compcogneuro/web: hebbian-learning
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/hebbian-learning.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Learning”, “Computation”] bibfile = “ccnlab.json” +++ 有名なカナダの心理学者ドナルド O. ヘブは、機能レベルで学習がどのように機能するかを考えるだけで、発見の何年も前に NMDA チャネルの性質を予測しました。重要な引用文は次のとおりです ([[@Hebb49]])。
残響活動 (または「痕跡」) の持続または繰り返しが、その安定性を高める永続的な細胞変化を誘発する傾向があると仮定しましょう。… 細胞 A の軸索が細胞 B を興奮させるのに十分近くにあり、繰り返しまたは持続的にその発火に関与すると、一方または両方の細胞で何らかの成長プロセスまたは代謝変化が起こり、B を発火する細胞の 1 つとして A の効率が増加します。
これは、_一緒に発火し、一緒に配線するセル_としてより簡潔に要約できます。 [[synaptic plasticity]] で詳しく説明したように、[[neuron channels#NMDA]] チャネルは、$Ca^{++}$ が学習に入って学習を促進できるようにするためにシナプス前とシナプス後の両方の活動を必要とするため、このプロセスには不可欠です。神経発火の_一致_を検出できます。興味深いことに、ヘブは、誰かがヘブの学習原理がNMDA受容体の形で発見されたと告げられたとき、「大したことだ、もうそうなるはずだと分かっていた」という趣旨のことを言ったとされている。
数学的には、ヘビアン学習は次のように要約できます。
{id=”eq_hebb” title=”ヘブ語の基本学習”} \(\デルタ w \プロプト xy\)
ここで、$\Delta w$ は、送信アクティビティ x と受信アクティビティ y の関数としてのシナプス重み w の変化です。この式のみを使用し、活動値が生物学的に現実的な発火率 (正の数のみ) である場合、シナプスの重みの値は増加するだけです。したがって、この場合、よりバランスの取れた重量増加 (LTP) と重量減少 (LTD) のパターンを生成するには、いくつかの追加要素が必要です。そのような要因のいくつかを以下で検討します。
しかし、バランスのとれた形式のヘビアン学習や、広く研究されているヘビアン学習の変種である [[synaptic plasticity#spike timing dependent plasticity]] (STDP; [[@BiPoo98]]) を含めたとしても、主な問題は、人間や他の動物が示す種類の認知機能や行動機能をニューロンのネットワークが実際に学習できるようになると期待できる数学的または計算的根拠がないことです。これは、直感的に理解できる単なる「ヒューリスティック」原理ですが、入手可能な証拠はすべて、[[error-driven learning]] メカニズムの汎用的な柔軟性が欠けていることを強く示しています。ヘビアン学習とエラー駆動学習の違いを示す簡単な例については、[[pattern associator simulation]] および [[hidden layer simulation]] を参照してください。
数学レベルでのヘビアン学習と誤差駆動学習の違いは、方程式内にある種の「差分ベース」要素が存在するかどうかに帰着します。この要素は、単なる生の関連性の「主効果」ではなく、2 つの要素間の「コントラスト」に基づいて学習を推進します。たとえば、[[error-backpropagation]] 学習の [[GeneRec]] バージョンでは、もともと [[Boltzmann machine]] で開発された 対照ヘビアン学習 (CHL) 方程式が生成されます ([[@MovellanMcClelland93]] も参照)。
