compcogneuro/web: neuron
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/neuron.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Activation”, “Neuroscience”] bibfile = “ccnlab.json” +++ このページでは、[[Axon]] で使用されるスパイキング ニューロンの計算モデルについて説明します。これにより、[[neocortex]] およびその他の脳領域のニューロンの動作が正確に特徴付けられ、多くの異なるタイプの [[neuron channels|channels]] を使用して [[#neural integration]] の動作を変更し、神経生物学的に同定された広範囲のニューロン タイプを捕捉できるようになります。
| 概念的には、これらの神経統合ダイナミクスは、ニューロンの [[neuron detector | detector model]] の観点から理解できます。各ニューロンは、シナプス入力を継続的に監視し、検出されたときに他のニューロンにその結果を通知する特定のパターンを探しています。 |
{id=”figure_cortical-neuron” style=”高さ:30em”}
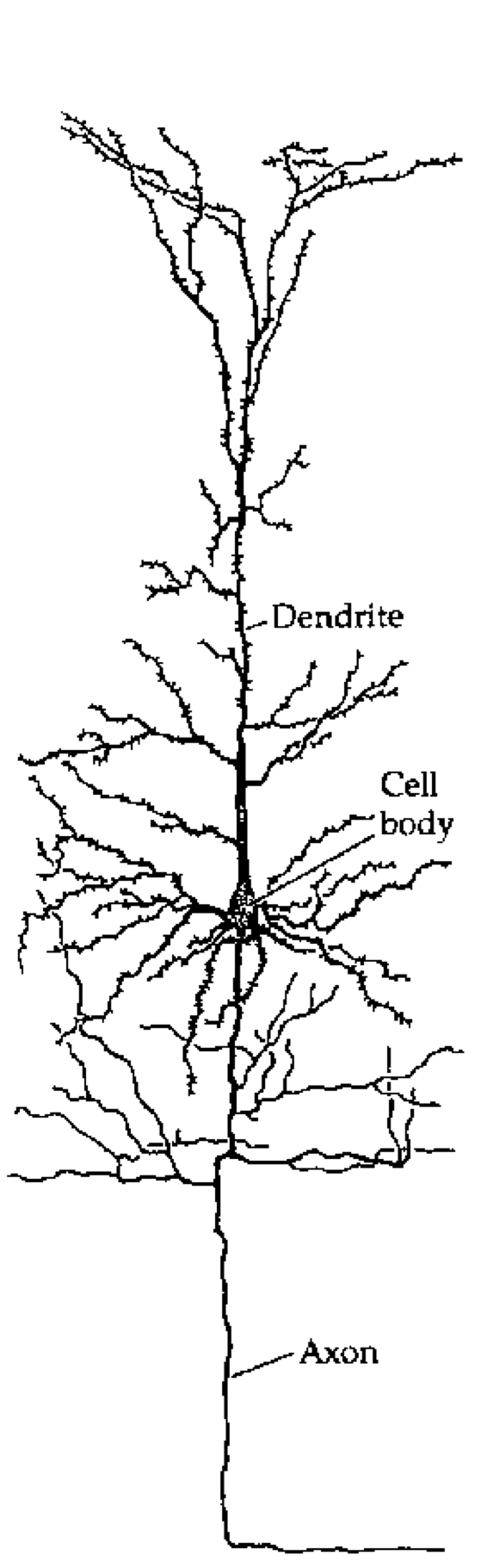
ほとんどの生物学的ニューロンには、電位の短時間 (1 ms (ミリ秒) 未満) スパイクを引き起こすイオン チャネル システムがあり、その後、電位を静止電位以下にリセットする「過分極後 (AHP)」が発生します。このスパイクは、軸索を下る脱分極の進行波を開始することによって活動電位を引き起こし、その結果_神経伝達物質_が放出され、神経伝達が他のニューロンに伝播します([[#figure_cortical-neuron]]、[[#figure_synapse]])。重要なのは、このスパイクのダイナミックな開始には効果的な 閾値 があり、この閾値を下回る電位ではスパイクが発生したり、その結果として信号が送信されたりすることはありません。
{id=”figure_synapse” style=”高さ:25em”}
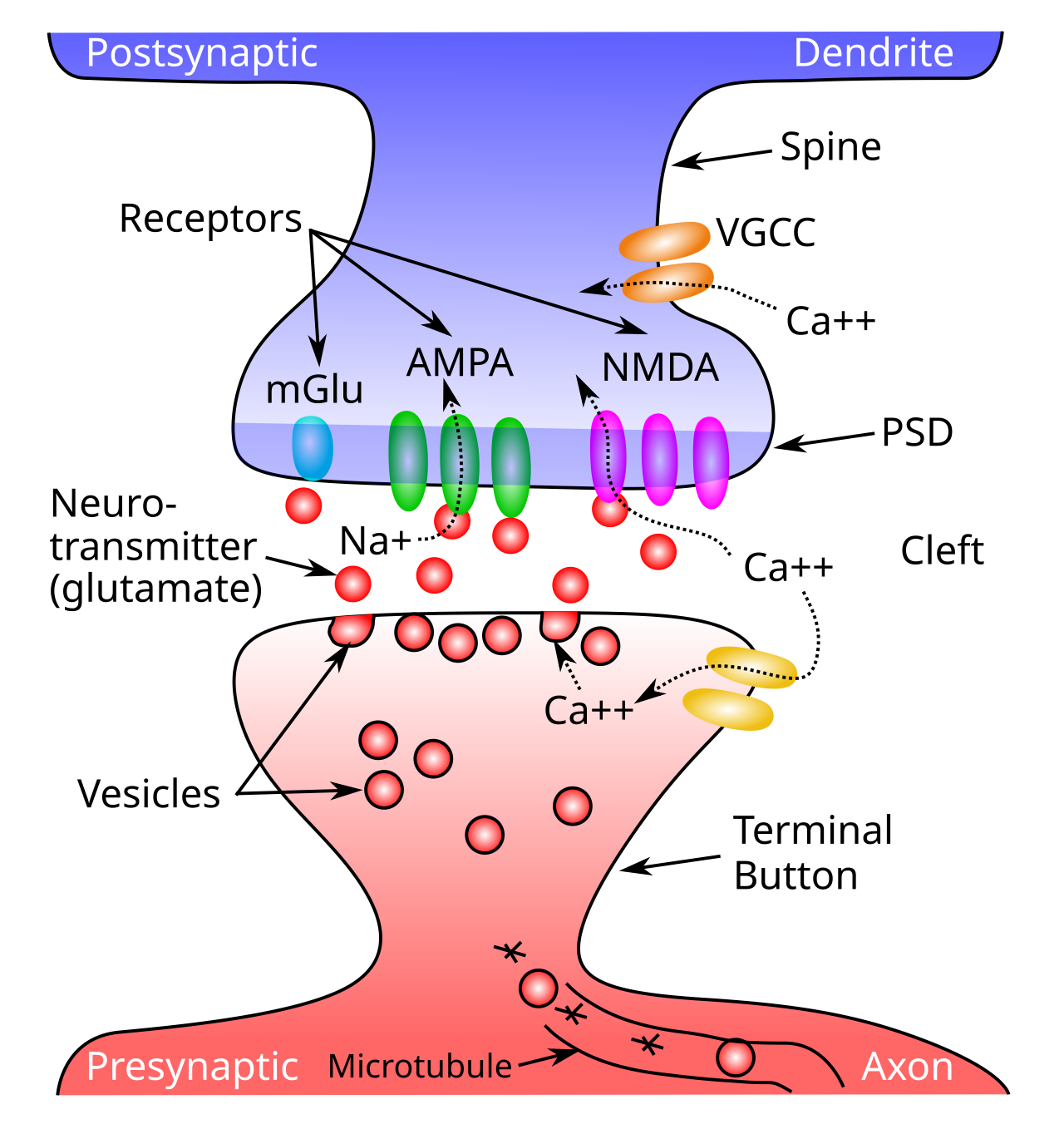
神経スパイクの根底にある $Na^+$ (ナトリウム) チャネルと $K^+$ (カリウム) チャネルは [[@^HodgkinHuxley52]] によって最初に説明され、それ以来神経科学の基礎となっています。ただし、実際の「HH」チャネル ダイナミクスは、多くのことが非常に短期間に発生するため、非常に高速な数値積分を必要とし、直接使用すると計算効率が良くありません。代わりに、軸索では、広く使用され確立されている AdEx (Adaptive Exponential; [[@BretteGerstner05]]) と呼ばれる近似を採用します。この近似は、指数関数を使用して電圧スパイクを近似し、実際の HH 方程式のスパイク レート [[adaptation]] ダイナミクスも捕捉します。
軸索スパイキング ニューロンの完全な動作を対話的に調べるには、[[neuron simulation]] を参照してください。これにより、さまざまなチャネルの動作を観察できます。
