compcogneuro/web: generec
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/generec.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Name = “GeneRec” Categories = [“Learning”, “Computation”] bibfile = “ccnlab.json” +++ GeneRec (一般化再循環、「一般化」の始まりのように発音されます) アルゴリズムは、広く使用されているが生物学的にありそうもない [[error backpropagation]] アルゴリズム ([[@OReilly96]]) とほぼ同じ誤差勾配を計算する、より生物学的にもっともらしい方法を提供します。これは、[[bidirectional connectivity]] および [[temporal derivative]] 学習ルールを使用してエラー信号を効果的に伝播することによって行われます。 [[Axon]] モデルはこのアルゴリズムを直接使用しませんが、使用する [[kinase algorithm]] は定性的に同じ誤差勾配を計算します。また、GeneRec は、これらのアルゴリズムがどのように、そしてなぜ機能するかを理解するための、より抽象的で数学的に導出された基礎を提供します。
{id=”figure_bidir-err” style=”高さ:25em”}
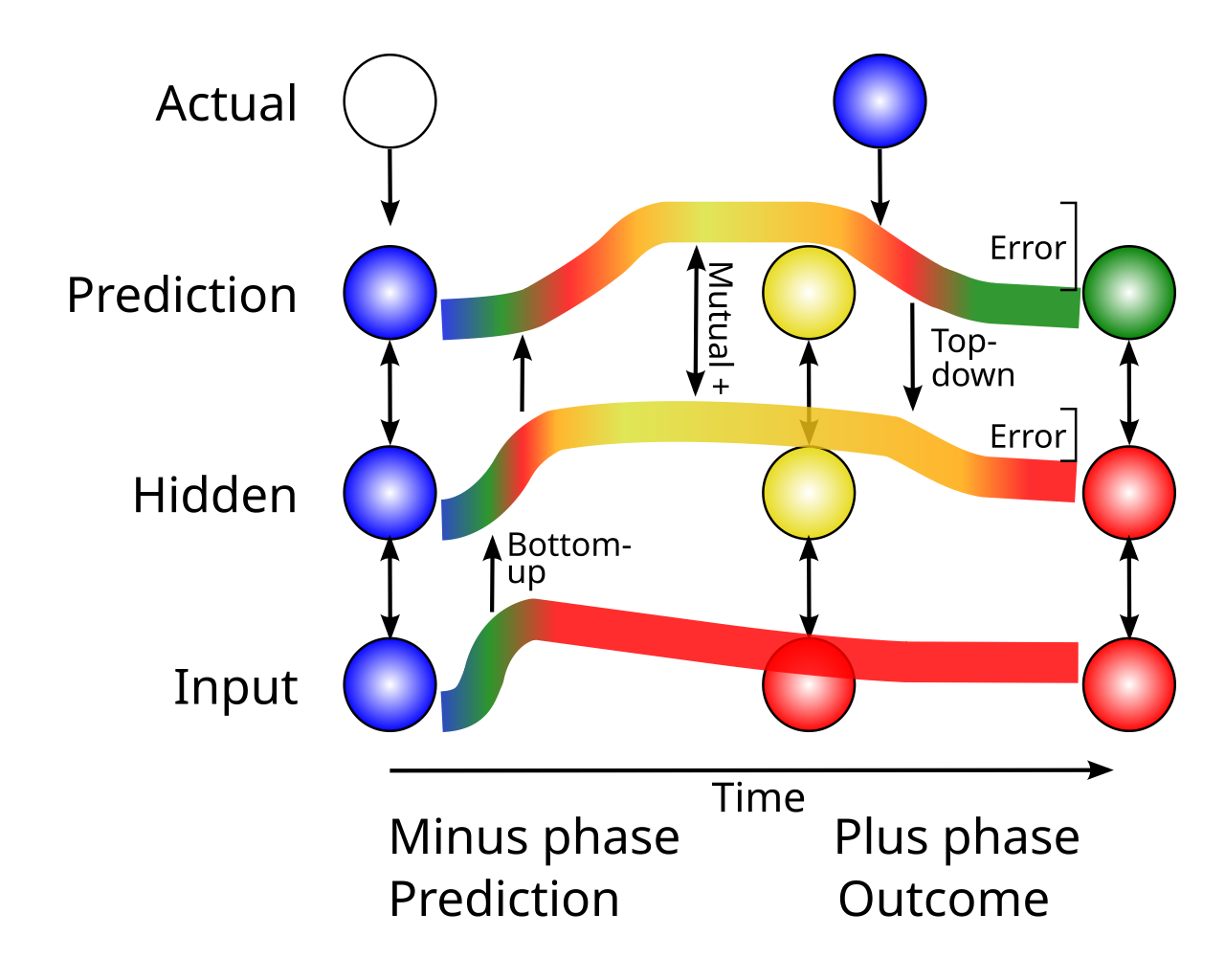
[[#figure_bidir-err]] は、誤差勾配を計算するための時間微分学習メカニズムと組み合わせた双方向の興奮性接続を可能にする主要なダイナミクスのすべてを示しています。この図は、[[temporal derivative]] ページの単純なマイナス相 $\rightarrow$ プラス相 [[temporal derivative#figure_minus-plus]] のより詳細なバージョンです。
太線は、ネットワークが予測層ニューロンで「高アクティビティ」予測を生成する [[predictive learning]] コンテキストにおける、3 つの代表的なニューロンのアクティビティを経時的に追跡します。これは、「低アクティビティ」の実際の結果と矛盾します。開始時には、すべてのニューロンは非アクティブです ([[neocortex]] では通常そうではありませんが、説明には役立ちます)。次に、感覚入力によって入力ニューロンの活動が駆動され、隠れニューロンと予測ニューロンの間に強い興奮性の重みがあると仮定して、順番に隠れニューロンと予測ニューロンが興奮します (実際のネットワークでは、各層に多数のニューロンがあり、重みの豊富なパターンなどがあります)。
この活動の最初の波の結果は、ネットワーク全体で一時的に安定した活動の「マイナス段階」状態になります。これは、その時点でのニューロンの「スナップショット」で示されています。このネットワーク状態は、ネットワークの全体的な予測状態を表します。重要なのは、双方向の興奮性接続により、隠れニューロンと予測ニューロンがフィードフォワード接続のみの場合よりもさらに興奮することです。つまり、これらのニューロンは相互に活動を強化します。 この相互依存関係により、エラー信号を通信するための双方向接続が可能になります。
