compcogneuro/web: kinase-algorithm
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/kinase-algorithm.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Learning”] bibfile = “ccnlab.json” +++ キナーゼ 学習アルゴリズムは、[[synaptic plasticity]] に関与する詳細な化学経路を抽象化したもので、これらの学習プロセスで中心的な役割を果たす CaMKII や DAPK1 を含む kinases によって媒介されます。このアルゴリズムは、互いに競合することが知られている、より速い CaMKII 媒介経路とより遅い DAPK1 媒介経路の間で計算された [[temporal derivative]] を介して [[error-driven learning]] を達成します ([[@GoodellZaegelCoultrapEtAl17]]; [[@GoodellTullisBayer21]]; [[@CookBuonaratiCoultrapEtAl21]]; [[@TullisBayer23]]; [[@BayerGiese25]])。
このアルゴリズムに関連する背景については、次のページで説明します。
-
[[Synaptic plasticity]] は、シナプスがその有効強度 (重量) をどのように変化させるか、およびこのプロセスに対するキナーゼの重要な貢献について、関連する神経科学をレビューします。
-
[[Temporal derivative]] は、高速経路と低速経路間の競合相互作用が誤差駆動学習の中心となる「誤差勾配」をどのように計算できるかについての対話型シミュレーションを含む、このアルゴリズムの背後にある重要な計算原理の概要を提供します。
-
[[GeneRec]] は、[[error backpropagation]] の数学から直接具体的な学習アルゴリズムを導き出します。このアルゴリズムは、[[bidirectional connectivity]] を使用して [[neocortex]] 全体に誤差勾配を伝播します。キナーゼ アルゴリズムは、計算レベルで同じ原理を活用しながら、より直接的に生物学に基づいたメカニズムを使用しており、計算された勾配にいくつかの重要な定量的な違いもあります。
-
[[Jang et al (2026)]] は、マウス CA1 領域で記録されたニューロンのシナプス可塑性の方向が時間微分仮説と一致することを示す最初の直接証拠を提示します。
-
[[OReilly (2026) Cortical Learning]] は、さまざまなレベルの分析にわたるアプローチの動機となる簡潔な概要を提供します。
ここでは、これらの基盤に基づいて、神経科学、計算効率、および計算コストからの制約を満たす試みを表す Axon モデルでの学習を実際に推進する詳細なメカニズムを説明します。
全体的なレベルでは、キナーゼ アルゴリズムの背後にある 2 つの中心的な考え方は次のとおりです。
-
シナプス可塑性の主要な初期ドライバーとして十分に確立されている [[neuron channels#NMDA]] および [[neuron channels#VGCC]] チャネルを介したシナプス Ca++ 流入を計算するには、生物物理学的に根拠のある方程式を使用します。 NMDA はシナプス前とシナプス後の活動の結合に敏感ですが、VGCC (電位依存性カルシウム チャネル) は、受信ニューロンから逆伝播する活動電位によって鋭い位相的に駆動されます。
-
単純な [[exponential integration]] ステップのカスケードを適用して、幅広いタスクにわたる計算パフォーマンスに基づいて最適化された時定数を使用して、この Ca++ 流入に続く複雑な生化学プロセスをシミュレートします。このカスケードの最後の 2 つのステップは、[[temporal derivative]] 計算を実装します。最後から 2 番目のより速いステップは LTP (重みの増加) を駆動し、最後の遅いステップは LTD (重みの減少) を駆動します。
この戦略は、十分に確立されている生物物理学的に制約されたメカニズムを活用する一方、後続の生化学プロセスの複雑さに対して、より抽象化された計算動機のアプローチを採用しますが、これらのプロセスは、よりボトムアップのアプローチをサポートするためにまだ十分に仕様化されていません。 [[temporal derivative]] の背後にある全体的なメカニズムは、[[synaptic plasticity]] で説明されているように、CaMKII および DAPK1 キナーゼの一般的な特性と関連メカニズム、および [[Jang et al (2026)]] の初期の経験的結果によって裏付けられています。
ただし、実用的な実装レベルでは、シナプスの数がニューロンの数を大幅に上回っていることを考えると (たとえば、完全接続モデルの $N^2$)、各シナプスの NMDA および VGCC 生物物理方程式に基づいて Ca++ 流入を個別に計算するのは非常にコストがかかります。 したがって、代わりに計算を 2 つのサブコンポーネントに分割します。