スパイク ニューロンには、[[rate code activation]] とはいくつかの重要な違いがあります。[[rate code activation]] は、[[large language models]] (LLM) で使用されるものなど、より多くの [[abstract neural network]] モデルで優勢であり、[[Leabra]] モデルで使用されました。レート コードでは、ニューロンはスパイクの瞬間レートなどを表す浮動小数点値を継続的に通信します。
神経信号が時間の経過とともに継続的に更新され、通常は約 1 ms (ミリ秒) の解像度で通信される生物学的に現実的な状況で使用される場合、レート コード ニューロンは、ギャップや休止なしに、他のニューロンに影響を与える信号を「常に」送信しています。対照的に、離散スパイクでは、特定のニューロンの出力に関してかなりの期間の「沈黙」が自然に作成され、すべてのニューロンが常に他のすべてのニューロンの影響を受けることなく、他のニューロンが順番に信号を送信できるため、この沈黙は黄金であることがわかります。実際には、これにより、スパイク ネットワークは、レート コード ニューロンと比較して、時間の経過とともに段階的かつ高次元の信号をより堅牢に統合することができます。
スパイクニューロンにおける神経統合の時間的ダイナミクスは、神経科学入門の教科書でよく議論される時間的加算と空間的加算の特性を示します。時間的に近くに到達するスパイクは相加的な影響を与える可能性があり、同様に、ニューロンの_樹状分岐_にわたるシナプス入力の空間的組織化にも重要な影響があります([[#figure_cortical-neuron]])。
以下で詳細に説明する生物学的ニューロンの [[#neural integration]] ダイナミクスは、単純な電子回路方程式を使用してよく特徴付けられます。これは、イオン チャネルを通って細胞に出入りするイオンのコンダクタンスと、脂質膜全体で測定されるニューロン全体の電位 (つまり、膜電位、$V_m$) に対するこの電流の結果としての影響を反映します。
Axon は、この標準的なコンダクタンス モデルを使用してニューロンの膜電位を更新し、さまざまな調節特性を持つ多数のより複雑なイオン チャネルを組み込んで、経時的にニューロンの全体的な情報統合特性を形成します。これらのモデルの優れた広範な取り扱いについては、ウィキペディアの 生物学的ニューロンモデル ページも参照してください。
ニューラル統合
ニューロンへの主な入力は興奮と抑制、および一定の漏れチャネルであり、そのダイナミクスは電気の基本原理を使用して理解できます。まずこのプロセスを概念的かつ直観的に理解してから、それがニューロンの根底にある電気的特性にどのように関連しているかを示します。次に、このプロセスをコンピューター上で実際にシミュレーションできる数式に変換する方法を見ていきます。
{id=”図_綱引き”}
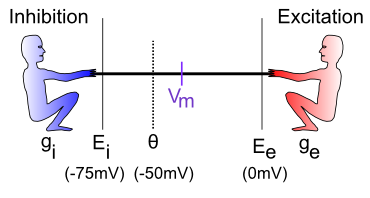