また、ボトムアップ接続とトップダウン接続の調整や、どちらかの経路の排他的使用は一切なく、すべてが常に双方向に相互作用します。これは、ボトムアップ経路とトップダウン経路の分離を必要とする構造ベースの誤差逆伝播モデルとは大きく異なります (レビューについては、[[@LillicrapSantoroMarrisEtAl20]] を参照してください)。
双方向の相互依存性の重要な役割は、_Plus フェーズ_が到来すると明らかになります。これは、予測されていた実際の結果が実際に発生し、予測層でニューラル活動を直接駆動するときです。図に示されているケースでは、この実際の結果は「低アクティビティ」(青) であり、「高アクティビティ」の予測に反しています。したがって、予測レイヤーはこの「否定的な」結果によって抑制され、そのアクティビティが低下します。このアクティビティの低下は、隠れ層まで伝播し、隠れ層のアクティビティも低下します。 (脳内の実際のダイナミクスは、プールされた [[inhibition]] のコンテキストにおける活動の分散パターンに基づいて動作します。そのため、予測と結果の違いは、一般に「高い活動」と「低い活動」ではなく、さまざまな活動の分散パターンに関係します。ただし、これを図で表すのはさらに困難です)。
したがって、Hidden ニューロンは、その双方向接続により、予測層上の対応する時間的変化を反映する時間微分を経験します。以下の数学的導出は、この時間導関数が誤差逆伝播によって計算された誤差勾配の適切な近似を提供することを示しています。
実際、GeneRec は _activation_state を使用して誤差導関数を計算しますが、逆伝播はその活性化状態とは完全に別個の誤差勾配を直接計算します。結果として、GeneRec はプラス相の誤差勾配を含む [[optimized representations]] を自動的に生成します。これは [[error backpropagation#backpropagation to activations]] の形式と同等ですが、以下で詳しく説明するように、標準のフィードフォワード逆伝播ネットワークは生成しません。これは、[[constraint satisfaction]] を介した表現の既存の最適化に加えて、やはり双方向接続によって推進されます。
要約すると、GeneRec アルゴリズムは、[[neocortex]] の顕著な機能である双方向接続が、生物学的に妥当な方法で強力なエラー駆動学習をどのように可能にするかを示しています。元の GeneRec 論文以来、密接に関連するさまざまな提案も進められており、さまざまな分析と導出ルートが提供されています ([[@XieSeung03]]; [[@ScellierBengio17]]; [[@WhittingtonBogacz17]])。
バックプロパゲーションの近似
{id=”figure_generec-bp” style=”高さ:30em”}
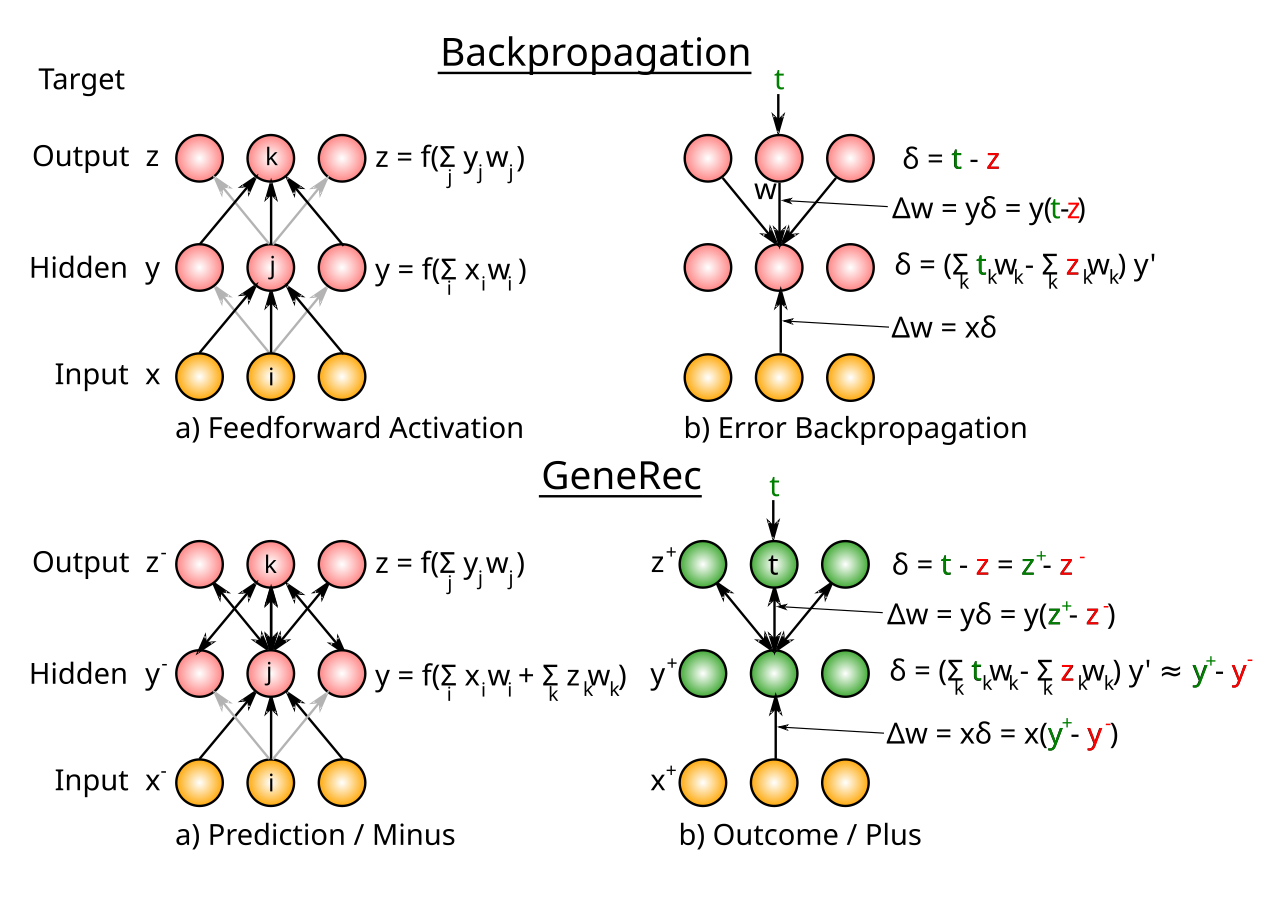
[[#figure_generec-bp]] は、GeneRec が [[error backpropagation]] アルゴリズムとどのように比較されるかを示します (必要な背景については、そのページを参照してください)。重要な結果は、バックプロパゲーションによる $\delta$ 誤差勾配値が、プラス $-$ マイナス位相活性化差によって厳密に近似できることです。この近似を適用すると、学習ルールは逆伝播 ($x \delta$) の場合と同じになります。簡略化のために学習率係数 $\epsilon$ を省略します。