-
全体的な樹状突起膜電位と、NMDA および VGCC チャネル上の受信ニューロンから逆伝播する活動電位の寄与を反映する、樹状突起レベルの共有 Ca++ 値。
-
効率的に計算されたシナプス固有の乗数。これは、各シナプスにおける特定の同時シナプス前および後シナプス活動を反映します。
神経科学と計算の間の [[synergies]] の別の例では、これら 2 つの項は、誤差逆伝播学習ルールの 2 つの必須項 (エラー勾配係数とクレジット割り当て係数) に直接関連付けることができます。
{id=”eq_err-cred” title=”エラー * クレジット”} \(\Delta w \propto \rm{エラー} * \rm{クレジット}\)
これらは、$\delta$ および [[error backpropagation]] 内の送信装置アクティビティ $x$ の観点から具体的に表現されます。
{id=”eq_bp” title=”逆伝播”} \(\デルタ w \プロプト \デルタ x\)
キナーゼ アルゴリズムでは、Error 係数が樹状突起レベルの Ca++ から計算され、シナプス固有の乗数が Credit 割り当てを提供します。これら 2 つの因子の計算レベルの特性は、バックプロパゲーション バージョンと全体的に一致していますが、Axon フレームワークの離散スパイクの性質にとって有益な重要な違いもあり、ディープ ネットワークにおける勾配消失問題の軽減にも役立ちます。したがって、これら 2 つの異なる要因へのこの分離は計算コストの考慮によって動機付けられていますが、それにもかかわらず、NMDA および VGCC Ca++ 流入によって駆動される推定上の生物学に基づく学習メカニズムの機能的特性を理解するための有用な基礎を提供します。
1 サイクルあたり 1 ミリ秒のタイムスケールでニューラルダイナミクスをシミュレートする Axon モデルの連続時間の性質により、処理の各「試行」が展開されるまでに約 200 サイクルかかります ([[theta rhythm]] に相当)。キナーゼ アルゴリズムは、この 200 ミリ秒のウィンドウにわたるシナプス前およびシナプス後のスパイクの統計に基づいて、効果的な学習を推進するために情報がどのように蓄積されるかを説明します。
通常使用される [[predictive learning]] フレームワークでは、この時間枠には予測 (マイナス フェーズ) とそれに続く結果 (プラス フェーズ) の反復が含まれ、プラス フェーズの終わりに学習が行われます。生物学的に現実的な方法でこの学習を引き起こす可能性のある具体的なイベントについては、以下で説明します。学習プロセス (および環境の外部ダイナミクス) のこの時間的離散化とは別に、Axon の他のすべての方程式は時間の経過とともに継続的に動作し、実際の神経処理のリアルタイム モデルを提供します。
キナーゼ アルゴリズムには、より長いタイムスケールのシナプス プロセスも含まれており、これにより時間の経過に伴う学習の安定性が大幅に向上します (以下で詳しく説明します ([[#Stabilization and rescaling mechanisms]]))。これらのプロセスは、睡眠中に機能するものを含む、さまざまな神経科学メカニズムによって動機付けられます。
樹枝状 Ca++ による誤差勾配
シミュレートされたニューロンのすべての樹状突起にわたる全体的な Ca++ 流入は、[[neuron channels]] で説明されている生物物理学的に基づいた [[neuron channels#NMDA]] コンダクタンス モデルと、VGCC コンダクタンスの単純なスパイク駆動近似を使用して計算されます。 NMDA の寄与はコンダクタンスから始まります。
{id=”eq_nmda_g” title=”NMDA 電圧ゲート コンダクタンス”} \(g_{nmda}(t) = \frac{g_{e-raw}(t) \overline{g}_{nmda}}{1 + \frac{[Mg^{++}]}{3.57} e^{-0.062 V_d}} - \frac{1}{\tau_d} g_{nmda}(t-1)\)
ここで、$V_d$ は樹状膜電位 ([[neuron dendrites]] を参照)、$g_{e-raw}(t)$ 因子は [[neuron#Computing input conductances]] で説明されている生の興奮性シナプス入力であり、NMDA 受容体に結合して開く可能性があるシナプス前ニューロンから放出される総潜在的なグルタミン酸を反映しています。 [[abstract neural network]] モデル:
{id=”eq_ge-raw” title=”興奮性生グルタミン酸”} \(g_{e-raw}(t) = \frac{1}{n} \sum_i x_i w_i\)
NMDA コンダクタンスは、[[@^UrakuboHondaFroemkeEtAl08]] モデルの次の方程式を使用して Ca++ 流入レベルを駆動します (モデルの詳細 および [[@SabatiniOertnerSvoboda02]] を参照)。
{id=”eq_ca-nmda” title=”NMDA カルシウム”} \(\rm{Ca}_{nmda}(t) = \frac{- g_{nmda}(t) V_d}{1 - e^{0.0756 V_d}}\)
