compcogneuro/web: error-backpropagation
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/error-backpropagation.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Learning”, “Computation”] bibfile = “ccnlab.json” +++ 誤差逆伝播 (「バックプロップ」) は、[[error-driven learning]] を実行するための比較的単純な数学的手順であり、基本的な計算の「連鎖ルール」から直接導出されます。これは、error の計算方法を定義する objective function から始まります。この誤差を最小限に抑えるためにシナプスの重みを更新する方法を決定するには、連鎖規則を使用して、特定の重み値に関する目的関数の一次偏導関数を計算できます。これにより、誤差勾配が定義されます。シナプスの重みは、この勾配の方向に沿って繰り返し更新されます。この誤差最小化手順を実装するには、高次導関数の使用など、さまざまな手法を使用できます。
[[abstract neural network]] モデルで使用される現世代のソフトウェア ツールには、モデルで使用される一連の方程式からこれらの誤差勾配を直接自動的に計算する機能があり、複雑な新しいモデルを構築するプロセスが大幅に簡素化され、この分野の研究と進歩の爆発的な成長に大きく貢献してきました。たとえば、広く使用されている パイトーチ フレームワークには オートグラード があります。このようなツールが登場する前は、人々は関連する微積分を手動で実行し、結果として得られる方程式をプログラムしていました。
バックプロップは、微積分と関数の最適化の基本原理に基づいて、長年にわたって [[@^WidrowHoff60]] や [[@^Werbos74]] を含む多くの人々によって「発明」されてきました。しかし、[[@^RumelhartHintonWilliams86]] は、それを発明した「最後」でした。つまり、神経にインスピレーションを得た学習をモデル化するための包括的な全体的なフレームワークの文脈で、この学習手順の重要な特性を明確にし、実証することに最も成功したことを意味します ([[@RumelhartMcClelland86]]; [[@McClellandRumelhart86]])。
現在広く使用されている最新の [[abstract neural network]] モデルはすべて、[[large language models]] (LLM) を含む主にバックプロップに基づいており、この手法とより広範な [[error-driven learning]] の計算能力を明確に示しています。この手順の驚くべき能力は、汎用計算フレームワークとしての [[search]] のコンテキストでさらに説明するように、専用並列勾配ベース法を使用して非常に高次元の空間を効率的に検索できる重要なケースを提供します。
逆伝播を計算する文字通りの数学的手順は、[[@^Crick89]] によって有名に指摘されているように、脳の既知の特性と矛盾します。ただし、バックプロップへの [[generec]] (一般化再循環) 近似 ([[@OReilly96]]; [[@LillicrapSantoroMarrisEtAl20]]) は、生物学的にさらに詳細な [[kinase algorithm]] で詳しく説明されているように、誤差の計算に [[temporal derivative]] の重要な原理を利用する、生物学的メカニズムと一致する強力な誤差駆動学習のメカニズムを提供します。グラデーション。
[[@^RumelhartHintonWilliams86]] のオリジナル作品を含め、バックプロップ モデルで勾配降下法を実行するために最も一般的に使用される手法は、オンラインの確率的勾配降下法です。この場合、_入力パターン_のランダムに選択された小さなサブセットを使用して誤差勾配が計算され、次の入力パターンに進む前にシナプスの重みが更新されます (「オンライン」)。これは、シナプスの重みを更新する前にすべての入力パターンにわたって勾配が計算されるバッチ モード学習とは対照的です。直感的には、オンライン形式を使用すると、ネットワークは有望な勾配方向をより迅速に探索できるようになり、すべての入力パターンを一度に考慮するときに発生する多くの「結びつき」が解消されます。これは、すべてのパターンにわたるすべての制約を一度に満たそうとするのとは対照的に、より「決定的な」学習形式です。
