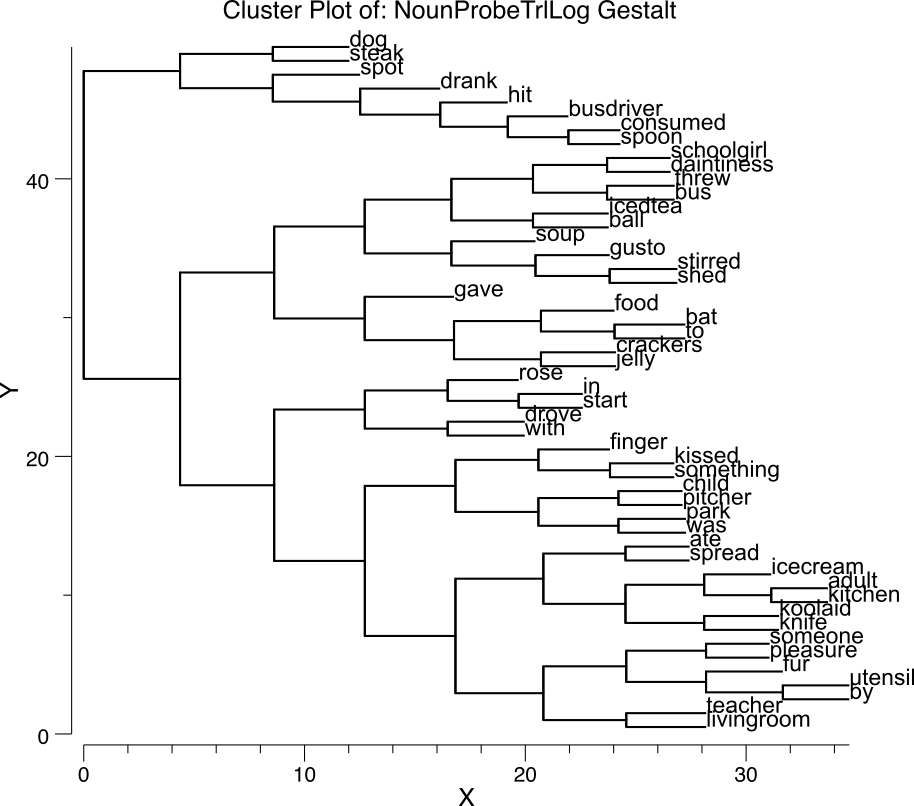
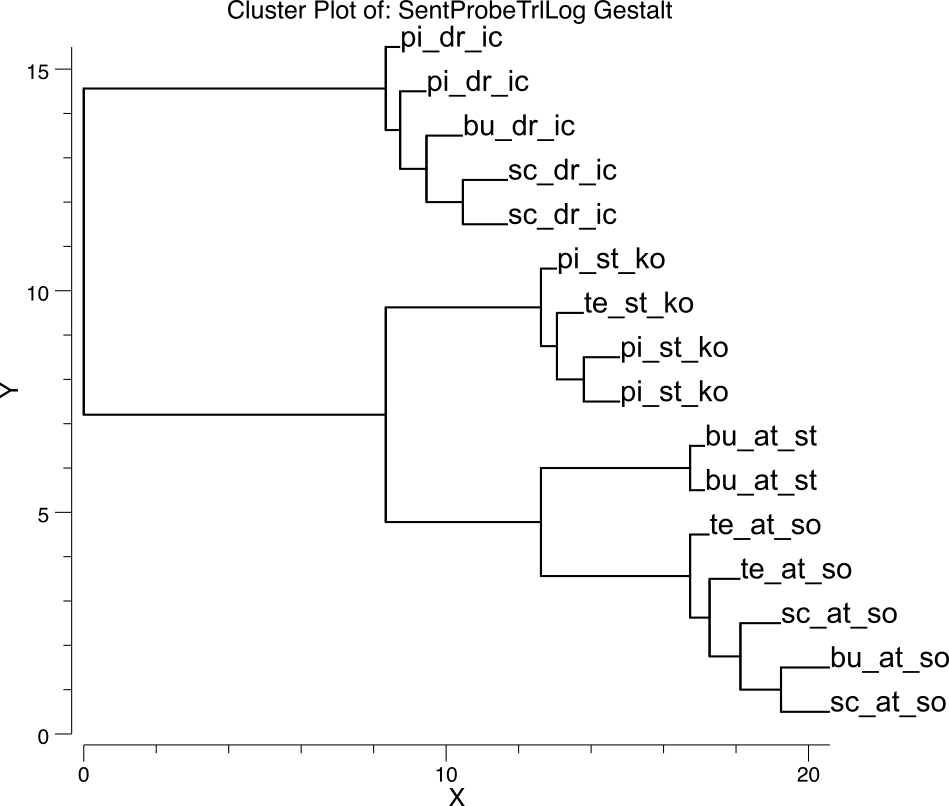
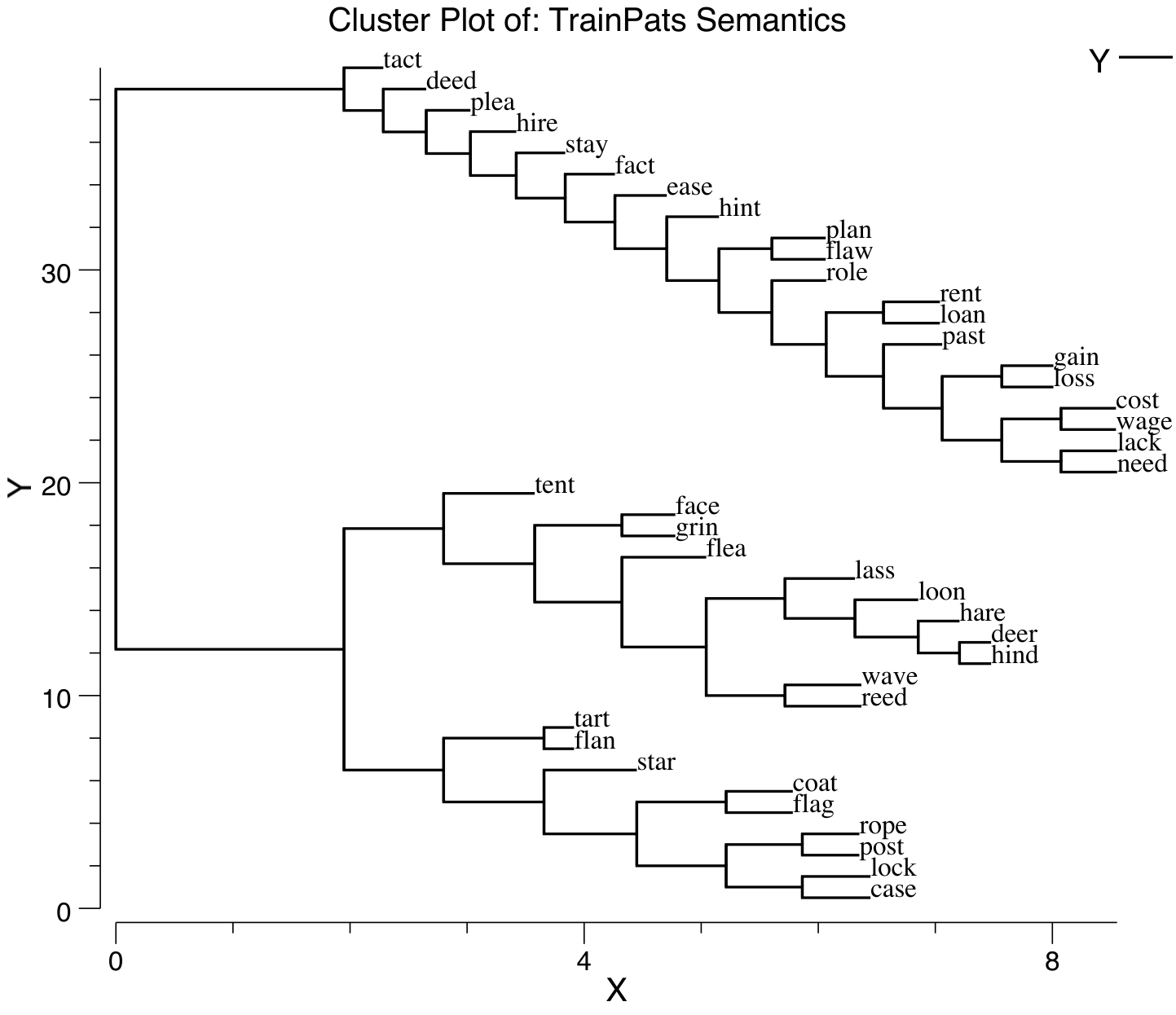
[@fig:fig-sg-noun-clust-deep] は、さまざまな名詞のゲシュタルト層表現のクラスター プロットを示しており、ネットワークがこれらの単語に対して意味のある意味的類似構造を開発していることを示しています。さらに詳しく調べると、[@fig:fig-sg-sent-probe-clust-deep] は、一連の関連する文のクラスター プロットを示しています。これは、賢明な動詞中心の意味論的構成を示しています。同じ動詞を共有する文がすべてクラスター化され、その中のエージェントが第 2 レベルの構成を形成します。
探検
CCNシムズ から sg モデルを実行して、文のゲシュタルト モデルを調べます。
文とその先の言語モデリングにおける次のステップ
言語の主な機能はコミュニケーションです。それは基本的にセマンティクスに関するものです。そして、セマンティクスは、言語モデリングのさらなる進歩に対する大きな障壁となっています。文のゲシュタルト モデルは非常に単純なセマンティクスを持ち、[@Rohde02] によって開発されたより高度なバージョンでは、モデルが独自に開発すべきものをより多く外部に注入するという犠牲を払って、より複雑なセマンティクスが導入されています。したがって、文レベルまたはより高いレベルの言語モデルの基本的な課題は、対応する意味論をトレーニングするより自然な方法を開発することです。理想的なケースでは、仮想ヒューマノイド ロボットは、自然を模倣した豊かな環境を歩き回り、この環境を理解し、生き残るために言語を受け取り、生成します。これは、人々が言語を獲得して使用する方法を模倣するものであり、間違いなく、言語獲得の性質とより高いレベルの意味表現についてかなりの洞察を提供するでしょう。しかし、明らかにこれには多大な労力が必要です。