{id=”eq_chl” title=”対照的なヘブ語学習”} \(\Delta w \propto (x^+ y^+) - (x^- y^-)\)
これは、[[#eq_hebb]] のような 2 つのヘビアン因子間の違いにすぎないことがわかります。ここで、上付き文字 + は、正解が存在する場合の プラス フェーズ の神経活動を示し、- は、ネットワーク内の既存のシナプス重みに基づいて、ネットワークが独自の答えを生成している マイナス フェーズ を示します。 [[predictive learning]] のコンテキストでは、マイナス フェーズはプラス フェーズの直前にあり、何が起こるかを予測し、その後に実際に何が起こるかを予測します。
この CHL 方程式は、Axon で使用される実際の [[kinase algorithm]] 方程式の有用な定性的要約を提供し、ヘビアン連合学習の直感的な核心と NMDA 受容体の事前事後偶然性がすべて、より強力な計算能力を持つエラー駆動学習領域にどのように引き継がれるかを示しています。
さらに、[[Leabra]] アルゴリズムの中心的な前提は、非常に少量のヘビアン学習をこの CHL ベースのエラー駆動学習と組み合わせることができるということです。この場合、ヘビアン係数は、統計的規則性をエンコードするための学習を形成する一種の「バイアス」または「正則化係数」として機能します (一般原則については、[[bias-variance tradeoff]] を参照)。これは、[[abstract neural network]] モデルや統計回帰で使用される [[weight decay]] に似ていますが、ヘビアン学習では重み値がゼロに向かって減衰するだけでなく増加する点が異なります。
興味深いことに、軸索の離散スパイキングダイナミクスに存在する固有のノイズは、Leabra に追加された追加のヘビアン コンポーネントと同じ効果の多くを生成します。したがって、主要なエラー駆動学習に加えてヘビアン コンポーネントを追加することは不必要 (そして有益ではない) であることがわかりました。
実装された軸索モデルでまだ調査されていない仮説の 1 つは、[[neocortex]] の層 4 が、一次感覚野で視床からボトムアップの感覚入力を受け取り、これらの感覚入力の「前処理」の主にヘブ型形式を実行するというものです。層 4 には、別のクラスの興奮性ニューロンである星状細胞 (他の層の主要な錐体ニューロンに対して) があり、より局所的な接続パターンがあり、主に表層 2/3 へのフィードフォワード出力があります。これらの特徴はすべて、入力信号に対して何らかの形で有用な変換を実行する局所的な処理段階を示唆しています。一次視覚野 (V1) 感覚入力に適用されるこの形式の処理の例については、[[V1 self organizing simulation]] を参照してください。
このページの残りの部分では、ヘビアン学習のさまざまな標準形式をレビューし、このタイプの学習で何が達成できるかを理解するための基礎を提供します。
抑制的な競争による自己組織化
隠れ層内のニューロン間のさまざまな形式の [[inhibition]] とヘビアン学習を組み合わせた、自己組織化モデルが多数あります。抑制性競合により、個々のニューロンは、すべてのニューロンが同じことを学習するのではなく、入力環境の異なる「分離可能な特徴」のエンコードに「特化」するように強制されます。比喩的に言えば、抑制は進化における適者生存のようなものです。与えられた一連の入力刺激に最もよく反応するニューロンが、そのような入力を表現する競争に勝ち、最終的に空間全体のそのサブセットでのエンコーディングをさらに特殊化することになります。