VGCC Ca++ 流入は、受信ニューロンのスパイク付近の非常に限定された時間枠で発生し、減衰係数 ($\tau_d = 10 ms$) を伴う単純なスパイク駆動インパルス関数を使用して効率的に計算できます。
{id=”eq_ca-vgcc” title=”VGCC カルシウム”} \(\rm{Ca}_{vgcc}(t) = \rm{スパイク} * 35 - \frac{1}{\tau_d} \rm{Ca}_{vgcc}(t-1)\)
得られる樹状 Ca++ 流入の合計は、これら 2 つの項の合計であり、正規化係数 (80) を使用すると、学習ルールで実際に適切に機能するほぼ正規化された値が得られます。
{id=”eq_ca-tot” title=”レシーバーベースの総カルシウム”} \(\rm{Ca}_{tot}(t) = \frac{1}{80} \left( \rm{Ca}_{nmda}(t) + \rm{Ca}_{vgcc}(t) \right)\)
キナーゼカスケード
[[synaptic plasticity]] で詳しく説明されているように、NMDA および VGCC チャネルを介した Ca++ イオンの流入は、他の分子および重要な結合ダイナミクスとともに、さまざまなキナーゼおよびホスファターゼを含む化学反応の複雑なカスケードを引き起こし、最終的には学習の最終結果である興奮性 AMPA 受容体の数と有効性の変化を引き起こします (これらのいくつかの詳細なモデルについては、[[Urakubo08 simulation]] を参照してください)プロセス)。
{id=”table_taus” title=”キナーゼの時間定数”} |パラメータ |値 | |———————|———-| | CaM $\tau_{cam}$ | 2ミリ秒 | |キャップ $\tau_{cap}$ | 40ミリ秒 | | CaD $\tau_{cad}$ | 40ミリ秒 | |シン$\tau_{syn}$ | 30ミリ秒 |
これらのプロセスを生物物理学的に詳細に大規模にシミュレートすることは計算上扱いにくいため (そして、これらのことが実際にどのように機能するかについてはまだ多くの不確実性があります)、生の Ca++ 流入による カルシウム カルモジュリン (CaM) の活性化から始まる [[exponential integration]] ステップ (時定数は [[#table_taus]] に示されています) のカスケードを含む単純な近似を使用します。
{id=”eq_cam” title=”CaM カルモジュリン”} \(\rm{CaM}(t) = \frac{1}{\tau_{cam}} \left( \rm{Ca}_{tot}(t) - \rm{CaM}(t) \right)\)
これにより、構造モデル ([[@BayerGiese25]]) に従って、CaMKII キナーゼが NMDA 受容体の GluN2B 結合部位に結合し、LTP (シナプス重量の増加) を駆動する程度を反映する「増強」因子が駆動されます。
{id=”eq_cap” title=”CaP 増強”} \(\rm{CaP}(t) = \frac{1}{\tau_{cap}} \left( \rm{CaM}(t) - \rm{CaP}(t) \right)\)
カスケードの最後の最も遅いステップは、DAPK1 キナーゼの活性化と CaMKII キナーゼの Thr305/306 部位での結合を反映する_depression_ 因子で、LTD (シナプス重量の減少) を駆動します。
{id=”eq_cad” title=”CaD うつ病”} \(\rm{CaD}(t) = \frac{1}{\tau_{cad}} \left( \rm{CaP}(t) - \rm{CaD}(t) \right)\)
[[temporal derivative]] フレームワークでは、CaP はより速い増強プロセスであり、CaD はより遅い抑制プロセスであり、この 2 つの減算によりバックプロパゲーション誤差勾配の近似値が得られます。
{id=”eq_kinase-delta” title=”キナーゼエラー勾配”} \(\デルタ \約 \rm{CaP} - \rm{CaD}\)
キナーゼ学習ルールは、以下に説明する Syn シナプス活動クレジット割り当て係数とともに、このデルタ係数を直接使用します。
{id=”eq_kinase-dw” title=”キナーゼ学習ルール”} \(\Delta w \propto (\rm{CaP} - \rm{CaD}) \rm{Syn}\)
上で述べたように、この学習ルールは、上記のすべての変数の 200 ミリ秒の反復更新後に適用されます。全体的なダイナミクスを把握するために、2 つの 200 ミリ秒の試行にわたって [[#figure_ca++-integration]] にプロットされています。
