compcogneuro/web: neuron-dendrites
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/neuron-dendrites.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Activation”, “Neuroscience”] bibfile = “ccnlab.json” +++ 神経モデルの生物学的リアリズムにおける重要な境界線は、樹状突起と細胞体に対する個別のダイナミクスを含めることに関係しており、重要な計算機能が樹状突起の統合プロセスにおける非線形ダイナミクスから生じると主張する文献が多数あります ([[@HausserMel03]]; [[@MiglioreHoffmanMageeEtAl99]]; [[@PoiraziBrannonMel03]]; [[@JarskyRoxinKathEtAl05]]; [[@Spruston08]]; [[@PoiraziPapoutsi20]])。これらの追加の樹状突起ダイナミクスを捕捉する標準的な方法は、樹状突起コンパートメントと細胞体の電気的およびチャネルダイナミクスを個別にシミュレートする「マルチコンパートメント」モデルを使用することです。対照的に、AdEx ([[@BretteGerstner05]]) は単一コンパートメントの「ポイント ニューロン」モデル (体細胞のみ) ですが、実際の新皮質ニューロンの発火特性を捉えるのに優れています。明らかに、個々のニューロン内の樹状突起のダイナミクスを詳細にモデル化することに関連する計算コストには大きなトレードオフがあります。
Axon では、樹状突起のダイナミクスを捕捉するために 3 つの異なるメカニズムを使用して (いつものように) 中間点を採用しました。
-
特定のニューロンへの個別の入力ソース (つまり、pathway) はそれぞれ個別に統合され、全体的な体細胞膜電位 ($V_m$) に対する全体的な影響を決定する独自の scaling パラメーターのセットを持っています。したがって、たとえば、遠位樹状突起への入力は、近位樹状突起への入力よりも全体的に弱い可能性が高いという事実を捉えることができます。
-
経路の任意のサブセットは、その入力値がシナプス統合全体に対して additive ではなく multiplicative の影響を与えるように、modulatory input として指定できます (つまり、これらの入力が他の入力値を乗算します)。これは、再スケーリング パラメーターを使用して、乗算値が適切な範囲内にあることを確認します。
-
別の樹状突起膜電位