バックプロップの導出
{id=”figure_bp-compute” style=”高さ:15em”}
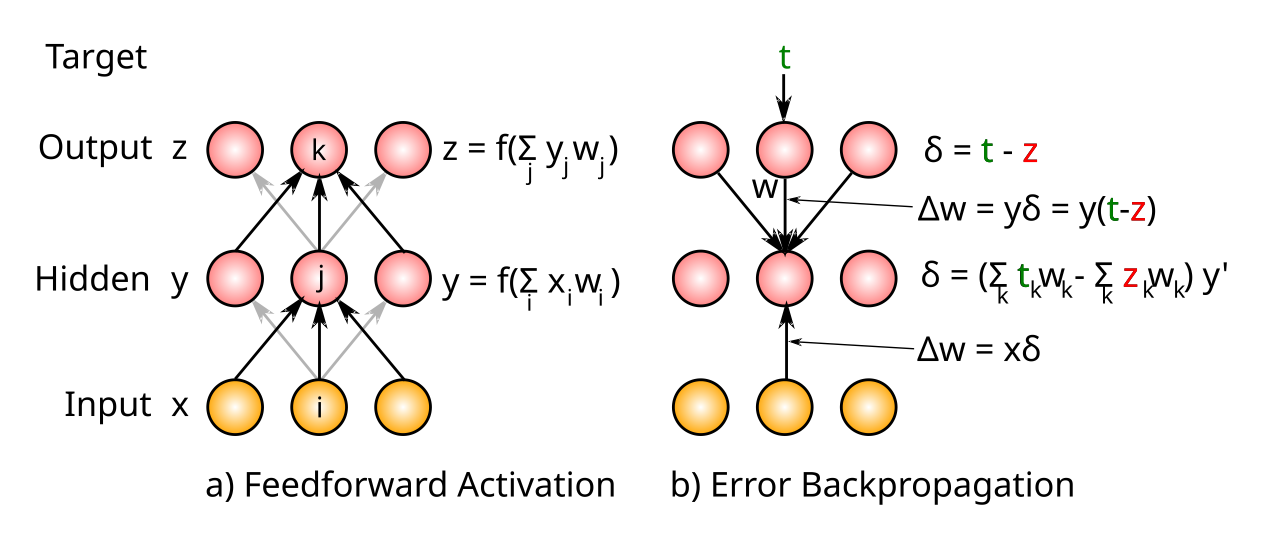
ソフトウェアが自動的に勾配を計算できますが、何が起こっているのかを実際に理解するために、特に [[GeneRec]] アルゴリズムのように、より生物学的に妥当な方法でこれらの計算を実行するさまざまな方法を理解するには、バックプロパゲーション計算のロジックに取り組むことが重要です。 [[#figure_bp-compute]] は、単純な 3 層フィードフォワード ネットワークの場合にどのように動作するかを示しています。
フィードフォワードのアクティブ化
まず、[[#figure_bp-compute]] の左側のパネルに示すように、入力から非表示、出力までの feedforward activity フローを定義します。
{id=”eq_netin” title=”ネット入力”} \(\eta_j = \sum x_i w_{ij}\)
$\eta_j$ は、隠れユニット $j$ への線形_ネット入力_ であり、送信アクティビティ $x_i$ にシナプス重み値を掛けたドット積として計算されます (説明については [[linear algebra]] を、生物学的コンテキストについては [[neuron#Computing input conductances]] を参照してください)。
単位 activity (生物学的用語で神経スパイクの予想速度のようなものを表す) は、この正味入力の関数になります。
{id=”eq_y-act” title=”アクティベーション機能”} \(y_j = f(\eta_j)\)
この関数 f の正確な形式は、微分可能_である限り重要ではありません (つまり、線形正味入力係数に関して微分を計算できます)。 1980 年代のモデルで使用されていた標準関数は、_sigmoid (S 字型) logistic 関数でした。
{id=”eq_logistic” title=”シグモイド ロジスティック関数”} \(f_l(x) = \frac{1}{1 + e^{-x}} = \frac{e^{-x}}{1 + e^{-x}}\)
この関数には、「飽和非線形性」という生物学的に現実的な特性があり、正味入力が大きくなると、活性化値の追加の増加がますます小さくなり、[[neocortex]] のニューロンの最大持続発火率約 100 Hz と一致します。
この関数の導関数は、非常にシンプルな形式になります。
{id=”eq_logistic-deriv” title=”ロジスティック導関数”} \(f_l'(x) = f_l(x) (1 - f_l(x))\)
ただし、実用的な観点から見たこのロジスティック関数の大きな問題は、多層 (「深い」) ニューラル ネットワークの層間でエラー信号の「指数関数的減衰」を引き起こすことです。これが、こうした隠れ層を追加するときに、これらの初期のネットワークが通常うまく機能しなかった主な理由の 1 つです。これは、_勾配消失_問題として知られています。また、デジタル コンピューターでは指数関数の計算が比較的遅くなります。
これらの理由から、現代のバックプロパゲーション ネットワークは通常、区分線形である ReLU rectified linear Unit 関数を使用します。
{id=”eq_logistic” title=”ReLU 関数”} \(f_r(x) = \rm{max}(0, x)\)
つまり、0 未満のすべての正味入力レベルではアクティベーションが 0 になり、それ以外の場合は純粋に線形になります。導関数も同様に、0 または 1 の区分関数です。詳細については、[[abstract neural network#Key advances in ANNs in relation to neuroscience]] を参照してください。
エラー関数
アクティビティが出力レイヤーに到達すると、広く使用されている Sum Squared Error (SSE) などの error 関数 を介して target 値と比較されます。
{id=”eq_sse” title=”和二乗誤差”} \(SSE = \sum_k \left( t_k - z_k \right)^2\)