神経統合プロセスは、綱引き ([[#figure_tug-of-war]]) という観点から理解できます。この綱引きは、ニューロンが存在する周囲の細胞外媒体に対するニューロン内に存在する 電位 (ミリボルト、mV で測定) の空間で行われます。興味深いことに、この培地、およびニューロンやその他の細胞の内部は基本的に塩水であり、ナトリウム ($Na^+$) や塩化物 ($Cl^-$) などのイオンが浮遊しています。私たちは常に古代の進化環境を体内に持ち続けています。電位 (および濃度の差) により、荷電イオンが イオン チャネルと呼ばれる小さな孔を通ってニューロンに出入りし、少量の電流が生成されます。
これがどのように機能するかを確認するために、励起と抑制を考えてみましょう (現時点では、抑制とリークは事実上同じです)。重要な点は、統合プロセスは興奮と抑制の相対的な強さを反映しているということです。 興奮が抑制よりも強い場合、ニューロンの電位 (電圧) はおそらく閾値を超えて出力活動電位が発火する点まで増加します。抑制がより強い場合、ニューロンの電位は低下するため、発火の閾値を超えることから遠ざかります。
{id=”sim_vm_gbar” title=”膜の潜在的な綱引き” Collapsed=”true”} 「ゴール」 vmTau := 10.0 // VM 統合の時定数 gbarE := 0.2 gbarI := 0.4 var gbarEStr、gbarIStr、vmTauStr 文字列
## 合計時間 := 100 gE := zeros(totalTime) // 興奮性コンダクタンス gI := zeros(totalTime) // 抑制性コンダクタンス Vm := zeros(totalTime) // 膜電位 ##
func vmRun() { gbarEStr = fmt.Sprintf(“E: %7.4g”, gbarE) gbarIStr = fmt.Sprintf(“I: %7.4g”, gbarI) vmTauStr = fmt.Sprintf(“Vm タウ: %7.4g”, vmTau) ## vm := 0.0 // 現在の励磁 タウ := 配列(vmTau) gbE := 配列(gbarE) gbI := 配列(gbarI) ## for t := 範囲 100 { ## ge := gbE * (1.0 - vm) gi := gBI * (0.0 - vm) dvm := (1.0 / タウ) * (ge + gi) vm += dvm Vm[t] = vm gE[t] = gbE gI[t] = gI ## } }
vmRun()
プロットスタイル := func(s *plot.Style) { s.Range.SetMax(1).SetMin(0) s.Plot.XAxis.Label = “時間” s.Plot.XAxis.Range.SetMax(100).SetMin(0) s.Plot.Legend.Position.Left = true } プロット.SetStyler(Vm, プロットスタイラー)
fig1, pw := lab.NewPlotWidget(b) Vml := プロット.NewLine(fig1, Vm) gIl := プロット.NewLine(fig1, gI) gEl := プロット.NewLine(fig1, gE) fig1.Legend.Add(“Vm”, Vml) fig1.Legend.Add(“I”, gIl) fig1.Legend.Add(“E”, gEl)
関数 updt() { vmRun() Vml.SetData(Vm) gEl.SetData(gE) gIl.SetData(gI) pw.NeedsRender() }
