compcogneuro/web: neuron-bayesian
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/neuron-bayesian.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Activation”, “Computation”] bibfile = “ccnlab.json” +++ このページでは、ニューロンの生物学に基づいて導出された [[neuron equilibrium potential]] 方程式が、ベイズ仮説検定 ([[@HintonSejnowski83]]; [[@McClelland98]]) の観点からもどのように理解できるかを示します。このフレームワークでは、関連データに直面してさまざまな仮説を比較します。これは、検出器が探している信号が存在するかどうか ($h$)、存在しないか ($\overline{h}$) をテストする方法に似ています。 現在の入力データ $d$ ($P(h|d)$ と記述されます) が与えられた場合の $h$ の確率は、仮説とデータ (ここでは $f(h,d)$ および $f(\overline{h},d)$ と記述されています) の間の関係の他の 2 つの関数の単純な比率関数です。
{id=”eq_phd”} \(P(h|d) = \frac{f(h,d)}{f(h,d) + f(\overline{h},d)}\)
したがって、結果として得られる確率は、検出仮説 $h$ の支持が_帰無仮説_ $\overline{h}$ の支持よりもどの程度強いかの関数にすぎません。 この比率関数は、長年にわたって数理心理学モデルで使用されてきた Luce 選択比率として、一部の心理学者にはよく知られているかもしれません。
{id=”figure_detector-probs”}
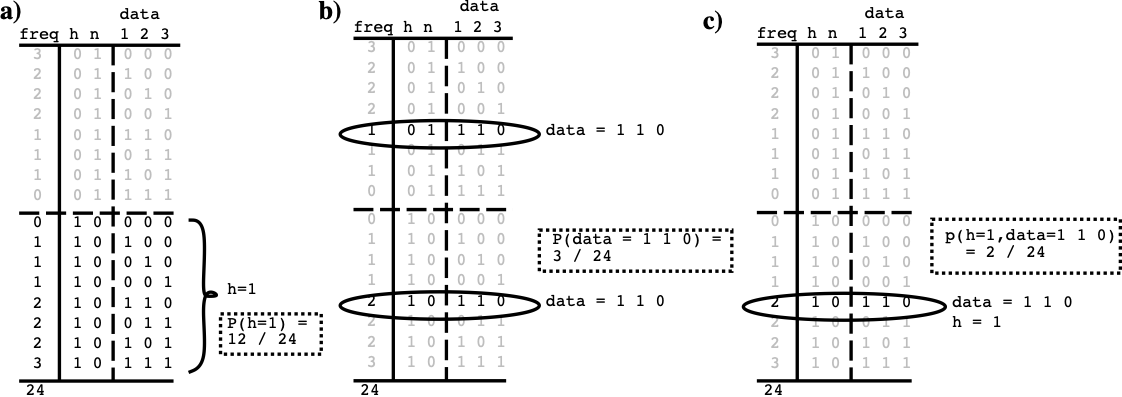
具体的な例を使用して、3 つのソースから入力を受け取る検出器を考えてみましょう。たとえば、垂直線が存在する場合 (これが検出しようとしているものです)、3 つのソースすべてがアクティブ化される可能性があります ([[#figure_detector-probs]])。したがって、仮説 $h$ は世界に垂直線が実際に存在するということであり、$\overline{h}$ は垂直線は存在しないということです。 $h$ と $\overline{h}$ は「相互に排他的」な選択肢です。それらの合計確率は常に 1 です。世界状態テーブルから直接計算できる、関心のある基本的な確率が 3 つあります。特定の状況が真であるケースの数を合計し、ケースの総数で割るだけです (明示的で完全なデータを使用すると、確率の計算は単なる計算になります)。
-
仮説 $h$ が真である確率、または $P(h=1)$、あるいは略して単に $P(h)$ = 12/24 または 0.5。
-
現在の入力データ (例: $d=1 1 0$、略称 $P(d=1 1 0)$ または $P(d)$) の確率 = 3/24 (.125) です。これは、仮説が偽の場合に 1 回、真の場合に 2 回発生するためです。
-
最初の 2 つの交差は、仮説とデータの 結合確率 として知られ、$P(h=1, d=1 1 0)$ または $P(h,d)$ と書かれ、2/24 (.083) となります。
| 同時確率は、他のすべての可能な状態と比較して、2 つの異なる状態がどのくらいの頻度で同時に発生するかを示しますが、実際に知りたいのは、先ほど取得した特定の入力データを受け取ったときに、仮説が真となる頻度を知りたいだけです。 これは、データを考慮した仮説の 条件付き確率 であり、$P(h | d)$ と記述され、次のように定義されます。 |
{id=”eq_cond_p”} \(P(h | d) = \frac{P(h, d)}{P(d)}\)
したがって、$d=1 1 0$ を取得した例では、次のことが知りたいとなります。
{id=”eq_cond_p_d”} \(P(h=1 | d=1 1 0) = \frac{P(h=1, d=1 1 0)}{P(d=1 1 0)}\)
表によれば、これは (2/24) / (3/24)、つまり .67 です。 したがって、直感と一致すると、3 つの入力のうち 2 つがアクティブであるということは、垂直線が存在するという仮説が真実である可能性が高いことを示していることがわかります。 この入力データと仮説の相関関係に関する基本的な情報は分子の同時確率から得られますが、この情報を適切なコンテキスト (特定の入力データが実際に発生したケース) に_スコープする_ ためには、分母が重要です。