これらの係数の差のみを使用しているため、Ca++ バッファリング ダイナミクスのより詳細な説明など、一定のオフセット寄与を提供するさまざまな欠落コンポーネントに対して比較的堅牢であることに注意してください。また、CaP 上の CaD の直接カスケードは、Thr286 (増強を促進する) と Thr305/306 (抑制を促進する; [[@CookBuonaratiCoultrapEtAl21]]) での CaMKII 活性化の一時的な動態の一部を捉えていますが、DAPK1 活性を調節する独立した経路もありますが、それらは CaMKII を活性化するための CaM の直接結合よりも間接的であり、したがって全体的に遅くなる可能性があります。重要な機能特性です。
歴史的に、上記のカスケード指数積分方程式はもともと [[Leabra]] XCAL 学習ルール (一時的に拡張された連続アトラクター学習; [[@OReillyMunakataFrankEtAl12]]) 用に開発されたもので、生物物理学的カスケードからインスピレーションを受けていますが、CaMKII および DAPK1 キナーゼ基質への直接マッピングについてはそれほど明確な理解はありませんでした。
キナーゼ誤差勾配の計算特性
キナーゼエラー勾配 ([[#eq_kinase-delta]]) には、対応するエラー逆伝播勾配との重要な類似点と相違点がいくつかあります。これは、この勾配の [[GeneRec]] 近似と比較すると最もよくわかります。
{id=”eq_generec-delta” title=”GeneRec エラー勾配”} \(\デルタ \およそ y^+ - y^-\)
2 つの [[rate-code activation]] 状態のこの単純な違いは、線形正味入力係数と活性化関数の導関数の対応する差を近似するために使用されます。
{id=”eq_generec-netin” title=”GeneRec 勾配ネット入力”} \(\delta = \left( \sum_i x_i^+ w_i - \sum_i x_i^- w_i \right) y' \about y^+ - y^-\)
これは全体的にキナーゼエラー勾配と似ており、Ca++ 流入は主に [[#eq_ge-raw]] の正味入力のような $g_{e-raw}(t)$ 項によって駆動されますが、樹状突起膜電位 $V_d$ ([[#eq_nmda_g]] と [[#eq_ca-nmda]] の両方) によっても調節され、直接的なVGCC ([[#eq_ca-vgcc]]) からのスパイクベースの寄与。 [[#eq_kinase-delta]] の CaP – CaD の減算は、[[GeneRec]] の導出で説明したように、これらの「活性化ベース」項 ($V_d$ およびスパイク) の導関数を暗黙的に計算します。
ただし、重要な違いは、これらのキナーゼ活性化ベースの値が、単純な GeneRec モデルで使用される従来のシグモイド ロジスティック活性化関数や、[[Leabra]] フレームワークで使用される関連する X-over-X+1 関数よりも全体的にはるかにグレード付けされていることです。したがって、最終結果は、線形 ReLU 活性化関数を使用した誤差逆伝播の動作に近いものになります。この場合、活性化導関数 $y’$ は、どのアクティブ ユニットに対しても 1 に過ぎず、実効誤差勾配は実質的に正味入力で_線形_になります。
キナーゼエラー勾配における活性化因子の寄与がより緩やかで段階的であるため、基礎となる正味入力因子においてもより線形になります。したがって、主な結果は、この誤差勾配が、多くのそのような層を含む深いネットワークの層全体の誤差勾配をより線形に反映するはずであり、それによって、飽和非線形性を持つシグモイド状関数を使用した初期のバックプロップ ネットワークを悩ませていた「勾配消失」問題が回避されることです (詳細については、[[error backpropagation]] を参照)。
それにも関わらず、これらの活性化因子が受信ニューロンの活動の段階的表現を保持しているという事実は、受信活動の厳密に 2 値の寄与のみを持つ ReLU 活性化による誤差逆伝播からの重要な逸脱を表しています。受信ユニットの正味入力が 0 未満の場合、現在の試行についてまったく学習しません。また、多少直感に反しますが、0 より大きい場合、学習の大きさに対する受信ユニットのアクティビティの寄与は実際にはありません ($y’$ のすべての $y’$ は 1 です)。飽和非線形性が使用された場合、これは当てはまりません。この動作は、[[synaptic plasticity]] の基本メカニズムと矛盾します。次の層に上がる重みの大きさが誤差勾配の符号と大きさに影響を与えることは依然として真実ですが、これらはフィードフォワード逆伝播ネットワークの隠れユニットのアクティビティには寄与しないことに注意してください。
{id=”figure_ca++-integration” style=”高さ:25em”}
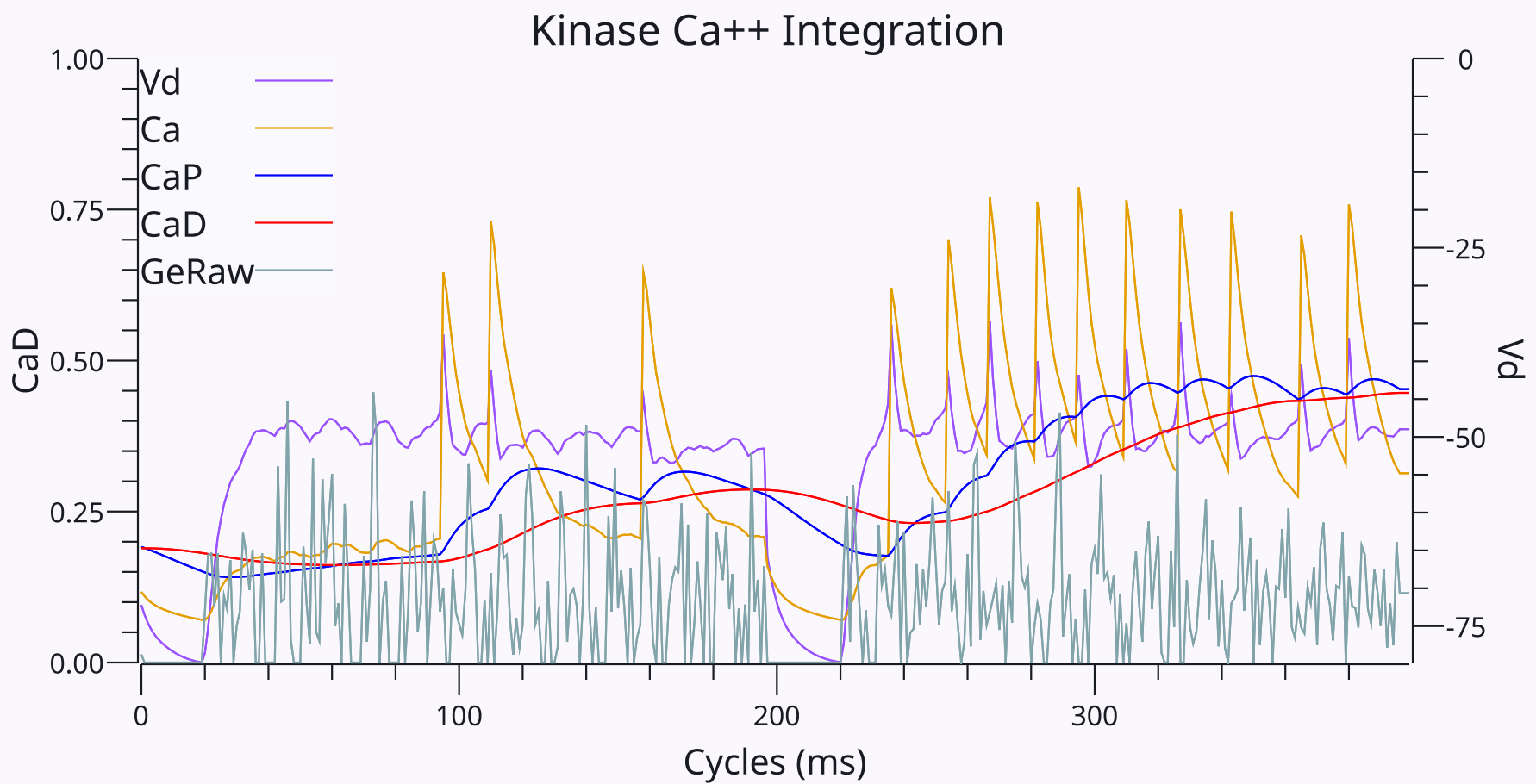
これらの統合された Ca++ シグナルの段階的な性質は [[#figure_ca++-integration]] に示されており、それぞれ 200 ミリ秒の 2 つの異なる試行にわたって関連する変数がプロットされています。
シナプス活動クレジットの割り当て
キナーゼ アルゴリズムの 2 番目のコンポーネントはクレジット割り当て係数です。これは、NMDA 受容体が非常に敏感な、時間の経過に伴う同時発生するシナプスの前後の活動の程度を捕捉します。現実世界の計算コストの制約がない場合、[[#eq_ca-nmda]] で計算される NMDA Ca++ の集合値は、代わりにローカル値を使用して個々のシナプスで計算され、この感度はローカル シナプス Ca++ 信号に直接現れます。