func addTauSlider(label *string, val *float64, mxVal float32) { tx := core.NewText(b) tx.Styler(func(s *styles.Style) { s.Min.X.Ch(40) // 可変幅コンテンツによるクリーンなレンダリング }) core.Bind(ラベル、tx) sld := core.NewSlider(b).SetMin(1).SetMax(mxVal).SetStep(1).SetEnforceStep(true) sld.SendChangeOnInput() sld.OnChange(func(e events.Event) { updt() tx.UpdateRender() }) core.Bind(val, sld) }
func addSlider(label *string, val *float64, mxVal float32) { tx := core.NewText(b) tx.Styler(func(s *styles.Style) { s.Min.X.Ch(40) // 可変幅コンテンツによるクリーンなレンダリング }) core.Bind(ラベル、tx) sld := core.NewSlider(b).SetMin(0.02).SetMax(mxVal).SetStep(0.02).SetEnforceStep(true) sld.SendChangeOnInput() sld.OnChange(func(e events.Event) { updt() tx.UpdateRender() }) core.Bind(val, sld) }
addSlider(&gbarIStr, &gbarI, 1) addSlider(&gbarEStr, &gbarE, 1) addTauSlider(&vmTauStr, &vmTau, 50) 「」
[[#sim_vm_gbar]] は、この綱引きのダイナミックさをインタラクティブに探索できます。 E (励起) および I (抑制) スライダーをドラッグすると、これら 2 つの入力の強度を制御できます。これらの入力も視覚化を容易にするためにプロットされています。膜電位 Vm は 0 から始まり、E 入力によって 1 に向かって上昇し、I 入力によって 0 に向かって下降します。したがって、E を 0 に向かって下に移動すると、Vm がほとんど地面から離れないことがわかりますが、それが I に等しい場合 (たとえば、両方とも 0.4)、Vm はちょうど 0.5 になり、これらの対立する力の間の均等なバランスを反映しています。 E が I より大きい場合、Vm はますます高くなり、1 に近づきます。Vm Tau スライダーは、Vm が更新される rate を制御します (このようなパラメーターの重要な背景については、[[exponential integration]] を参照してください)。値が大きいほど、目標に収束するまでに時間がかかります。安定した最終 Vm 値。
EとIが両方とも同点で、両方とも 0.2、または両方とも 0.8 の場合はどうなりますか?これらのケースは、結果として得られるVmプロットに関してあらゆる点で同等ですか?そうでない場合、どのような点で異なりますか?