{id=”eq_generec-dw” title=”GeneRec デルタ学習ルール”} \(\デルタ w = x^- \デルタ \おおよそ x^- \left(y^+ - y^- \right)\)
[[#figure_generec-bp]] で伝えられる中心的な直感は、隠れユニットの逆伝播における $\delta$ 値 (上のパネル) が 2 つの別個の正味入力のような合計係数で構成されており、1 つはターゲット アクティベーション $t_k$ の出力ユニットを持ち、もう 1 つはその「予測」アクティベーション $o_k$ を持つ出力を持っています。これらと同じ要素は、出力層からトップダウンの投影を受け取る双方向接続ネットワークにも自然に存在します。
隠れニューロンは入力層からボトムアップ入力も受信しますが、これらは一定であるため、プラス $-$ マイナス位相アクティベーションを減算すると、これらは相殺されます。さらに、2 つのアクティベーション状態を減算すると、$\delta$ 方程式の重要な要素であるアクティベーション関数の導関数が暗黙的に計算されます。
[[#figure_generec-bp]] で強調されているもう 1 つの重要な違いは、GeneRec ネットワークのみがプラス フェーズで結果の「経験」を反映するアクティベーション状態を持っていることです。逆伝播ネットワークでは、目標/結果の状態は誤差勾配で「仮想的に」のみ表現されます。私たちが明らかに学習を形作る結果を経験していることを考えると、これは、結果の状態をネットワーク アクティビティとして表現することによる [[optimized representations]] の利点に加えて、誤差逆伝播に関するもう 1 つの重大な妥当性の問題です。
重みの対称性
注意深い観察者なら、バックプロパゲーションに対する GeneRec の近似は、ボトムアップの重みと_対称_であるトップダウンの重みに依存していることに気づいたかもしれません。そのため、出力に対する隠れニューロンの影響は、出力から隠れへの相互経路によって推定できます。これと同じ種類の対称制約が [[Boltzmann machine]] に適用され、ホップフィールド ネットワーク ([[@Hopfield95]]) のような全体的なエネルギー関数の適用にも適用されます。興味深いことに、[[@^GallandHinton91]] は、フィードフォワード経路とフィードバック経路の間の接続の欠落というかなり重大なレベルの非対称性であっても、ボルツマン マシンの決定論的バージョンでは学習を妨げないことを発見しました。
ただし、そのモデルは対称学習ルール (対照ヘビアン学習、CHL) を使用していましたが、[[#eq_generec-dw]] の GeneRec 学習ルールは対称ではありません。つまり、x 値と y 値を交換すると、同じではなくなります。興味深いことに、CHL 学習ルールは、(この方程式の両方向を加算することにより) 対称であり、送信ニューロン アクティビティのマイナスとプラスの位相状態の平均を使用する [[#eq_generec-dw]] の修正バージョンから生まれます。この後の変更は次のようになります。
{id=”eq_generec-mid” title=”中間点の学習”} \(\Delta w = \frac{1}{2} \left(x^- + x^+\right) \left(y^+ - y^- \right)\)