代わりに、[[#eq_kinase-dw]] に示すように、次の個別の Syn シナプス固有の係数を使用して、集合誤差勾配項を乗算します。この活動係数は、ニューロンごとに計算されるスパイクによって引き起こされる減衰活動トレースから始まります。これは、シナプス レベルでのスパイク後の時間の経過に伴う細胞内 Ca++ の正味の減衰/バッファリングを反映しており、シミュレーターでは CaSyn というラベルが付けられます。
{id=”eq_casyn” title=”Synaptic Ca++ スパイク トレース”} \(\rm{CaSyn}(t) = \frac{1}{\tau_{syn}} (\rm{スパイク}(t) - \rm{CaSyn}(t-1))\)
各シナプスでは、これらのトレースの送信 * 受信ニューロン積が、この積によって駆動される同じ指数積分係数のカスケード ([[#eq_cam]] – [[#eq_cad]]) を使用して累積されます。
{id=”eq_sr” title=”シナプス製品”} \(\rm{SR}(t) = \rm{CaSyn}_s(t) * \rm{CaSyn}_r(t)\)
キナーゼ カスケードからのこの SR 値の最長時間積分は、[[#eq_kinase-dw]] の Syn クレジット割り当て値として使用されます (理論的には、CaP には CaP タイムスケール積分が乗算され、CaD には CaD タイムスケールが乗算されますが、値は 1 つだけあり、関連する値の全範囲を定義するため、より長いタイムスケールを使用します。また、各樹状因子と対応する Syn 時間も乗算します)。積分は大規模なネットワークではうまく機能しませんでした)。
上記の単位割り当てメカニズムの広範な実証テストにより、調査された他のさまざまな可能性と比較して、さまざまな困難なタスクにわたって実際にはるかにうまく機能することが示されました。特に、約 30 ミリ秒のタイムスケールでの発火前後の一致に対するこのメカニズムのきめ細かい感度は、$\delta$ 係数で表される誤差勾配を低減するために、さまざまなシナプスをどの程度変更する必要があるかを決定するための重要なクレジット割り当て係数を提供すると思われます。
計算レベルでは、このクレジット割り当て係数が送信条件と受信条件の両方の積であり、それらの時間的一致の影響を受けやすいという事実は、エラー バックプロパゲーションでのみ送信アクティビティを使用することから大きく逸脱していることを示しています。この違いにより、キナーゼ アルゴリズムは相関する神経活動に対してより敏感になり、[[Leabra]] モデルで使用される正則化子としての [[Hebbian learning]] と同様の役割を果たす可能性があります。
ニューロンレベルの線形近似バージョン
[[#eq_trace-syn]] のシナプス固有の SR(t) 値とその指数積分は、非常に単純ではありますが、シナプスの数がニューロンの数よりもはるかに多いため、計算コストが依然として非常に高くなります。したがって、実際には、ニューロン レベルでビン化された CaSyn 値のベクトルに基づく線形回帰係数のセットを使用してこれらの値を計算します。各ビンは 10 ミリ秒の期間にわたる平均 CaSyn 値を保持します。これにより、必要な発火前後の相関を計算するのに十分な分解能が得られます。
| 通常、200 ミリ秒の [[theta rhythm | theta cycle]] の終わりに 1 回発生する学習の時点で、各ビンの値が各シナプスの送信側 * 受信側に対して乗算され、これらのビンの積に対する線形回帰係数が適用されて、上記の式に従って計算される有効な CaP および CaD 時間積分値が直接計算されます。これらの係数は、プレおよびポスト ニューロンの 0 ~ 120 Hz まで 10 Hz 増分でサンプリングされたマイナスおよびプラス位相発火レートの完全な組み合わせ (外積) スイープの条件ごとに 100 個のランダムなポアソン スパイク列に基づくリッジ回帰と投げ縄回帰の組み合わせを使用してトレーニングされました (12 * 12 * 12 * 12 = 20,736 の周波数の組み合わせ * 100 試行 =総試行数 2,073,600 回)。結果として得られる係数の $r^2$ 値は、CaP と CaD に対してそれぞれ 0.991 と 0.996 です (つまり、それらはデータの分散のその割合を説明します)。したがって、この方法は、シナプス レベルでこれらの値を計算する、高精度で大幅にパフォーマンスの高い方法を提供します。詳細については、キナーゼ/リニア を参照してください。 |
シナプスは学習時期をどのようにして知るのでしょうか?
たとえば、結果フェーズに続いて予測フェーズが続くという逆のシーケンスとは対照的に、活動のプラスフェーズの後に学習が起こるのは、どのような種類の生物学的信号によって引き起こされるのでしょうか?効果的な学習を促進するのに十分な信頼性を持って適切な調整が行われるように、これらの段階をマークする何らかの特徴的な神経シグネチャはあるのでしょうか?