上の方程式は検出器に解いてもらいたいもので、[[#figure_detector-probs]] のようなテーブルがある場合、この方程式は簡単に解けることがわかります。 ただし、このようなテーブルを持つことは現実の世界ではほぼ不可能です。この問題は、ベイジアン数学が、尤度と呼ばれるものを使用して、条件付き確率を逆に反転することで解決するのに役立ちます。
{id=”eq_pdh”} \(P(d | h) = \frac{P(h, d)}{P(h)}\)
結局のところ、データ (つまり、入力 (または実験) によって得られたもの) の確率を、よくわからない仮説に基づいて計算することを考えるのは、少し奇妙です。 ただし、代わりに、仮説の仮定に基づいてデータを_予測_する可能性がどの程度あるかと考えてください。 言い換えれば、尤度はデータが仮説にどの程度適合するかを計算します。
数学的には、尤度は、以前に使用した仮説とデータの同じ同時確率に依存しますが、それは異なる方法で_スコープ化_されています。 今回は、仮説が真だったすべてのケースを対象にして、この合計のどの部分に特定の入力データの状態が含まれているかを判断します。
{id=”eq_cond_p_d_1”} \(P(d=1 1 0 | h=1) = \frac{P(h=1, d=1 1 0)}{P(h=1)}\)
これは、(2/24) / (12/24) または .167 です。 したがって、仮説が正しいときにこのデータを受け取ることが期待されます。これは、仮説が正しいということだけを知ってこのデータを取得すると予測する可能性がどのくらいかを示します。
尤度関数の主な利点は、同時確率 $P(h,d)$ を実際に知る必要がなく (つまり、考えられるすべてのイベントとその頻度のテーブルを必要とせず)、仮説の指定方法の関数として尤度関数を直接計算できることが多いことです。 直接計算できる尤度関数があると仮定すると、ベイズの公式は結合確率の必要性を排除する単純な代数にすぎません。
{id=”eq_bayes”} \(P(h, d) = P(d | h) P(h)\)
次のような:
{id=”eq_bayes2”} \(P(h|d) = \frac{P(d|h) P(h)}{P(d)}\)
| これにより、事前 ** の尤度倍という観点から、ベイズ用語で **事後と呼ばれる $P(h | d)$ ($P(h)$ と呼ばれるもの) を記述することができます。 事前分布は、データをまったく見ずに仮説が真実である可能性を示します。いくつかの仮説は、他の仮説よりももっともらしい (より頻繁に真実である) だけであり、これはこの用語に反映されています。 事前確率は、より単純な仮説をより可能性が高いものとして優先するためによく使用されますが、これは必須ではありません。 ここでの応用では、前の項は最終的に定数となり、基礎となる生物学から実際に (少なくとも近似的に) 測定できるようになります。 |
実際にベイズ公式を使用する際の最後の障壁は分母 $P(d)$ です。これには、このデータが他のデータと比較してどの程度の可能性があるかを何らかの方法で知る必要があります。 便利なことに、帰無仮説 $\overline{h}$ を使用する場合、$P(d)$ を尤度と事前項のみを含む式に置き換えることができます。仮説と帰無仮説は相互に排他的であり、合計は 1 になるため、データの確率は、仮説と重複する部分と帰無仮説と重複する部分の合計で表すことができます。
{id=”eq_pd”} \(P(d) = P(h,d) + P(\overline{h},d)\)
[[#figure_detector-probs]] では、これは上半分と下半分の $P(d)$ を別々に計算し、これらの結果を加算して全体の結果を取得することになります。
{id=”eq_pd_hv”} \(P(d) = P(d|h) P(h) + P(d|\overline{h}) P(\overline{h})\)
これをベイズの公式に代入すると、次のようになります。
{id=”eq_pd_hv2”} \(P(h|d) = \frac{P(d|h) P(h)}{P(d|h) P(h) + P(d|\overline{h}) P(\overline{h})}\)
| これは、厳密に 2 つの仮説の尤度と事前確率のみを考慮した式になりました。 さらに、これは最初に示した $f(h,d) = P(d | h) P(h)$ と $f(\overline{h},d) = P(d | \overline{h}) P(\overline{h})$ の式と同じです。これは非常に単純な $\frac{h}{h+\overline{h}}$ 形式を持ち、仮説に有利な尤度と、仮説に反する尤度の「バランス」を反映しています。 ニューロンの生物学的特性が実装されるのはこの形式です。 [[#figure_detector-probs]] のテーブルを使用して、この方程式が結合確率を直接使用して得られたものと同じ結果 (.67) が得られることを確認できます。 |