これはニューロン全体で線形であるため、特定のユニットに関して簡単に区別できます。歴史的には、クロスエントロピー (CE) 誤差関数も使用されていました。これは、その微分関数がロジスティック関数の微分関数を打ち消し、計算が少し簡単になるためです。
エラー勾配チェーン ルール
ここで、いよいよ計算の核心に入ります。ネットワーク全体のシナプスの重みを変更することで誤差 (SSE) を最小限に抑えることです。これが、この文脈におけるエラー主導型学習の意味です。特に、微積分の観点から見た最大の課題は、重みを入力ユニットから隠れユニットに変更する方法を見つけ出すことです。これには、連鎖ルールのいくつかのステップが必要となるためです。
{id=”eq_bp-chain-dw” title=”SSE による逆伝播”} \(\Delta w_{ij} \propto -\frac{\partial SSE}{\partial w_{ij}}\)
この式は、重みを入力ユニット $x_i$ から隠れユニット $y_j$ に変更する方法を知るには、この重み $w_{ij}$ の変化が SSE の変化にどのように関連しているかを知る必要があるという考えを捉えています。これは、偏導関数式が示すことです。マイナス記号は、エラーを最大化するのではなく最小化することを示しているため、この導関数とは逆の方向に進みます。
[[#figure_bp-compute]] を参照すると、隠れユニット $j$ および出力ユニット $k$ を介した基本アクティブ化関数のチェーン ルール展開により、上記の式が次のように展開されることがわかります。
{id=”eq_bp-chain-expand” title=”チェーン ルールの拡張”} \(-\frac{\partial SSE}{\partial w_{ij}} = -\frac{\partial SSE}{\partial z_k} \frac{\partial z_k}{\partial \eta_k} \frac{\partial \eta_k}{\partial y_j} \frac{\partial y_j}{\partial \eta_j} \frac{\partial \eta_j}{\partial w_{ij}}\)
これは膨大なように見えますが、各ステップは簡単に計算され、実際には、フィードフォワード アクティベーション スイープが発生するのとほぼ同じ方法で、層間を逆方向にカスケードする単純な再帰計算になります。口頭で言えば、出力アクティビティによって SSE がどのように変化するか、出力アクティビティがそのネット入力によってどのように変化するか、このネット入力が隠れユニット アクティビティ $y_j$ によってどのように変化するか、次にこのアクティビティがそのネット入力 $\eta_j$ によってどのように変化するか、そして最後に、このネット入力が送信ユニット $x_i$ から隠れユニット $y_j$ への重みによってどのように変化するかを計算することが含まれます。
これらの係数がすべて計算されると、それらを乗算して、誤差を最小限に抑えるために重み $w_{ij}$ をどのように調整するかを決定できます。これは、すべての送信ユニットからすべての隠れユニットに対して、またこのチェーンの短いバージョンを使用して、すべての隠れユニットからすべての出力ユニットに対して行うことができます。結果の式は次のようになります。
{id=”eq_bp-chain-wij” title=”チェーン ルールの値”} \(-\frac{\partial SSE}{\partial w_{ij}} = \sum_k (t_k - z_k) * z_k' * w_{jk} * y_j' * x_i \rightarrow\)
$\partial SSE / \partial z_k$ の負の値は $2 (t_k -z_k)$ であり、2 は定数であるため、これを学習率パラメータに吸収することができることに注意してください。
物事をさらに単純化するために、各ユニットのエラー勾配変数 $\delta$ を定義できます。これは、そのユニットの誤差の偏導関数を表します。これらの用語では、出力層ユニットの $\delta_k$ に対する隠れユニットの $\delta_j$ は次のようになります。
{id=”eq_delta-j” title=”エラー勾配”} \(\delta_j = \left( \sum_k \delta_k w_{jk} \right) y'\)
