compcogneuro/web: linear-algebra
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/linear-algebra.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Computation”] bibfile = “ccnlab.json” +++ 線形代数 の言語は、ニューラル ネットワークの動作と学習を理解するための重要な一連の概念を提供するだけでなく、線形回帰や [[principal components analysis]] などの重要な分析手法も提供します。同様に便利なフレームワークについては、[[information theory]] も参照してください。
たとえば、ネットワーク層の活動状態は、層内の各 n 個のニューロンの活動を表す n 次元の数値ベクトルとして考えることができます。このベクトルは太字の小文字を使用して記述できます。x は入力層、y (次元 m) はその上の隠れ層です。したがって、2 つの層を相互接続する重みのセット W は、n x m matrix になります (紛らわしいことに、n = 列数、m = 行数ですが、インデックスは逆の順序で書き込まれます)。
{id=”figure_matrix-mult”}
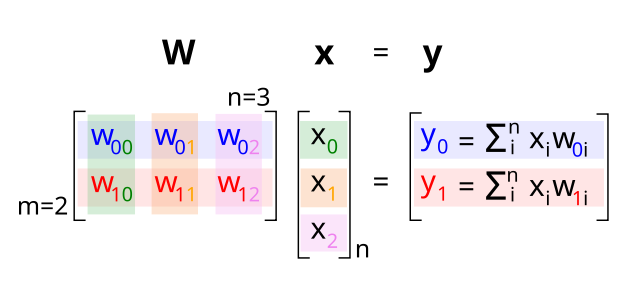
[[#figure_matrix-mult]] は、次の方程式のように、入力ベクトル x と重み行列 W の行列乗算によって隠れ層ニューロンの線形活性化がどのように得られるかを示しています。
{id=”eq_act_wt” title=”行列乗算”} \({\bf y} = {\bf W} {\bf x}\)
重み行列 W の各行には、隠れ層の各受信ニューロンの重みのベクトルが含まれており、行列の乗算の演算は、これら 2 つのベクトルの個々の dot product (要素ごとの積の合計) の乗算の単なる累積です。
{id=”eq_act_wt_dot” title=”内積”} \(y_j = \sum_i^n x_i W_{ji}\)
このドット積は、[[neuron]] の章の [[neuron#Computing input conductances]] セクションでよく知られているはずで、生物学的には、送信ニューロンのスパイク (したがってグルタミン酸神経伝達物質の放出) の速度に応じて開く AMPA 興奮性チャネルによって引き起こされる総コンダクタンスに対応し、重み値は各シナプスにおけるこれらの AMPA 受容体の数と有効性に対応します。
内積は射影です
{id=”figure_face-dim-prjn”}
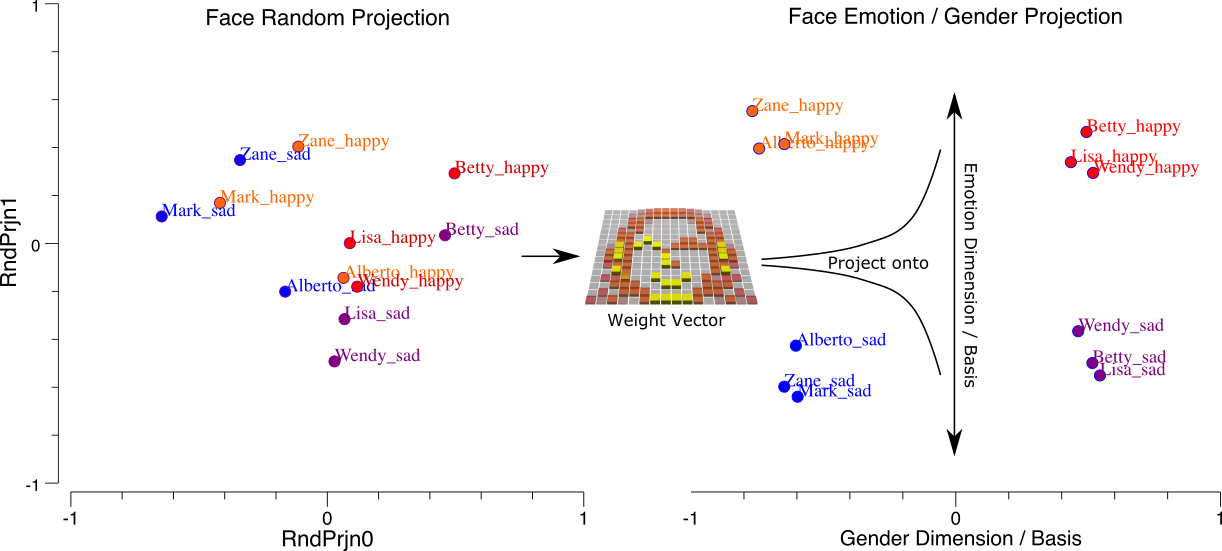
ドット積演算 (内積 または スカラー積 とも呼ばれる) は 2 つのベクトルを受け取り、それらを 2 つのベクトルが互いに「整列」する程度を表す単一のスカラー数値に変換します。これは、線形代数用語では 射影 計算として知られています。事実上、一方のベクトルを「レンズを通して」もう一方のベクトルを見ていることになります。したがって、[[detector simulation]] で説明されているように、受信ニューロンは、その入力層のシナプス重みの入力ベクトルを「レンズを通して」認識します。重みにゼロ値がある場合、入力値は「フィルターで除外」され無関係になりますが、強力な重みにより、それらの入力は受信者のアクティビティを駆動する上で非常に重要になります。
[[#figure_face-dim-prjn]] は、[[categorization]] で説明したように、[[faces simulation]] のコンテキストでこの射影操作を示しています。この投影操作は、行動の重要性の次元に沿って入力を整理および体系化します。たとえば、図に示すケースでは、感情と性別の次元に沿って顔入力を投影します。これについては、[[faces simulation]] で調べることができます。
基底空間
この演算のもう 1 つの線形代数の枠組みは、基底ベクトル で構成されるシナプス重み行列の観点から構成されます。ここで、行列の各行は、入力アクティビティ ベクトルによって定義される 空間の新しい、_回転された_バージョンの異なる_基底_または_軸_を定義します。したがって、隠れ層ニューロンは、入力空間をこの新しい回転空間に「変換」し、特定のものを増幅し、他のものをフィルターで除去します。
さらに、この基底空間は、元の空間の高次元と比較して、より少ない基底ベクトルを使用して分散の重要な次元のほとんどを捕捉することにより、[[curse of dimensionality]] に役立ちます。たとえば、大部分が冗長な元の寸法 (さまざまな感情を表現する際に使用される目や口の形状など) を 1 つの基底ベクトルに結合することができます。
固有ベクトルと特異値分解