グローバル [[neuromodulator]] 信号が重要な「今すぐ学習」信号を提供する可能性は常にあり、実際、[[norepinipherine]] は適切な特性を備えており、新皮質に広く投射されます。しかし、皮質領域ごとに活動のタイミングが異なることや、感覚予測誤差が比較的局所的であることなどを考慮すると、局所的なニューロンレベルの信号が学習のタイミングをガイドする方がより堅牢になるでしょう。
[[temporal derivative#Timing of learning]] で説明したように、マイナス相とプラス相の開始に関連する相対アクティビティのピークが 2 つあり、マイナス相のピークで学習プロセスを開始し、プラス相のピークで学習プロセスを終了できます。ニューロンに影響を与える総興奮性コンダクタンスと抑制性コンダクタンスを時間の経過とともに統合すると、この活動の高速統合と低速統合の違いという点でこれらのピークが堅牢かつ比較的スムーズに示されるため、それを学習タイミングの推進に使用します。
通常、最初のマイナス位相ピークはより大きく、より堅牢であるため、学習プロセスの開始をトリガーすることによって支配されます。マイナス相のピークの開始からパラメーターに依存するサイクル数 (ミリ秒) が経過した後、プラス相のピークが検出され、その後指定されたサイクル数が経過すると、シナプス後学習信号が LearnDiff 変数に記録され、学習が促進されます。
ピーク検出ロジックは、前のピークを超えるたびに時間とピーク値を記録することで確実に機能します。この徐々に増加するダイナミックは、経験的なピーク値に達するまで続きます。最後のピークからの時間が最小マイナス サイクルしきい値を超えると、ピーク ベースラインがリセットされ、ピーク検出は同じロジックを使用してプラス位相ピークの検出に切り替わります。そのピーク以降のサイクルがプラス位相サイクル パラメーターを超えると、学習が発生します。
このようなメカニズムはニューロンでは具体的に実証されていませんが、これらは時間の経過に伴う化学的統合を伴う非常に「生物学的に優しい」メカニズムであり、たとえば生物物理学的に詳細な [[@^UrakuboHondaFroemkeEtAl08]] モデルの基礎となっています。さらに、さまざまな単純な単一ピークおよび/またはタイミング駆動のダイナミクスが同等の結果を生み出す可能性があります。ダブルピーク ダイナミクスのさまざまなバージョンや以前のアイデアを実験した場合、プラスの段階から大きく外れていない限り、学習は一般に堅牢でした。
安定化と再スケーリングのメカニズム
生物学的に動機づけられた一連のメカニズムは、上記のエラー駆動型学習メカニズムから生じる、そうでなければ多少「ぐにゃぐにゃ」な学習に対して、より強力な「バックボーン」または「背骨」を提供するために使用され、より長い時間スケールにわたって学習を安定させ、これらの双方向に接続されたネットワークを悩ませる寄生的な正のフィードバック ループを防ぐのに役立ちます。これらの正のフィードバック ループが出現するのは、ネットワークが双方向の一般に対称的な接続性により安定したアトラクター状態に落ち着く傾向があり、そのようないくつかの状態がますます広くなり、より多くの「表現空間」を捕捉する傾向があるためです。
活性化に基づくクレジット割り当てプロセスは、最もアクティブなニューロンが最大の重み変化を経験するこの「金持ちがさらに金持ちになる」ダイナミクスに貢献します。私たちはこれを口語的に「ユニット占有」問題と呼んでいます。少数のユニットが表現空間を独占し始める問題であり、適切に管理されない場合、効果的な学習に対する大きな実際的な障壁となります。比喩的に言えば、これは政治や経済の世界での汚職や極度の富の不平等に似ています。システム全体の効率が低下し、あまりに深刻になると重大な破綻につながる可能性があります。
この問題は、アトラクター ダイナミクスを示さない、より広範なニューラル ネットワーク分野で使用される純粋なフィードフォワード ネットワークの大部分では発生しないことに注意してください。ただし、この種の現象は、オンポリシー強化学習、敵対的生成ネットワーク、またはバックプロップスルータイム (BPTT; [[@LillicrapSantoro19]]; [[@LinsleyAshokGovindarajanEtAl20]]) などの他の形式の再帰逆伝播ネットワークなど、そのような正のフィードバック ループの可能性がある他のフレームワークでは問題になります。
上記の比喩を続けると、これらのモデルの競争条件を平等にするためには、さまざまな形で課税と富の再分配を均等化する必要があります。 Axon の一連の安定化抗ホッグ機構には以下が含まれます。
-
SWt: 構造的でゆっくりと適応するウェイト。上記の方程式によって駆動される通常の学習重みに加えて、樹状突起スパインの生物物理学的特性を表す、ゆっくりと適応する乗法的な重み値を導入します。SWt は「文字通り」モデルにスパインを与えます。
As reviewed in [[synaptic plasticity]] spines are structural complexes where all the synaptic machinery is organized, and they slowly grow and shrink via genetically controlled, activity-dependent protein remodeling processes, primarily involving the actin fibers also found in muscles. A significant amount of spine remodeling takes place during sleep, so the SWt updating represents a simple model of sleep effects.
The SWt is multiplicative in the sense that larger vs. smaller spines provide more or less room for the AMPA receptors that constitute the adaptive weight value. The net effect is that the more rapid trial-by-trial weight changes are constrained by this more slowly adapting multiplicative factor, preventing more extreme changes. Furthermore, the SWt values are constrained by a zero-sum dynamic relative to the set of receiving connections into a given neuron, preventing the neuron from increasing all of its weights higher and hogging the space. The SWt is also initialized with all of the randomness associated with the initial weights, and preserving this source of random variation, preventing weights from becoming too self-similar.
-
恒常性活性レベル: シナプスは全体的な活性の目標レベルを維持するために恒常的に再スケールされ、個々のニューロンによって異なります [[@TorradoPachecoBottorffGaoEtAl21].このプロセスは、再スケーリング プロセスにも関与する SWt (同様にスリープに関連する) の更新と同じ遅いタイムスケールでシミュレーションします。学習信号の「DC」成分を吸収する適応バイアス重み ([[@Schraudolph98]]]] と同様に、目標アクティビティ レベルは時間の経過とともにゆっくりと適応することもできます ([[@Schraudolph98]]]]。ただし、この適応には通常、ゼロサム制約が適用されるため、1 つのニューロンのアクティビティの増加は他の場所の減少によって補償する必要があります。)
This is similar to a major function performed by the BCM learning algorithm in the [[Leabra]] framework – by moving this mechanism into a longer time-scale outer-loop mechanism (consistent with Turigiano’s data), it works significantly more effectively. By contrast, the BCM learning ended up interfering with the error-driven learning signal, and required relatively quick time-constants to adapt responsively as a neuron’s activity started to change.