および [[@^OReilly96]] は、これが数値積分の中点法 (二次ルンゲ クッタ法とも呼ばれる; [[@PressFlanneryTeukolskyEtAl88]]) の効果的な応用であることを示しました。この分析と一致して、このバージョンの学習ルールを使用すると、[[#eq_generec-dw]] よりも全体的に学習が高速になります。
このバリアントを調査するというアイデアは、GeneRec の 2 つのフェーズにわたって送信ニューロンごとに 2 つの活性化状態があり、どちらがより適切に機能するかが明確ではなかったため生まれました。数学的には、バックプロップは [[#eq_generec-dw]] に示されているようにマイナス フェーズ状態を効果的に使用します (マイナス フェーズのアクティベーションしかないため)。ただし、プラス フェーズの値は正しい予測が行われたアクティビティを表すため、概念的には「より正確」です。中点法は、差を効果的に分割し、以前の積分値と「より正確な」積分値の間の中間点を取得します。
対称性の維持とこの中点法を組み合わせると、次の方程式が得られます。
{id=”eq_generec-sym-mid” title=”中点と対称性”} \(\Delta w = \frac{1}{2} \left[ \left(x^- + x^2\right) \left(y^+ - y^- \right) + \left(y^- + y^2\right) \left(x^+ - x^- \right) \right]\)
これは CHL 方程式に簡略化されます。
{id=”eq_generec-chl” title=”GeneRec CHL”} \(\デルタ w = \left(x^+ y^+\right) - \left(x^- y^- \right)\)
| 注目すべきことに、この同じ CHL 方程式は複数の異なる開始仮定 ([[Boltzmann machine]]、[[@MovellanMcClelland93]]) から導出でき、2 つの [[Hebbian learning | Hebbian]] 学習係数の差にすぎない魅力的に単純な方程式です。 |
この CHL 方程式は対称であるため、実際には初期の非対称重みが時間の経過とともに対称値に向かう傾向があり、[[Leabra]] モデルでの GeneRec 学習による広範な実験により、ランダムな初期重みの非対称性に対する顕著なロバスト性が示されました。したがって、これは大きな懸念事項ではないようです。
決定論的ボルツマンマシンとの関係
単純なシグモイド ロジスティック活性化関数と上記の CHL 学習ルールを使用する GeneRec ネットワークは、1990 年代初頭に一連の論文で検討された [[Boltzmann machine]] (DBM) の決定論的バージョンと数学的に同等です ([[@GallandHinton90]]、[[@GallandHinton91]]、[[@Galland93]])。このモデルは、統計物理学の標準的な手法である平均場近似を適用することにより、元の確率的ボルツマン マシン (SBM) ([[@AckleyHintonSejnowski85]]) から導き出すことができます。