この神経統合プロセスの相対的な性質が理解できたでしょうか。(完全ではありませんが) 最も重要なのは、これらの値の絶対値ではなく、それらの値の間の相対的なバランスです。
[[#figure_tug-of-war]] の標準的な神経科学表記は次のとおりです。
-
$g_i$ — 抑制コンダクタンス (g はコンダクタンスの記号、i は抑制を示します) — これは抑制入力の合計の強さ (つまり、抑制的な男がどれだけ強く引っ張られているか) であり、抑制電流の強さを決定する上で重要な役割を果たします。これは生物学的に、現在開いていて抑制性イオンの流れを許可している抑制性イオンチャネルの割合に対応します (GABA 抑制の場合は 塩化物 または $Cl^-$ イオン、漏れ電流の場合は カリウム または $K^+$ イオンです)。電気愛好家にとって、コンダクタンスは抵抗の逆数です。ほとんどの人は抵抗よりもコンダクタンスの方が直感的であると考えているため、ここではそれに固執します。
-
$E_i$ — 抑制性駆動電位 — 綱引きの比喩で言えば、これはニューロン内で動作する電位スケールに対して抑制性の人がたまたま立っている位置に相当します。通常、この値は約 -75mV です。mV は ミリボルト を表し、ボルトの 1,000 分の 1 (1\/1,000) です。これらは、非常に小さなニューロンにとっては非常に小さな電位です。
-
$\Theta$ — 活動電位閾値 — これは、ニューロンが他のニューロンに信号を送るために活動電位出力を発火させる電位です。通常、これは約 -50mV です。ニューロンはこの閾値を超えると「スパイクを発火する」と表現されるため、これは 発火閾値 または スパイク閾値 とも呼ばれます。
-
$V_m$ — ニューロンの 膜電位 (V = 電圧または電位、m = 膜)。これは、ニューロンの外側の細胞外空間に対するニューロンの現在の電位です。これは、ニューロンの内側と外側を隔てる細胞膜(基本的には脂肪の薄い層)であり、実際に電位が発生する場所であるため、膜電位と呼ばれます。電位または電圧は、ある場所と別の場所の電荷量の相対的な比較です。違いがあるとき、物事が起こる可能性があるため、それは「潜在的」と呼ばれます。
For example, when there is a big potential difference between the charge in a cloud and that on the ground, it creates the potential for lightning. Just like water, differences in charge always flow “downhill” to try to balance things out. So if you have a lot of charge (water) in one location, it will flow until everything is all level. The cell membrane is effectively a dam against this flow, enabling the charge inside the cell to be different from that outside the cell. The ion channels in this context are like little tunnels in the dam wall that allow things to flow in a controlled manner. And when things flow, the membrane potential changes! In the tug-of-war metaphor, think of the membrane potential as the flag attached to the rope that marks where the balance of tugging is at the current moment.
-
$E_e$ — 興奮性駆動電位 — これは、興奮性の人が電位空間 (通常は約 0 mV) 内に立っている場所です。
-