-
ソフト境界とコントラスト強調: ほとんどの [[abstract neural network]] モデルの重みとは異なり、特定のシナプス接続の強度は強く制限されます。 標準的な指数関数的なアプローチの「ソフト境界」ダイナミックを使用します (増加には $1-w$ が乗算され、減少には $w$ が乗算されます)。さらに、[[Leabra]] モデルで開発されたように、有効な重みが重み値の全範囲に及ぶように、このソフト境界の圧縮効果に対抗するコントラスト強化メカニズムを追加すると便利です。
-
ゼロサムの重み変更: 場合によっては、より高速なエラー駆動の重み変更をゼロサムに制限することも便利です。これはオプションのパラメーターでサポートされています。このゼロサム ロジックは [[@^Schraudolph98]] によってうまく表現されており、広く使用されている ResNet モデルに実装されています。
-
シグモイド活性化導関数とノイズ抑制: 重要な一般的な学習原理は、現在の学習コンテキスト (刺激、エラーの性質など) に対して特に「敏感」である可能性が最も高いニューロンのより小さなサブセットに学習変更を集中させることです。これにより、変更が最大の影響を与えると同時に、既に他のコンテキストにコミットされているニューロンへの変更を最小限に抑えて干渉効果を低減します。興味深いことに、これは誤差逆伝播におけるシグモイド活性化関数の導関数 (標準ロジスティック関数の場合は $y’ = y (1-y)$) を乗算した効果です。これにより、活性化が約 0.5 である最も敏感なニューロンに学習が集中しますが、すでにオンまたはオフに強くコミットされているニューロンの学習は少なくなります。
On the other hand, this sigmoidal derivative also contributes to the vanishing gradient problem, which is especially problematic if there aren’t other mechanisms that keep neurons in their sensitive range. In Axon, the closely balanced [[inhibition]] does a good job of keeping neurons in their sensitive range. Furthermore, as shown in [[#figure_ca++-integration]], there is a considerable amount of noise in the integrated Ca++-driven values that drive learning, due to the discrete spiking. For these reasons, it ends up being beneficial to multiply by the derivative of a sigmoid function, even though the kinase error gradient ([[#eq_kinase-delta]]) implicitly computes the derivative of the effective activation, as shown in the [[GeneRec]] derivation. Further, applying a multiplier that selectively suppresses small error gradients is also beneficial. Both of these are accomplished by an additional receiving-neuron-based learning rate modulator (
RLRate) that multiplies the synaptic weight changes.
### 実装
各シナプスには 3 つの重み値があり、重み値が更新されるまで $\Delta w$ を累積する DWt があります。
SWt= 低速の構造重量。SlowIntervalトライアルごとにのみ更新されます (デフォルトは 100)。LWt= 学習済みの線形重み。学習によって更新されるシナプスの内部生化学的状態を反映します。これは、DWt$\Delta w$ 値が直接追加されるもので、0..1 の正規化された範囲内のソフト重み境界の影響を受けます。Wt= シナプスのグルタミン酸放出の影響を決定する有効重量、つまり PSD 内の AMPA 受容体の数と有効性。これは、ソフト ウェイト境界のコンテキストでコントラスト強調を実装するためのLWtのシグモイド関数として計算され、SWt値を乗算します。
{id=”eq_wt” title=”LWt、SWt からの重量”} \(\rm{Wt} = \rm{SWt} \frac{2}{1 + \left( \frac{1-\rm{LWt}}{\rm{LWt}} \right)^6}\)
{id=”plot_sigmoid” title=”S 字状コントラスト強調関数” Collapsed=”true”} 「ゴール」 ## ポイント:= 100 lin := zeros(points) // 線形値 sig := zeros(points) // シグモイド値 ##
for v := 範囲 100 { ## l := max(配列(v) / ポイント、1.0e-6) s := 2.0 / (1.0 + ((1 - l) / l)**6) lin[v] = l sig[v] = s ## }
プロットスタイル := func(s *plot.Style) { s.Range.SetMax(2).SetMin(0) s.Plot.XAxis.Label = “線形” s.Plot.XAxis.Range.SetMax(1).SetMin(0) s.Plot.Legend.Position.Left = true } プロット.SetStyler(sig, プロットスタイラー)
fig1, pw := lab.NewPlotWidget(b) sl := プロット.NewLine(fig1, プロット.データ{プロット.X: lin, プロット.Y: sig}) 「」
シグモイド関数 ([[#plot_sigmoid]]) は 1 を中心に 0..2 から変化するため、LWt == 0.5 の場合、Wt 値は SWt に等しく、学習された重み値が 0.5 を超えると、実効重みがその「ベースライン」SWt 値を超えて増加します。 LWt の値が 0.5 未満の場合は、SWt よりも低くなります。
学習による LWt のソフト境界増分は、LWt が 1 に近づくと重み値の増加を減らし、0 に近づくと重み値の減少を減らします。
{id=”eq_sb” title=”ソフト バウンディング”} \(\rm{if} \; \rm{DWt} > 0: \rm{LWt} \mathrel{+}= \rm{DWt}(1 - \rm{LWt})\)