抽象的な数学レベルでは、[[principal components analysis]] (PCA) メソッドは、入力に潜在する最も重要なコンポーネントをエンコードする新しいより効率的かつ体系的な方法を開発することにより、これらのアルゴリズムが達成できることの良い例を提供します。 PCA は入力信号間の_相関_を抽出し、ヘビアン学習がどのように入力の_相関構造_を学習するように同様に駆動されるかを示します。
このタイプの初期のモデルのいくつかは、Teuvo Kohonen らによって開発されました ([[@Kohonen77]]、[[@Kohonen98]]、[[@KohonenHari99]])。これらの_自己組織化マップ_ (SOM) モデルでは、ヘビアンのような反復学習と単純な形式の抑制的競争により、隠れ層の 2D ジオメトリ全体にわたって組織化された、入力空間内のフィーチャの_トポグラフィック マッピング_が生成されます。この種の地形図は、[[neocortex]] の主要な感覚領域で十分に確立されています。たとえば、一次視覚野 (V1) には、[[@HubelWiesel62]] がノーベル賞を受賞した研究で最初に発見したように、エッジ検出器の異なる方向角をコード化するニューロンのトポグラフィー構成があります ([[V1 self organizing simulation]] を参照)。
SOM モデルは、現在の入力から最大量の「興奮」を受けた個々のニューロンを選択することによって抑制性競合を実装します。これは通常、ドット積ではなく、シナプスの重みと入力アクティビティ ベクトルの間の最小距離の観点から計算されます。このニューロンは、各ニューロンが経験する学習量を定義する活動のガウス形状の「バンプ」の中心点として使用され、中心の最も適合するニューロンからの 2D 距離の関数として減少します。次のヘビアン学習方程式が使用されます。
{id=”eq_som_dwt” title=”SOM 学習ルール”} \(\Delta w_{ij} \propto y_j (x_i - w_{ij})\)
ここで、$y_j$ は受信ニューロン $j$ のガウス型バンプ アクティビティ、$x_i$ は入力ニューロン $i$ のアクティビティ、$w_{ij}$ は 2 つのニューロン間のシナプス重みです。
この学習ルールは、協働ニューロン間の重みを単に増加させるのではなく、入力アクティビティ パターンに一致するようにシナプスの重みを移動します。したがって、それらの違いに基づいて増加と減少 (LTP と LTD) が生じます。それにもかかわらず、純粋に入力アクティビティによって駆動され、エラー信号が含まれないという点で、本質的には依然として Hebbian です。以下で説明するアルゴリズムで、関連する学習形式を見ていきます。詳細については、ウィキペディアの SOM ページ を参照してください。
[[@^RumelhartZipser85]] の競合学習モデルとその後のソフト競合学習モデル ([[@Nowlan90]]; [[@NowlanHinton93]]) は、受信ニューロン間の強力な競合によって学習を推進するという点で SOM に似ていますが、活動のガウス バンプによって課せられる 2D トポグラフィーを無視し、より任意の高次元表現を学習します。これらのタイプのモデルが線要素で構成される単純な環境の相関構造を抽出する方法の例については、[[self organizing simulation]] を参照してください。