VmDendが計算されます。これは、細胞体への完全な統合を反映する標準Vmと比較して、樹状突起における脱分極のダイナミクスをよりよく反映します。 NMDA や GABA-B など、樹状突起に局在する電位依存性チャネルは、このVmDendによって駆動され、そうすることで、体細胞のVmを使用する場合と比較して、学習パフォーマンスが大幅に向上します。
樹状突起のダイナミクスを捕捉するこれらの方法は、おそらく生物学における関連する機能特性の妥当な割合を捕捉しますが、これらの問題をよりよく理解するには、完全に詳細なコンパートメントモデルとの直接比較によるさらなる研究が必要です。
入力経路の個別の統合とスケーリング
ここでは、特定のニューロンへのさまざまな入力ソース間の差異を考慮して、ニューロンへの興奮性コンダクタンス $g_e$ または net input がどのように計算されるかを詳細に説明します。 [[neuron]] では、コアの計算が、重みと送信アクティベーションの平均として要約されます。
{id=”eq_gesum” title=”興奮度オープン”} \(g_e(t) = \frac{1}{n} \sum_i x_i w_i\)
ここで、n はチャネルの総数、$x_i$ は添え字 i でインデックス付けされた特定の送信ニューロンの アクティビティ、$w_i$ は送信ニューロン i を受信ニューロンに接続する シナプス重み強度 です。
ここで説明するより精巧なネット入力計算 ([[Axon]] シミュレーションで実際に使用されるもの) の全体的な目標は、アクティビティの全体的なレベルが異なるさまざまな層からの入力が、ネット入力の全体的な大きさに関して受信ニューロンに同様の影響を与えることを保証すると同時に、機能的に動作し続ける方法でこれらのさまざまな入力の強度を操作できるようにすることです。たとえば、モデルが幻覚を起こさないようにするには、トップダウンの経路がボトムアップの経路よりも大幅に弱いことが重要です。
たとえば、「ローカリスト」入力層は 100 のうち 1 つのユニット (1%) だけをアクティブにすることができますが、隠れ層は 25% のアクティビティ (たとえば、100 のうち 25) を持つことができます。全体的なアクティビティ レベルのこの大きな違いにより、別の方法で補償しない場合、これらの層は受信層に対して非常に異なる影響を与えることになります。 用語的には、特定の送信層からの接続のセットを パスウェイ と呼びます。
正味入力の完全な方程式は次のとおりです。これには、最初に文字 k でインデックスが付けられたさまざまな経路にわたる二重和が含まれ、次にその内部で文字 i でインデックスが付けられた各経路の受信接続による二重和が含まれます (これらは外側の経路ループに応じて変化すると理解されています)。
{id=”eq_get” title=”ネット入力スケーリング”} \(g_e(t) = \sum_k \left[ s_k \left(\frac{r_k}{\sum_p r_p}\right) \frac{1}{\alpha_k} \frac{1}{n_k} \sum_i \left( x_i w_i \right) \right]\)