当初は、大規模な統計サンプリングの必要性を回避することで、SBM の重大な計算上の制限の一部を克服できるのではないかと考えられていましたが、その後の結論は、連続的な [[rate-code activation]] 状態により、SBM の数学的解析に必要な理想的な熱平衡から大きく逸脱したアトラクター状態でネットワークが「スタック」するというものでした。実際には、このモデルは複数の隠れ層を持つより深いネットワークではうまく機能しませんでした。
しかし、CHL 学習ルールのバージョンを使用した [[Leabra]] モデルの広範な研究により、この制限は、プールされた [[inhibition]] (ニューロンをより線形で敏感な活性化範囲に維持する) と、ボトムアップ経路と比べてトップダウン経路の強度を系統的に低下させることによって、ある程度克服できることが示されました。これは、これらのトップダウンの期待に基づいてモデルが過度に「幻覚」を起こすのを防ぐために重要です。 ([[neuron dendrites]])。
それにもかかわらず、レート コードのアクティベーションがすべてのタイム ステップで継続的にブロードキャストされるという事実により、過度に強力な [[attractor dynamics]] が発生する傾向があり、[[Axon]] での離散スパイキング ニューロンの使用により、学習の行き詰まりの問題がさらに減少しました。実際、離散スパイクは元の SBM モデルに存在する確率性により似ていますが、Axon で [[stable activation]] 状態を提供する追加メカニズムにより、合理的な平衡状態に収束する点で SBM よりも効率的になります。これは古典的な「両方の長所」ソリューションです。
これらの同じアトラクター ダイナミクスの問題は、アルメイダ-ピネダ (AP) モデル ([[@Almeida87]]; [[@Pineda88]]) や、任意の時間シーケンスを学習できる、より一般的なバックプロップスルータイム (BPTT; [[@Werbos88]]; [[@Werbos90]]) など、エラー逆伝播ネットワークの反復バージョンにも影響します。これらのアルゴリズムはいずれも、計算コストが高く、一般に実際にはあまりうまく機能しないため、広く使用されていません (ただし、[[@LiaoXiongFetayaEtAl18]] は AP モデルにいくつかの改良を加えています)。 [[@^OReilly96]] の AP の調査では、このモデルが DBM / プレーン GeneRec と同じ種類の過剰なアトラクター ダイナミクス問題に悩まされていることは明らかであり、これらのアルゴリズム間の強い数学的関係を考慮すると、これは理にかなっています。
[[@^LinsleyAshokGovindarajanEtAl20]] の最近のフレームワークは、BPTT のより一般的な柔軟性と AP のより制限されたアトラクター ダイナミクスの間の学習をパラメーター化する方法を提供します。実際、彼らは、このパラメーターがスペクトルの AP の端に非常に近い (完全ではない) 場合に、一連の連続視覚処理タスクでモデルが最もよく機能することを発見しました。これは、GeneRec によって実行される、より制約されたアトラクターベースの学習が一般に有益である可能性が高いことを示唆していますが、完全に十分ではありません。重要なことに、Axon で使用される [[predictive learning]] フレームワークは、双方向接続によって課せられる基本的なアトラクター ダイナミクスに加えて、追加の時間コンテキスト状態を提供し、この制約された組み合わせは、困難なシーケンス学習問題を解決するために実際にうまく機能します。