[[@^BednarMiikkulainen03]] および [[@^Bednar12]] のモデルは、一次視覚野に適用されるこの自己組織化学習プロセスの生物学的に詳細なモデルを提供します (関連モデルについては [[V1 self organizing simulation]] を参照)。
BCM
{id=”figure_bcm” style=”高さ:10em”}
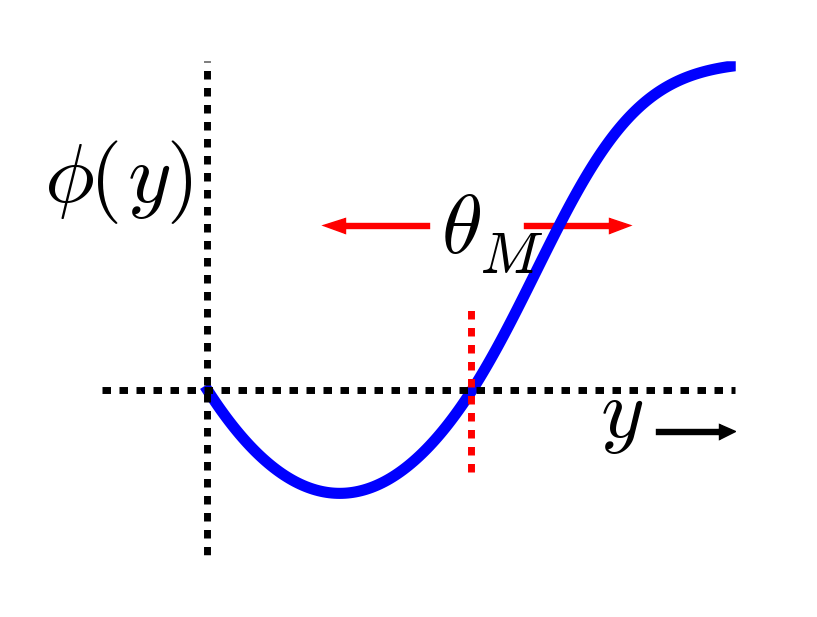
Hebbian 自己組織化学習の BCM ([[@BienenstockCooperMunro82]]) バージョンでは、異なるアプローチを使用して、直接的な抑制的競争と同様の効果を達成します。具体的には、受信ニューロンの平均アクティビティ ([[#figure_bcm]]]) の関数として、重量減少 (LTD) と重量増加 (LTP) の間のバランスをシフトする動的な浮動しきい値を使用することで、各受信ニューロンを一貫した平均アクティビティ レベルに維持する_ホメオスタティック_メカニズムを使用します ([[#figure_bcm]]])。ニューロンの活動が比較的高い場合、LTP よりも LTD が多くなり、その結果活動が低下し、活動レベルが低い場合はその逆になります。
{id=”figure_bcm-dark” style=”高さ:20em”}
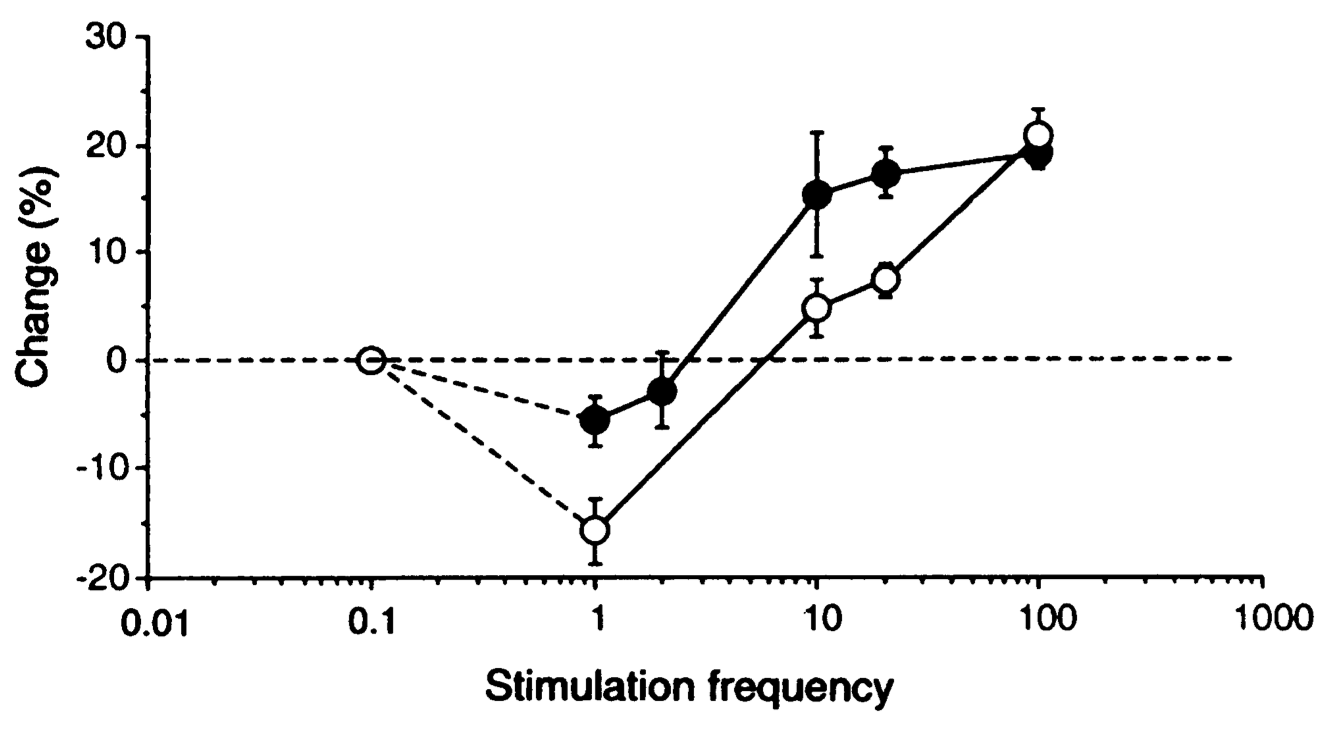
ランダムな初期重みをシードすると、この恒常性メカニズムにより、上記のアルゴリズムでの直接抑制性競合と同様に、個々のニューロンが入力空間の特定のサブセットに特化します。直接プールされた [[inhibition]] が [[neocortex]] の活動の形成に主要な役割を果たしていることは明らかですが、恒常性のようなメカニズムの証拠もあります。たとえば、[[#figure_bcm-dark]] は、LTP と LTD の相対しきい値が全体的なアクティビティ ([[@KirkwoodRioultBear96]]) の関数として変化することを示しています。
Axon アルゴリズムでは、[[@^TorradoPachecoBottorffGaoEtAl21]] で説明されている睡眠ベースのシナプス再構成メカニズムのバージョンを使用します。これは、各ニューロンの個別の目標平均活性化レベルに従って、日中に学習されたシナプスの重みを再スケールします ([[kinase algorithm#Slow weights]] を参照)。これは、BCM アルゴリズムと同様の恒常性特性を備えており、個々のニューロンが表現空間を「独占」するのを防ぐために重要です。 [[Leabra]] アルゴリズムは、BCM アルゴリズムのバージョンを使用してこの機能を実行し、ヘビアン学習の正則化効果を促進します。
Hebbian は相関関係を学習します
{id=”figure_hebb-demo” style=”height:20em”}
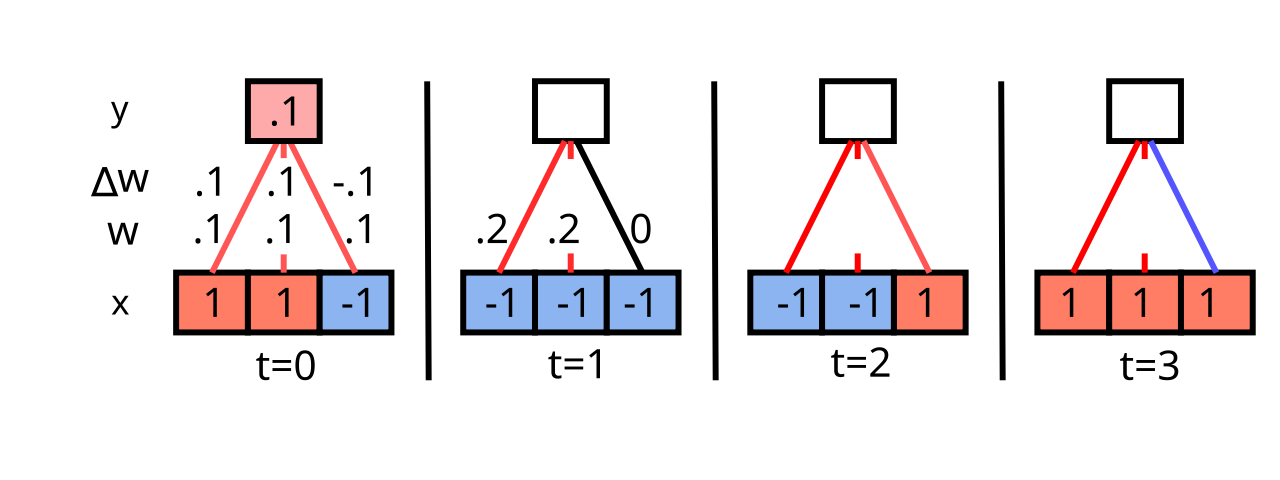
[[#figure_hebb-demo]] は、ヘビアン学習によって受信ネットワークが入力ユニットのアクティブ化パターンの相関関係を発見する方法を示す簡単なデモンストレーションです。相関付けられた入力ユニットは最終的に受信ユニットのアクティビティを支配することになるため、受信ユニットは相関入力のこのサブセットと相関付けられることになり、ヘビアン学習関数の下でその重みが常に増加します。 Uncorrelated inputs bounce around without a systematic trend.続行すると、重みが際限なく急速に増加することがわかります。そのため、これは実用的な学習関数ではありませんが、ヘビアン学習の本質を示しています。