この方程式の係数は次のとおりです。
-
$s_k$ = パスウェイの絶対乗法スケーリング パラメーター。Axon
PathParamsのPathScale.Absパラメーターによって設定されます。 -
$r_k$ = 経路の相対スケーリング パラメーター。これは常に他のすべての経路の相対パラメーターの合計によって正規化されます。これが相対的なものになります。合計は一定であり、相対的な寄与のみを変更できます。これは、
PathParamsのPathScale.Relによって設定されます。 -
$\alpha_k$ = 送信層の効果的な予想アクティビティ レベル。以下で説明するように計算され、予想アクティビティ レベルの違いに関係なく経路を均等化するのに役立ちます。
-
$n_k$ = このパスウェイ内の接続の数。
効果的な期待される活動レベル $\alpha_k$ を計算するための方程式は、特定の経路上で期待されるアクティブな入力の数の整数カウントに基づいています。これには、送信層で予期されるアクティブ化と、受信される接続の数の両方が考慮されます。
たとえば、アクティビティが 1% (100 ユニット中 1 ユニットがアクティブ) で、その層からの着信接続が 1 つだけある層からのパスウェイを考えてみましょう。この 1 つの着信接続がアクティブな送信ユニットを持つ確率は平均 1% ですが、層内の「いくつかの」受信ユニットがその 1 つの送信ユニットをアクティブにする可能性が高くなります。したがって、平均予想送信確率 (1%) ではなく、レイヤー上の「最高予想アクティビティ レベル」(1) を使用します。
具体的には、数学記号の代わりに長い名前の疑似コード変数を使用した方程式は次のとおりです。
-
alpha_k = min(pct_activity * n_recv_cons + sem_extra, r_max_act_n)pct_activity= % expected activity on sending layer.n_recv_cons= number of receiving connections in pathway.sem_extra= standard error of the mean (SEM) extra buffer, set to 2 by default. This makes it the highest expected activity level by including effectively 4 SEM’s above the mean, where the real SEM depends onpct_activityand is a maximum of .5 