$g_e$ — 興奮性コンダクタンス — これは興奮性入力の合計強度であり、開いている興奮性イオン チャネルの割合を反映します (これらのチャネルは ナトリウム ($Na^+$) イオンを通過させます — 私たちの最も深い思考はすべて単なる塩水が動き回っているだけです)。
{id=”図_綱引き事件”}
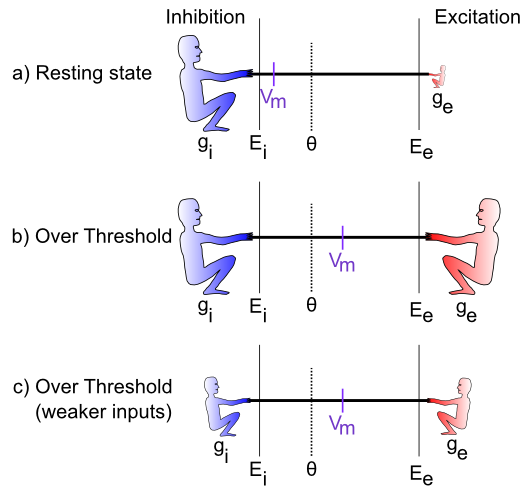
[[#figure_tug-of-war-cases]] は、綱引きシナリオの特定のケースを示しています。最初のケースでは、興奮性コンダクタンス $g_e$ は非常に低く (興奮性ガイのサイズが小さいことで示されます)、これは静止しているニューロンを表しており、他のニューロンから多くの興奮性入力信号を受信していません。この場合、抑制/漏出ははるかに強く引っ張られ、膜電位 ($V_m$) を -70mV 領域付近に維持します。これはニューロンの 静止電位 とも呼ばれます。したがって、活動電位閾値 $\Theta$ を下回っているため、ニューロン自体は信号を出力しません。
次の (b) の場合、励起は抑制と同じくらい強いので、膜電位を範囲のほぼ中央まで引き上げることができます。発射閾値は範囲の下端にあるため、これは閾値を超えてスパイクを発射するのに十分です。ニューロンはその信号を他のニューロンに伝達し、脳のネットワーク内の全体的な情報の流れに貢献します。
最後のケース (c) は、統合プロセスが興奮と抑制の相対的なバランスにどのように影響されるかを示しています。両方が全体的に弱い場合でも、ニューロンは発火閾値を超える可能性があります。これは、たとえば、環境に応じて全体の光の量が大きく変化する可能性がある視覚系において重要です(たとえば、明るい晴れた日にスノーボードをするのと、日没後に深い森の中を歩くのを比較するなど)。視覚系に入ってくる光の総量は、視覚ニューロンが経験する興奮量に加えて、「バックグラウンド」レベルの抑制も引き起こします。したがって、明るいときは、暗いときと比較して、ニューロンは興奮と抑制の両方をより多く受け取ります。 これにより、全体的な入力レベルに大きな違いがあるにもかかわらず、ニューロンが物事を検出するための感度範囲内に留まることができます。
スパイク出力
膜電位 $V_m$ は他のニューロンに直接伝達されません。代わりに、閾値の影響を受けるため、最も強い相対レベルの興奮のみが伝達され、その結果、脳内の情報がより効率的かつコンパクトにエンコードされます。人間の言葉で言えば、ニューロンは「TMI」(過剰な情報)の共有を避け、「グリセの格言」 に従っているかのように、関連性のある重要な情報のみを伝達します。
{id=”figure_spiking” style=”高さ:30em”}
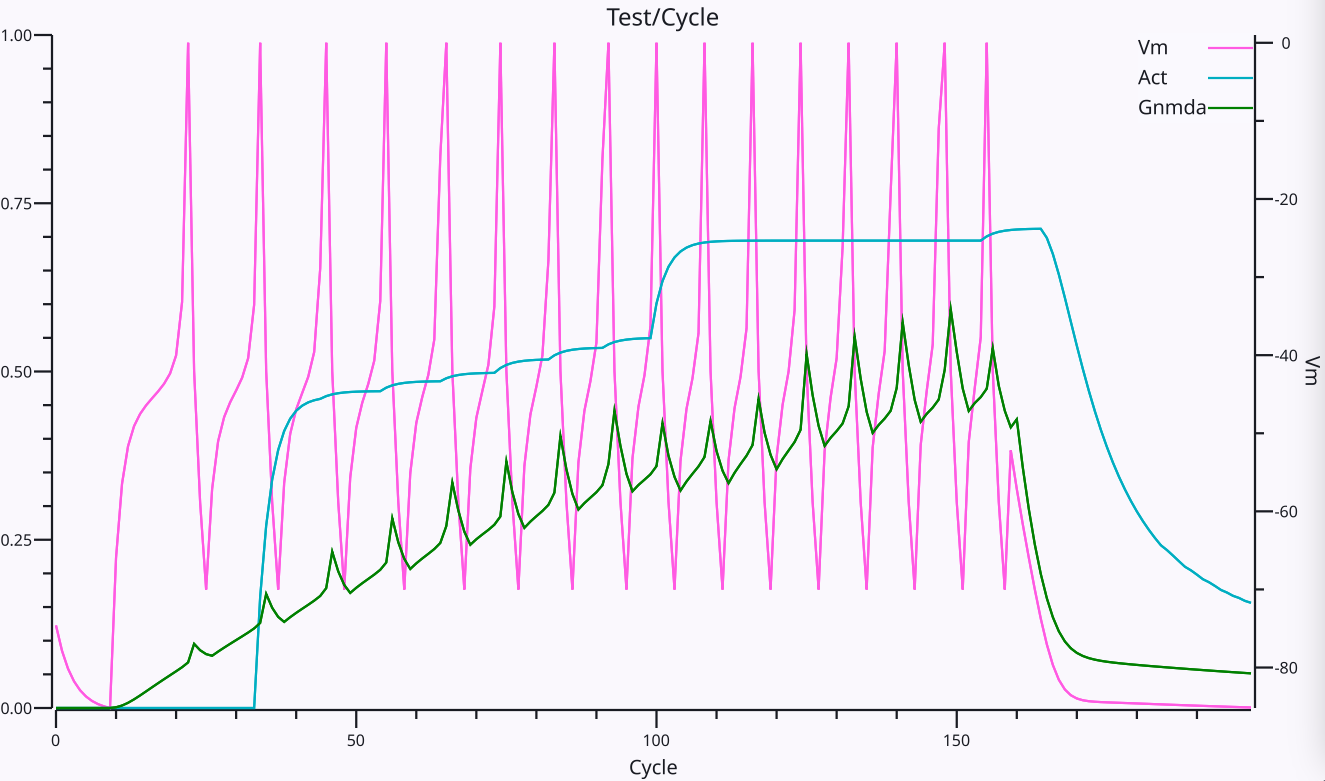
上で説明したように、$V_m$ が閾値を超えたときの離散スパイクの発火は、[[@HodgkinHuxley52]] によって最初に説明されたように、高速 $Na^+$ および $K^+$ チャネルを介して生物学的ニューロンで発生します。これらの高速ダイナミクスを近似するために、AdEx (Adaptive Exponential; [[@BretteGerstner05]]) モデルを使用します。スパイクの全体的なサイクルとその後の過分極後 (AHP)、および継続的な興奮 ([[#figure_spiking]]) による $V_m$ の上昇があり、その結果、興奮と抑制の相対的なバランスを反映する全体的な スパイク レートが得られます。
[[rate code activation]] モデルでは、この予想されるスパイク率はニューロンへの入力から直接計算され、その後、他のニューロンへの全体的な 活性化 値として計算されます。このレート コードの近似値の妥当性についてはかなりの議論があり、[[rate code activation]] ページで詳しく説明されています。簡単に言うと、[[Leabra]] モデルはレート コード シグナリングを使用しており、離散スパイク [[Axon]] モデルとの直接比較により、レート コードは離散スパイク モデルと同じ機能的および認知的現象の多くを捕捉できるが、全体的にはより脆弱であり、段階的な確率的情報の表現と、ネットワーク全体の速度と応答性との間に大きなトレードオフが必要であることが示されています。