次に、ヘビアン相関学習の最も単純なバージョンでは、入力ユニットのセットから入力を受信する単一の線形受信ユニットの場合、ユニットが入力ユニットにわたるアクティビティのパターンにおける相関の最初の主成分を抽出する結果となることを示すためにいくつかの数学を実行します。
線形であるため、受信ユニットのアクティベーション関数は、その入力の加重和、つまり、ドット積 ([[linear algebra]] を参照) にすぎません。
{id=”eq_linact” title=”線形活性化関数 (ドット積)”} \(y_j = \sum_k x_i w_{ij}\)
(すべての変数は暗黙的に、さまざまな入力を反映する現在のタイム ステップ $t$ の関数です)。体重の変化は以下の通りです。
{id=”eq_demo_dwt” title=”ヘブ語学習”} \(\Delta_t w_{ij} = \epsilon x_i y_j\)
ここで、$\epsilon$ は_学習率_、$i$ は特定の入力ユニットのインデックスであり、重みは時間の経過とともにこれらの変化を増加させるだけです。
{id=”eq_demo_wt” title=”ヘビアン学習重み更新”} \(w_{ij}(t+1) = w_{ij}(t) + \Delta_t w_{ij}\)
多くのパターンにわたる学習の総合的な効果を理解するには、時間の経過に伴う変化を合計するだけです。
{id=”eq_sum_dwt” title=”時間の経過に伴う合計体重変化”} \(\Delta w_{ij} = \epsilon \sum_t x_i(t) y_j(t)\)
$\epsilon = 1 / N$ ($N$ は入力内のパターンの総数) を設定すると、合計は average になります。
{id=”eq_avg_dwt” title=”平均体重は時間の経過とともに変化します”} \(\デルタ w_{ij} = \langle x_i y_j \rangle_t\)
次に、この式に $y_j$ の式を代入します (ここでは入力インデックスに $k$ を使用します)。これは、重みの変化が入力単位間の_相関_の関数であることを示します。
{id=”eq_correl” title=”相関学習”} \(\Delta w_{ij} = \langle x_i \left(\sum_k x_k w_{kj} \right) \rangle_t\)
\[= \sum_k \langle x_i x_k \rangle_t \langle w_{kj} \rangle_t\] \[= \sum_k \bf{C}_{ik} \langle w_{kj} \rangle_t\]この新しい変数 $\bf{C}{ik}$ は、2 つの入力ユニット $i$ と $k$ の間の *相関行列* の要素です。ここでの相関は、時間の経過に伴うアクティビティ値の積 ($\bf{C}{ik} = \langle x_i x_k \rangle_t$) の期待値 (平均) として定義されます。 あなたは、より標準的な相関測定に精通しているかもしれません。
{id=”eq_correl_norm” title=”相関定義”} \(\bf{C}_{ik} = \frac{\langle (x_i - \mu_i)(x_k - \mu_k) \rangle_t} {\sqrt{\sigma^2_i \sigma^2_k}}\)
これは、積を求める前に変数の平均値 ($\mu$) を減算し、結果を分散 ($\sigma^2$) で正規化します。 したがって、この形式のヘビアン相関学習における重要な単純化は、活性化変数の平均と単位分散がゼロであると仮定していることです。