whenpct_activity= .5.r_max_act_n = min(n_recv_cons, pct_activity * n_units_in_layer)= hard upper limit maximum on number of active inputs: can’t be any more than either the number of connections we receive, or the total number of active units in the layer
変調入力
生物学に基づいたマルチコンパートメントモデルからの一般的な結論は、樹状突起内の$V_m$の上昇の結果としてA型Kチャネルが不活性化され、樹状突起入力間の非線形ゲートのような相互作用を引き起こす可能性があるということです。十分な入力が(例えば2つの異なる経路から)入ってくると、残りの入力はすべて多かれ少なかれ線形に統合されますが、この臨界閾値を下回ると入力は大幅に減少します。アクティブな A タイプ K チャネルによってさらに減衰されます。また、通常の AMPA コンダクタンスを増幅させるために Ca スパイクを駆動する可能性がある VGCC L 型および T 型電位依存性 Ca チャネルに関連する他の合併症、樹状突起内の活性な HH Na スパイクチャネルの相対的な弱化と減衰、および阻害がどこで発生するかの問題もあります ([[@Spruston08]]; [[@PoiraziPapoutsi20]])。
考慮しなければならない重要な問題の 1 つは、関連する電気生理学的研究の多くは、麻酔をかけた動物または単離されたスライス標本 (in vitro) を使用して行われており、覚醒して行動している状況 (in activo) で行われた研究との比較では、多くの場合、重大な違いが明らかになることです。たとえば、覚醒している脳には常に合理的なバックグラウンドレベルのシナプス入力があり、A タイプ K チャネルはとにかくほとんど不活性化されています。したがって、「アップ状態」と「ダウン状態」の観点から説明されてきた神経統合とバースト特性の劇的な違いは、覚醒行動と麻酔下またはスライス標本ではほとんど消失します。
さらに、これらの調節的乗法的ダイナミクスは、一部の特定のニューロン タイプにとっては他のニューロン タイプよりも重要である可能性が高く、研究の多くは [[hipppocampus]] の CA1 錐体ニューロンと [[neocortex]] の第 5 層錐体路 (PT) ニューロンに焦点を当てています。 [[Axon]] では、モデルの計算の大部分を実行する「標準的な」層 2/3 表層皮質ニューロンは、変調ダイナミクスの恩恵を受けていないことがわかりました。これは、これらのニューロンと層 5 新皮質ニューロンの複雑さを定量化する最近の試みと一致しています ([[@BeniaguevSegevLondon21]]、詳細については [[predictive learning]] を参照)。