具体的には、離散スパイクの重要な機能上の利点は、新しい刺激入力に関するかなりの情報が、最初のスパイク応答 ([[@ThorpeDelormeVanRullen01]]) のカスケードを介してネットワーク全体に迅速に伝播できることです。電気生理学的記録によると、この最初の反応波は、最初に新皮質に到達してからおよそ 50 ~ 70 ミリ秒という比較的短い時間枠内で刺激に関する重要な情報を伝達し、これらの最初のスパイクの相対的なタイミングはその後の発火速度と強く相関していることが示されています。ただし、その後の発火は、刺激の多くの重要な特性を解決するためにも重要であり、トップダウン信号とボトムアップ信号が一貫した解釈に収束するための窓を提供します。したがって、離散スパイクにより、高速な初期応答とその後のより段階的な信号の効果的な統合という「両方の長所」が可能になります。
数学的定式化
ニューロンが興奮と抑制をどのように統合するかについての上記の直感的な理解により、一連の数式を使用してモデルでこの動作をシミュレートする方法がわかります。
ニューラル統合
まず、綱引きの各側が引く「強さ」を形式化してから、それが結果として $V_m$ の「旗」をどのように動かすかを示します。これにより、綱引きの動的統合プロセスの明示的な方程式が提供されます。次に、この綱引き方程式のコンダクタンス係数を、ニューロンに入力される入力とシナプスの重みの関数として実際に計算する方法を示します (今のところ興奮性入力に焦点を当てています)。
これらの方程式の背後にある重要な考え方は、綱引きの各側が、その全体的な強さ (コンダクタンス) と、「旗」 ($V_m$) がその位置からどのくらい離れているか (推進ポテンシャル E で示される) の両方に比例する強さで引っ張るということです。牽引車が所定の位置に固定され、$V_m$ フラグが所定の位置 (E) に到達したときに腕が完全に収縮し、ロープを再び握ることができず、この時点でそれ以上引っ張ることができないと想像してください。この考えを方程式に入れると、興奮側が発揮する「力」または 電流 を次のように書くことができます。
{id=”eq_Ie” title=”興奮”} \(I_e = g_e \left(E_e-V_m\right)\)
興奮性電流は $I_e$ (I は電流を表す伝統的な用語で、e は再び励起を表します) であり、コンダクタンス $g_e$ と膜電位が興奮性駆動電位からどのくらい離れているかの積です。 $V_m = E_e$ の場合、興奮側が綱引きに「勝った」ことになり、もう引っ張ることはなくなり、電流はゼロになります (コンダクタンスがどれほど大きくても、0 を掛けたものは 0 になります)。興味深いことに、これは、$V_m$「フラグ」がそこから最も離れているとき、つまりニューロンが静止電位にあるとき、興奮性側が最も強く引っ張られることも意味します。したがって、十分に休息しているときにニューロンを興奮させるのが最も簡単です。
この方程式は オームの法則 として知られており、最も基本的な電気法則の 1 つであり、抵抗 (1 / コンダクタンス) の観点から学習したことがあるかもしれません。この場合、コンダクタンスはイオンの流れを可能にするチャネル開口部のサイズと数として直接理解できるため、より直感的です。
同じ基本方程式を抑制側にも書くことができ、リーク「側」にも個別に書くことができます (これは抑制項のクローンとして再導入できます)。
{id=”eq_Ii” title=”抑制”} \(I_i = g_i \left(E_i-V_m\right)\)
{id=”eq_Il” title=”リーク”} \(I_l = g_l \left(E_l-V_m\right)\)
(これらの式すべてで添字のみが異なります)。
次に、これら 3 つの異なる電流を合計して 正味電流 を取得します。これは、ニューロンの膜を横切る (イオン チャネルを通る) 荷電イオンの正味の流れを表します。
{id=”eq_Inet” title=”ネット電流”} \(I_{ネット} = I_e + I_i + I_l\)