[[principal components analysis]] (PCA) のプロセスは、固有ベクトル 分解の線形代数プロセスに基づいて、入力空間を投影する新しい基底ベクトルのセットを選択する方法を提供します。ここで、固有ベクトルは、固有ベクトルである行列を乗算したときに同じ方向を向き続ける特別なベクトルです。
{id=”eq_eigen” title=”固有ベクトルと固有値”} \({\bf A}{\bf v} = \lambda {\bf v}\)
ここで、A は行列であり、v はその行列の固有ベクトルです。これは、その乗算により同じベクトルが再度生成され、その固有ベクトル v に関連付けられた 固有値であるスカラー値 $\lambda$ によってスケーリングされるためです。
最大の固有値を持つ固有ベクトルは、行列 A に関する最も多くの「情報」を提供します。そのため、PCA の一般的な使用法は、次元削減 により、最も強い 2 つの固有ベクトルに関してより高次元の空間を表現し、これを 2D プロットにプロットすることです。そうしないと、大きな n 次元空間を視覚化するのが困難になる可能性があります。
興味深いことに、[[Hebbian learning]] が PCA を実行していることを数学的に示すことができ、入力アクティビティ空間を表現する新しい効率的な方法を学習するという、[[Hebbian learning]] が実行していることについて強力な概念的理解を提供します。
最小二乗回帰
線形代数の最も基本的な問題の 1 つは、最小二乗問題を解くことです。
{id=”eq_lsq” title=”最小二乗法”} \(\rm{最小化} \; \|{\bf W} {\bf x} - {\bf t}\|^2\)
これは、x のすべての関連する入力アクティベーション状態にわたって、target アクティベーション値 t とネットワークが ([[#eq_act_wt]] を使用して) 計算する y アクティベーション値との差を最小化する行列 W の値を見つけることを意味します。これは、線形回帰 が解決する問題であり、[[error-driven learning]] の基本目標を表現する別の方法であり、[[error backpropagation]] は、この形式の 2 層線形ネットワークでこれと同じ問題に対する反復解を提供します。
したがって、ニューラル ネットワーク学習の 2 つの主要な形式、ヘビアン学習とエラー駆動型は、線形代数のツールを使用して、単純かつ本質的な形式で理解できます。
非負の因数分解
正の値の数値のみを使用して基底空間をエンコードする必要があることによって生じる重要な制約があります (つまり、非負の因数分解; [[@LeeSeung99]])。ニューロンは一般に、特定の送信ニューロンからの正のみの重みを持つことができ、スパイク率に関して正の値の信号のみを送信するため、この非負の空間は、そのような制約のない [[abstract neural network]] モデルと比較したこれらの制約の影響を理解するために重要です。
直感的には、[[#figure_matrix-mult]] に示されている重みの観点から考えると、各重み値が負でない必要があり、重みベクトルが互いに直交している必要がある場合 (つまり、独立した因子をエンコードするため)、特定の列に重み値が重なり合うことはできません。 3D 空間の完全な基底表現、つまり 3 つのそのような重みベクトル (図では 2 つだけを示しています) の場合、これは、各重みが一意の 1 つの列に 1 を持ち、他の 2 つの列のそれぞれに 0 がなければならないことを意味します。
したがって、非負性制約は、それ自体 (PCA が課すすべて) の直交性制約よりも_はるかに_強く、基底ベクトルを元の入力次元の単純な_localist_エンコーディングになるように効果的に一意に決定します(_x_入力ベクトルの各行は異なる入力次元です)。対照的に、元の入力次元のさまざまな回転として、負の要素を持つ無限に多くの直交基底ベクトルを構築できます。重要なことに、回転には正と負の両方の数値が必要です。1 つの次元に加算されるものはすべて他の次元から取得する必要があり、回転のゼロ和の性質は両方の符号の要件を意味します。
基底ベクトルよりも入力次元の空間がはるかに大きい場合、非負制約は依然として、比較的少数の入力次元に重要な重み付けを持つ、より疎な表現を課す傾向があります。これは、入力次元が互いに重なり合うことができず、直交を保つためです。ローカリストの場合と同様に、非負性制約により、基底ベクトルが元の入力次元と直接_整列_するように強制されます。これらの入力次元は、非負性制約の下では_特権_基底を表しますが、その制約がなければ特権を与えられません。
非負因数分解と符号制約なし因数分解 (PCA など) の関係、標準的な「古典的」確率と量子確率の違い、および脳の働きの側面を理解するための量子レベルの現象の広範な意味については、[[quantum-analogies]] を参照してください。