これらすべてが意味するのは、入力単位間に強い相関が存在する場合、この平均相関値が比較的大きくなるため、それらの単位の重みが増加するということです。興味深いことに、この学習ルールを十分に長く実行すると、重みは入力に存在する最も強い相関セットによって支配されるようになり、最も強いセットと次に強いセットとの間のギャップがますます大きくなります。 したがって、この単純なヘビアン規則は、入力データの 最初 (最も強い) 主成分を学習します。
減算正規化
単純なヘビアン学習ルールの大きな問題は、学習が続くと重みが無限に大きくなることです。この問題に対する 1 つの解決策は、[[@^Oja82]] によって提案され、_減算正規化_として知られています。
{id=”eq_sub_norm” title=”減算正規化”} \(\デルタ w_{ij} = \epsilon (x_i y_j - y^2_j w_{ij})\)
各シナプス重みの更新からこの特定の値を減算すると有用な結果が得られる理由を確認するには、方程式を 0 に設定し、変化がなくなったときに得られる equilibrium または asymptotic の重み値を求めることができます。
{id=”eq_eq” title=”平衡重み”} \(0 = \epsilon (x_i y_j - y^2_j w_{ij})\)
\[w_{ij} = \frac{x_i}{y_j}\] \[w_{ij} = \frac{ x_i}{\sum_k x_k w_{kj}}\]したがって、特定の入力ユニットからの重みは、他のすべての入力に対する重み付けされたアクティベーションの合計に対するその入力のアクティベーションの割合を表すことになります。これにより、重量が際限なく増加することがなくなります。最後に、前の単純なヘビアン学習ルールと同じ相関項 $\bf{C}_{ik}$ に主に基づいているため、この Oja ルールは引き続き入力データの第 1 主成分を計算します (ただし、この証明は多少複雑です。優れた処理については [[@^HertzKroghPalmer91]] を参照してください)。
単一の隠れユニットを超えて、ユニットが相関行列の PCA 値のシーケンスを固有値順 ([[@Sanger89]]; [[@Oja89]]) で学習するように抑制を構成する方法があります。
条件付き PCA
[[@^OReillyMunakata00]] では、条件付き主成分分析 または CPCA として知られる別の代替方法を開発しました。これは、受信ユニット ($y_j$) もアクティブであることを前提として、特定の入力ユニットの重みが入力ユニット ($x_i$) がアクティブであったという条件付き確率を表すことを前提としています。
{id=”eq_cpca_wt” title=”CPCA 重み”} \(w_{ij} = P(x_i = 1 | y_j = 1)\)
\[w_{ij} = P(x_i | y_j)\]ここで、2 番目の形式では、以下でも引き続き使用される簡略化された表記が使用されます。
CPCA の重要な特性は、受信ユニットによって表される入力パターンのサブセット全体にわたって特定の入力ユニットがアクティブである (つまり、この受信ユニットに条件付けされている) 範囲を重みが反映することです。特定の入力パターンがそのような入力の典型的な側面である限り、その重みは大きく (1 に近く)、それほど典型的でない場合は小さくなります (0 に近く)。
[[@^RumelhartZipser85]] の分析に続いて、CPCA 学習ルールは次のように導出されます。
{id=”eq_cpca_dwt” title=”CPCA 学習ルール”} \(\デルタ w_{ij} = \epsilon [y_j x_i - y_j w_{ij}]\)