[[#figure_detector-probs]] のテーブルのようなものを現実の世界で使用できない理由は、入力状態の異なる一意の組み合わせが膨大な数になるため、テーブルがすぐに手に負えないほど大きくなるからです。 たとえば、入力がバイナリの場合 (これは実際にはニューロンには当てはまらないため、さらに悪いことに)、テーブルでは $n$ 入力に対して $2^{n+1}$ エントリが必要になります。これは、すべての可能性を各仮説の下で 1 回ずつ、計 2 回考慮する必要があるという事実を反映する 2 という追加係数 (指数内の $+1$ を考慮) が必要です。 これは、わずか 1,000 個の入力に対しておよそ $1.1 x 10^{301}$ になります (そして、皮質ニューロンに対して 5,000 個の入力という控えめな推測を当てはめると、計算機は結果として $Inf$ を与えます)。
実際のデータの代わりに、尤度項を直接計算するもっともらしい方法を考え出すことに頼らなければなりません。 検出器に対するもっともらしい仮定の 1 つは、尤度は検出器が検出しようとしているものと一致する入力の数に直接 (線形) 比例し、各入力ソースが仮説をどの程度代表しているかを指定する線形係数を持つというものです。 これらのパラメータは、標準の重量パラメータ $w$ にすぎません。 線形比例の仮定と組み合わせると、重み付けされた入力の正規化された線形関数である尤度関数が得られます。
{id=”eq_pdh_sum”} \(P(d|h) = \frac{1}{z} \sum_i d_i w_i\)
ここで、$d_i$ は 1 つの入力ソース $i$ の値 (たとえば、そのソースが何かを検出した場合は $d_i = 1$、それ以外の場合は 0)、正規化項 $\frac{1}{z}$ により、結果が 0 と 1 の間の有効な確率であることが保証されます。
私たちが確率を「測定」しているのではなく「定義」しているという事実により、世界の客観的に測定可能な出来事の頻度と比較すると、これらの確率は「主観的」になります。 それにもかかわらず、ベイジアン数学では、少なくとも数学的に正しい方法で関連情報を統合していることが保証されます。
続行するには、次の尤度関数を定義できます。
{id=”eq_pdh_sum12”} \(P(d|h) = \frac{1}{12} \sum_i x_i w_i\)
帰無仮説についても同様で、事実上否定となります。
{id=”eq_pdh_sum12_1m”} \(P(d|\overline{h}) = \frac{1}{12} \sum_i (1 - x_i) w_i\)
これらを、事前確率が等しいという単純な仮定 ($P(h) = P(\overline{h}) = .5$) とともにベイズ方程式に代入すると、表から得たのと同じ結果が得られます。
最後に、平衡膜電位方程式を比較します。
{id=”eq_vm-eq”} \(V_m = \frac{g_e \overline{g}_e E_e + g_i \overline{g}_i E_i + \overline{g}_l E_l} {g_e \overline{g}_e + g_i \overline{g}_i + \overline{g}_l}\)
ベイズの公式では、興奮性入力が仮説の尤度または支持の役割を果たし、抑制性入力と漏れ電流の両方が帰無仮説の支持の役割を果たします。 前の分析では帰無仮説を 1 つだけ考慮したため (ただし、帰無仮説を 2 つに拡張するのは簡単です)、当面はリーク電流を無視するだけで、抑制性入力が帰無仮説の役割を果たすことになります。
興味深いことに、興奮性入力が電位を 1 に向けて駆動し (すなわち、$E_e = 1$)、抑制性 (およびリーク) 電流が電位を 0 に向けて駆動する (すなわち、$E_i = E_l = 0$) ように、確率の数値に適合するには反転電位が 0 と 1 である必要があります。
\[V_m \about P(h|d)\frac{g_e \overline{g}_e}{g_e \overline{g}_e + g_i \overline{g}_i}\] \[V_m \about \frac{P(d|h) P(h)}{P(d|h) P(h) + P(d|\overline{h}) P(\overline{h})}\]リーク電流を含む $V_m$ の完全な方程式は、抑制とリークで表される 2 つの異なる (独立した) 帰無仮説が存在する場合を反映していると解釈できます。 [[Inhibition]] はネットワーク内の他のユニットのアクティブ化に応じて動的に変化しますが、リークは検出仮説が比較される基本的な最小基準を設定する定数です。したがって、これらのそれぞれは、異なる種類の帰無仮説をサポートしていると見なすことができます。
総合すると、この分析は生物学的活性化メカニズムの満足のいく計算レベルの解釈を提供し、ニューロンが統計的に意味のある方法で情報を統合していることを保証します。