この形式は、計算のより単純な再帰的性質を明確に示しています。これには、アクティベーションが通常「フィードフォワード」方向に流れるのとは逆の方向に、重み全体にわたって「デルタ」値を_後方_に伝播することが含まれます。これが_バックプロパゲーション_の本質です。フィードフォワード方向とフィードバック方向で異なる方程式が必要な点は、[[Axon]] および [[kinase algorithm]] で使用される [[temporal derivative]] メカニズムとは対照的です。
したがって、これらの用語で得られる学習ルールは単純に次のようになります。
{id=”eq_delta-dw” title=”誤差勾配学習”} \(\デルタ w_{ij} = \イプシロン \delta_j x_i\)
ここで、$\epsilon$ は、重み更新ごとに誤差勾配に沿ってステップ サイズを制御する学習率係数です。
デルタルール
隠れ層から出力層へのシナプスに焦点を当てるか、隠れ層なしで入力から出力まで直接進むネットワークの単純な 2 層バージョン (つまり、パーセプトロン; [[@Rosenblatt62]]; [[@MinskyPapert69]]) を考慮すると、連鎖ルールは短くなり、数学的にはデルタ ルールと呼ばれる方程式が得られます。 [[reinforcement learning]] ([[@RescorlaWagner72]]; [[@WidrowHoff60]] および [[@SuttonBarto81]] も参照) の Rescorla-Wagner 学習規則。
以下は、重み付けされたシナプス値 w を持つ、活性化 y の出力ユニットが活性化 x の入力ユニットから受け取るデルタ ルールの簡単な形式です。
{id=”eq_delta-w” title=”デルタ ルール”} \(\デルタ w = (t - y) x\)
ここで、t はターゲット値です。
単位の割り当て
デルタ ルールと [[#eq_delta-dw]] は、エラー駆動学習の本質が、エラー信号と送信ユニットのアクティブ化の単純な積であることを示しています。送信ユニットのアクティビティによる重み変化のこの調整により、重要な [[credit assignment]] 機能 (この場合はむしろ責任の割り当て) が達成されるため、出力でエラーが発生した場合、重みはそのエラーに寄与した送信ユニットの重みのみ変更されるはずです。アクティブではないユニットを送信してもエラーは発生せず、その重みは調整されません。
アクティベーションへのバックプロパゲーション
[[#eq_delta-j]] で計算された誤差勾配を使用して、ネットワーク内のユニットのアクティブ化状態を直接更新し、重みの変更が行われたときに変更される方向にユニットを移動することもできます。
{id=”eq_delta-act” title=”更新されたアクティベーション”} \(y^+ = y + \lambda \delta\)
ここで、$y^+$ は、[[GeneRec]] アルゴリズムによって実行される同等の計算と同様に、plus Phase 活性化値を表し、$\lambda$ は、追加する勾配の量を決定する学習率のような係数です。
| したがって、この新しいアクティブ化値は、現在の入力状態のより正確な [[optimized representations | optimized representation]] を表します。完全な [[bidirectional connectivity]] を備えた [[Axon]] ネットワークでは、[[#eq_delta-act]] のような誤差勾配を特に含むプラスフェーズのアクティビティ状態を持つことに加えて、複数の反復にわたって [[constraint satisfaction]] 処理を実行することによって、アクティベーション状態がさらに最適化されます (数学的解析については [[GeneRec]] を参照)。 |
ただし、標準のフィードフォワード バックプロパゲーション ネットワークでは、$y^+$ アクティブ化状態をどのように使用するかは明確ではありません。この活性化値は、ネットワーク内の他のニューロンが認識したものではありません。これらの更新された値に基づいてすべての活性化を更新するには、追加の反復が必要になります。これは、誤差勾配自体を更新する必要があることなどを意味します。この問題に対する 1 つの解決策は、アルメイダ-ピネダ バージョンの再帰逆伝播 ([[@Almeida87]]; [[@Pineda88]]) によって提供されます。これは、ネットワークの活性化が安定するまで効果的に反復されます。そこに示されているように、これは実質的に [[GeneRec]] モデルで起こっていることです。