\[= \epsilon y_j (x_i - w_{ij})\]この方程式の 2 つの等価な形式は、この学習ルールと Oja の正規化 PCA 学習ルールの類似性を強調するために示されています。また、その単純な形式も示しています。これは、送信ユニットのアクティブ化 $x_i$ の値に一致するように重みが調整され、受信ユニットのアクティブ化に比例して重み付けされる (つまり、$x_i$ と $w_{ij}$ の差を最小化する) ことを強調します。 ($y_j$)。 この形式は、SOM 学習ルール [[#eq_som_dwt]] と同じです。
| 次に、この学習ルールが [[#eq_cpca_wt]] の CPCA 重み値を生成することを示します。式 $P(y_j | t)$ は、特定の入力パターン $t$ が提示された場合に、受信ユニット $y_j$ がアクティブである確率を表すために使用されます。 $P(x_i | t)$は送信ユニット$x_i$に対応するものを表します。これらを学習ルールに代入すると、考えられるすべてのパターン $t$ に対して計算された合計重み更新 (および各パターンが発生する確率 $P(t)$ を乗算) は次のようになります。 |
{id=”eq_cpca_dwt_sum” title=”CPCA 合計体重変化”} \(\Delta w_{ij} = \epsilon \sum_t [P(y_j | t) P(x_i | t) - P(y_j | t) w_{ij}] P(t)\)
\[= \epsilon \left( \sum_t P(y_j | t) P(x_i | t) P(t) - \sum_t P(y_j | t) P(t) w_{ij} \right)\]いつものように、$\Delta w_{ij}$ をゼロに設定し、均衡の漸近重み値を求めるために解決します。
{id=”eq_cpca_wt_eq” title=”CPCA 均衡ウェイト”} \(w_{ij} = \frac{\sum_t P(y_j | t) P(x_i | t) P(t)} {\sum_t P(y_j | t) P(t)}\)
興味深いことに、分子は、すべてのパターン $t$ にわたって、送信ユニットと受信ユニットの両方が同時にアクティブになる同時確率の定義であり、これはまさに $P(y_j, x_i)$ です。同様に、分母は、受信ユニットがすべてのパターンにわたってアクティブである確率、つまり $P(y_j)$ を与えます。したがって、前述の式を次のように書き換えることができます。
{id=”eq_cpca_wt_eq2” title=”CPCA 均衡ウェイト”} \(w_{ij} = \frac{P(y_j, x_i)}{P(y_j)}\)
\[w_{ij} = P(x_i | y_j)\]この時点で、受信者の確率に対する結合確率のこの部分が、受信者を与えられた場合の送信者の条件付き確率の定義にすぎないことが明らかになります。
CPCA は効果的で数学的に明確に定義されていますが、大きな問題が 1 つあります。それは、送信ニューロンがアクティブではなく、受信ユニットがアクティブであるときに、大幅な LTD (重みの減少) を引き起こすということです。これは、時間の経過とともに学習にかなりの量の干渉をもたらし、Ca++が入って[[synaptic plasticity]]を駆動できるようにするためのシナプス後神経活動の必要性と矛盾します。 このような理由から、[[Leabra]] アルゴリズムは、ヘビアン学習用に [[#BCM]] アルゴリズムのバージョンを使用するようになりました。受信ニューロンが非アクティブな場合、BCM は可塑性を駆動しません。