\[\rm{else}: \rm{LWt} \mathrel{+}= \rm{DWt} (\rm{LWt})\]ゼロサムの重みの変更
SubMean パラメーターは、ゼロサム重み変更 (LWt と SWt の両方) の段階的バージョンを実装するために使用されます。これにより、重み変更を適用する前に平均重み変更値をどれだけ差し引くかを決定します。重要なことに、$x |
_{!0}$ 表記で示されるように、実際に重みの変化がゼロ以外のシナプスのみが、平均値自体の計算を含め、このゼロサム計算に参加します。 |
{id=”eq_submean” title=”ゼロサム”} \(\rm{DWt} \mathrel{-}= \rm{平均値} \frac{1}{n} \sum \rm{DWt}|_{!0}\)
SWt の更新
初期のランダムな重み値は、一様乱数を使用して設定されます。通常、平均は 0.5、分散は 0.25 です。 SWtPct 係数 (デフォルトは 0.5) は、SWt 成分と LWt 成分に分散のどの割合が含まれるかを決定します。 SWt 乗算係数が正味有効重み値に大きな影響を与えるため、ゆっくりと適応する値により多くの分散を入れることにより、学習全体にわたってこの分散はよりよく保存されますが、その代わりに学習全体が多少遅くなります。
学習による影響を維持するために、SWt 値の範囲にも制限が課され、デフォルトでは 0.2 ~ 0.8 の範囲になります。
SWt は、前回の更新以降に累積された DWt 値を使用して更新されます。学習速度は大幅に遅くなり、標準の学習速度に加えて動作します。より小さく、より高速な学習モデルの場合、この追加の学習率係数はデフォルトで 0.1 ですが、より大きな安定化が必要なより大規模で深いモデルの場合は、0.0002 程度の低い値が最適に機能します。
恒常性維持メカニズム
抑制性プール内の各ニューロンは、層全体の平均活動の割合として、範囲 (デフォルトでは 0.5 ~ 2) から均一にサンプリングされた目標平均活動レベル TrgAvg で初期化されます。したがって、TrgAvg 値が 1 のニューロンは、そのプール全体の平均アクティビティと等しい有効ターゲット アクティビティ レベルを持ちます。
TrgAvg 値の主な機能は、この目標値と最近の間隔におけるニューロンの実際の平均アクティビティとの差の関数として学習シナプス重みの再スケーリングを駆動することです。
{id=”eq_dtrgavg” title=”目標平均学習量”} \(\rm{LWt} \mathrel{+}= \epsilon (\rm{TrgAvg} - \rm{AvgPct})\)
ここで、$\epsilon$ は学習率係数 (SynScaleRate) で、デフォルトは 0.005 ですが、大規模で学習が遅いモデルではこれより低くなります (0.0002)。
学習の過程で、このターゲット値は、ゼロ和制約に従って、ニューロンごとの誤差勾配値によって更新されます。
{id=”eq_dtrgavg” title=”目標平均学習量”} \(\rm{DTrgAvg} \mathrel{+}= \epsilon \delta\)
\[\rm{TrgAvg} \mathrel{+}= \rm{DTrgAvg} - \frac{1}{n} \sum \rm{DTrgAvg}\]ここで、$\epsilon$ は学習率係数 (ErrLRate、デフォルトは 0.02)、$\delta$ はニューロンごとの誤差勾配で、CaP と CaD の差 ([[#Kinase cascade]]) から計算されます。 2 番目の式に示すように、ターゲット値が遅い間隔で更新される場合、これはゼロ和制約の対象となります。
RLレート
受信ニューロンのアクティビティに基づく学習速度変調係数は、シグモイド導関数項と、ノイズを反映することが多い小さな差を抑制する係数を組み合わせたものです。
{id=”eq_rlrate” title=”受信者学習率係数 (RLRate)”} \(\rm{RLRate} = 4 \rm{CaD}^* (1-\rm{CaD}^*) + \frac{|\rm{CaP} - \rm{CaD}|}{\max (\rm{CaP}, \rm{CaD})}\)
ここで、$\rm{CaD}^*$ は、最大レイヤーに対する CaD の正規化されたバージョンです。ノイズ係数には、大きさが 0.02 未満の差が固定の 0.001 の重み係数に寄与するようなしきい値も適用されます。
適格性トレース
[[synaptic plasticity]] でレビューされているように、さまざまな条件下での学習における一時的な適格性の痕跡についてはかなりの証拠があります。計算の観点から、[[@^BellecScherrSubramoneyEtAl20]] は、ニューロン自体に関して計算された local 偏導関数のチェーンを含む、計算的に強力なバックプロップスルータイム (BPTT) アルゴリズム ([[@Werbos90]]) を近似する生物学的に妥当な方法を提供するトレース方程式を導き出しました。
{id=”eq_etrace-bptt” title=”自己デリバティブ”} \(e(t) = \frac{\部分 y(t)}{\部分 y(t-1)} \frac{\部分 y(t-1)}{\部分 y(t-2)} ...\)
これは、累積された $e^{t-1}$ 係数と新しい偏導関数を乗算することによって再帰的に計算できます。キナーゼ フレームワークでは、現時点での偏導関数は、誤差勾配定義 ([[#eq_kinase-dw]]) に基づく差分近似を使用して計算できます。
{id=”eq_etrace-cad” title=”キナーゼ トレース”} \(e(t) = (\rm{CaD}(t) - \rm{CaD}(t-1)) e(t-1)\)
また、過去のいくつかのタイム ステップで任意の時間的カットオフを使用することを避けるために、積分時定数を使用して指数積分を使用して、連続更新方程式を提供できます。
{id=”eq_etrace-cad-tau” title=”指数関数的キナーゼ トレース”} \(e(t) = e(t-1) + \frac{1}{\tau_e} \left( (\rm{CaD}(t) - \rm{CaD}(t-1)) - e(t-1) \right)\)
このトレース係数を使用して、既存の学習ルール ([[#eq_kinase-dw]]) を重み係数 $\lambda$ で調整し、その効果の全体的な大きさを決定できます。
{id=”eq_kinase-dw-et” title=”キナーゼ学習ルール”} \(\Delta w \propto (\rm{CaP} - \rm{CaD}) \rm{Syn} (1 + \lambda e(t))\)
この式を使用すると、通常、$\tau_e$ 係数が約 2 ~ 4、$\lambda$ が約 0.5 である時間構造を持つタスクに大きな利点が得られます。