調節入力から恩恵を受けることが特にわかっているニューロンのタイプは次のとおりです。
- [[basal ganglia]] の MSN (中型有棘ニューロン)。
PT(錐体路、層 5、IB 固有バースト) ニューロン。
樹状突起と細胞体電位の比較
{id=”figure_dendrite-soma” style=”高さ:30em”}
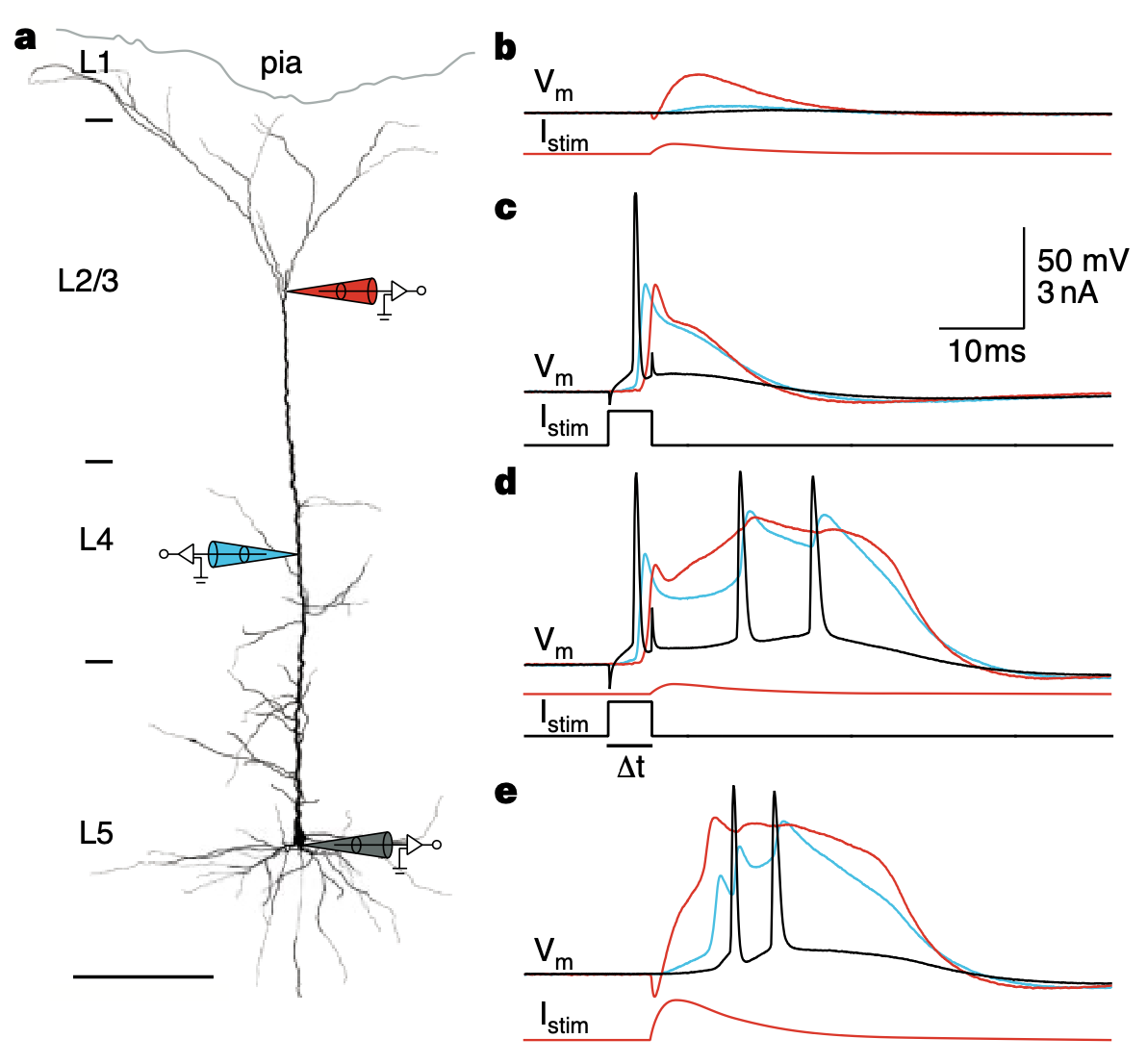
{id=”figure_vmdend” style=”高さ:30em”}
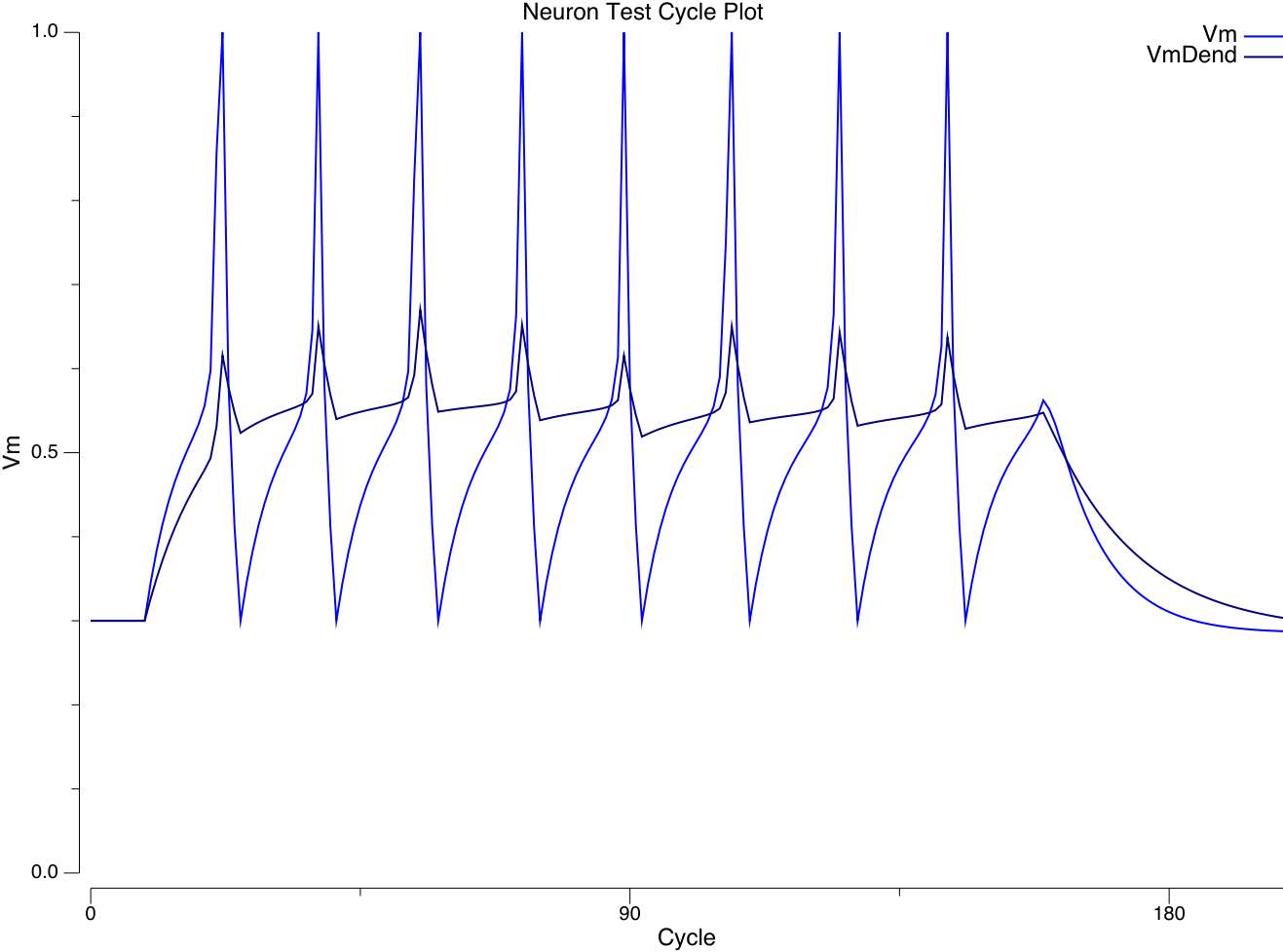
[[@^LarkumZhuSakmann99]] からの [[#figure_dendrite-soma]] は、樹状突起と細胞体における活動電位の逆伝播中の時間的積分特性に大きな違いがあることを示しています。これは軸索ニューロン モデル ([[#figure_vmdend]]、[[neuron simulation]] の VmDend 変数をクリックすると自分で再現できます) で次のメカニズムを使用してキャプチャされます。
-
古典的な HH モデルの一部である
Kdr遅延整流器チャネルは、スパイク後に膜電位をリセットして静止状態に戻します。このチャネルを使用した [[@^UrakuboHondaFroemkeEtAl08]] モデルの詳細なトレースと上記の図によれば、これは完全に瞬間的なプロセスではなく、時定数は 1 ~ 2 ms の間です。これは、全体的なスパイク動作にとっては重要ではありませんが、Vm がより現実的な Ca ベースの学習に使用される場合 (Uurakubo モデルのように) は重要です。このより現実的なVmRリセット動作は、RTau時定数を介して Axon でキャプチャされます。この時定数は、3 ms のTr不応期内にVmをVmRに減衰させます。これは、孤立したスパイクの Urakubo トレースとよく一致します。 -
Dendパラメータは、Exp スロープの一部をVmDendに適用するGbarExpパラメータと、スパイク リセット (Tr) ウィンドウ中に比例量のリーク電流を注入して Vm を少し下げ、より弱い量を反映するGbarRパラメータを指定します。Kdrは樹状突起内にあります。これにより、examples/neuronモデルの次の実行に示すように、VmDendとVmを比較する、上の図に似たトレースが生成されます。予備的な兆候は、おそらく NMDA および GABAB チャネルをより適切に関与させることにより、これがモデルのパフォーマンス全体 (これまでのところ ra25 および fsa で) に大きな利点があることを示唆しています。