数学的な詳細
完全を期すために、このセクションでは、誤差逆伝播からの GeneRec の導出を示す [[#figure_generec-bp]] に示されている式を順を追って説明します。重要なステップは、バックプロパゲーションの隠れユニットの $\delta$ 値の式を再配置することです。これは次のとおりです。
{id=”eq_bp-delta” title=”逆伝播デルタ”} \(\delta_j = \left( \sum_k (t_k - z_k) w_k \right) y'\)
出力層の誤差勾配の合計 ($t_k - z_k$) は、出力が状態 $t_k$ の場合と、出力が状態 $z_k$ の場合の 2 つの個別の合計に再配置できます。
{id=”eq_bp-sep” title=”分離されたデルタ”} \(\delta_j = \left( \sum_k t_k w_k - \sum_k z_k w_k \right) y'\)
重要な洞察は、これらの個別の要素が、プラスフェーズとマイナスフェーズで、双方向に接続された隠れユニットへの正味入力に存在することを認識することです。
{id=”eq_gr-plus” title=”プラスフェーズ netinput”} \(\eta_j^+ = \sum_k t_k w_k + \sum_i x_i w_i\)
{id=”eq_gr-minus” title=”マイナスフェーズ netinput”} \(\eta_j^- = \sum_k z_k w_k + \sum_i x_i w_i\)
入力層からの定数入力は、これらの項の減算で相殺され、$\delta_j$ 項の核部分が残ります。
{id=”eq_gr-p-m” title=”プラス - マイナス ネット入力”} \(\eta_j^+ - \eta_j^- = \sum_k t_k w_k - \sum_k z_k w_k\)
{id=”figure_generec-act-diff” style=”高さ:20em”}
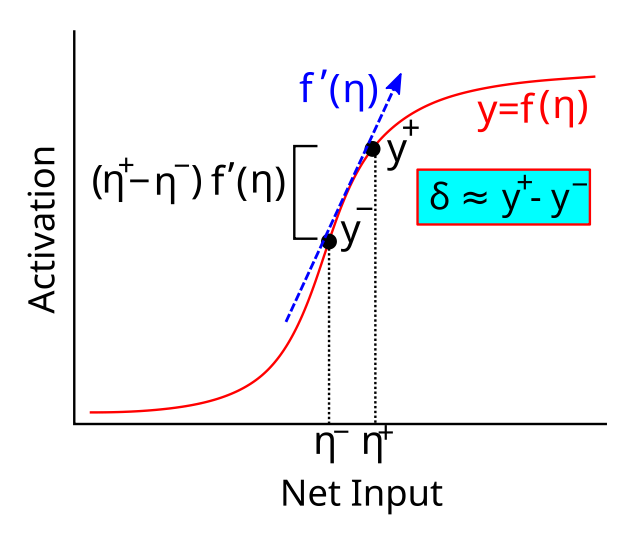
$\delta_j$ を取得するために必要な最後のステップは、[[#eq_bp-sep]] 内の活性化関数 $y’$ の導関数の存在を考慮することです。微積分の基本原理 ([[#figure_generec-act-diff]]) を使用すると、2 つの異なる点で評価された関数の差は、2 つの点の差と関数の導関数の積として近似できることがわかります。
{id=”eq_calc” title=”微積分近似”} \(f(a) - f(b) \近似 f'(a) (a-b)\)
これをすべてまとめると、$\delta$ 誤差勾配の重要な GeneRec 近似が得られます。
{id=”eq_bp-sep” title=”GeneRec デルタ”} \(\delta_j = \left( \sum_k t_k w_k - \sum_k z_k w_k \right) y' \おおよそ y_j^+ - y_j^-\)
[[#eq_bp-sep]] で活性化状態の差を使用することの重要な実用上の利点は、活性化関数の導関数が暗黙的に計算されるため、この導関数に対する明示的な方程式の必要性が回避されることです。これは、広範なプールされた阻害のコンテキストで動作する Leabra および Axon ([[neuron]]) で使用される生物学に基づく活性化関数の複雑さを考慮する場合に重要です。