\[= g_e \left(E_e-V_m\right) + g_i \left(E_i-V_m\right) + g_l \left(E_l-V_m\right)\]では、正味電流とは何の役に立つのでしょうか?電気は水のようなもので、それ自体を平らにするために流れることを思い出してください。水が多い場所から少ない場所へ水が流れると、最初の水は少なくなり、2 番目の水は増えます。同じことが電流でも起こります。電流の流れによってニューロン内の膜電位 (水の高さ) が変化します。
{id=”eq_Vm” title=”膜電位”} \(V_m\left(t\right) = V_m\left(t-1\right) + \frac{1}{\tau_{vm}} I_{net}\)
$V_m(t)$ は $V_m$ の現在の値で、前のタイム ステップ $V_m(t-1)$ の値から更新されます。$\tau_{vm}$ は膜電位の変化速度を決定する [[exponential integration]] 時定数です。これは主にニューロンの膜の静電容量を反映します。
上記の 2 つの方程式は、コンピューター上でニューロンをシミュレートするために必要な最も重要なツールです。これは、膜電位が抑制性入力、漏れ入力、および興奮性入力の関数としてどのように変化するかを示します。これらの入力コンダクタンスの特定の数値と $V_m$ の開始値が与えられると、上記の方程式に従って新しい $V_m$ 値を反復 計算できます。これは、実際のニューロンが同様の入力にどのように応答するかを正確に反映します。
要約すると、すべてを実行する上記の方程式の単一バージョンを次に示します。
{id=”eq_Vm-full” title=”完全なアップデート”} \(V_m(t) = V_m(t-1) + \frac{1}{\tau_{vm}} \left[ g_e (E_e-V_m) + g_i (E_i-V_m) + g_l (E_l-V_m) \right]\)
上記のマイナス記号の問題に気付いた方、またはこれらの式の出典について詳しく知りたい方は、[[neuron electrophysiology]] を参照してください。ここまでの説明に十分満足している場合は、これらの入力コンダクタンスをどのように計算するか、そしてニューロンの出力信号を駆動するために $V_m$ 値をどのように処理するかを理解することに自由に進んでください。
入力コンダクタンスの計算
興奮性入力コンダクタンスと抑制性入力コンダクタンスは、現在開いていてイオンの流れを可能にしている各タイプのイオン チャネルの総数を表します。実際のニューロンでは、これらのコンダクタンスは通常、$10^{-9}$ ジーメンスであるナノ ジーメンス (nS) で測定されます (非常に小さい数 – ニューロンは非常に小さい)。通常、神経科学者はこれらのコンダクタンスを 2 つの要素に分割します。
-
$\overline{g}$ (「g-bar」) — すべてのイオン チャネルが開いた場合に発生する最大コンダクタンスを決定する定数値。
-
$g(t)$ — 現時点で、イオン チャネルの総数の何パーセントが現在開いているかを示す動的に変化する変数 (0 から 1 の間で変化)。 [[#Units and parameters]] に示すように、シミュレーションで計算された値はすべてこの値に入り、$\overline{g}$ はこれらの正規化された 0..1 値を適切な神経生物学的単位に変換するだけです。
したがって、対象となる総コンダクタンスは次のように記述されます。
{id=”eq_gbar-e” title=”興奮性コンダクタンス”} \(\overline{g}_e g_e(t)\)
{id=”eq_gbar-i” title=”抑制性コンダクタンス”} \(\overline{g}_i g_i(t)\)
{id=”eq_gbar-l” title=”漏れコンダクタンス”} \(\overline{g}_l\)
(リークは定数であるため、動的に変化する値はなく、一定の G バー値のみを持つことに注意してください)。
このように項を分離すると、各タイプの開いたイオン チャネルの割合または割合を計算することだけに集中する必要があるため、コンダクタンスの計算が容易になります。これは、ニューロンへの各シナプス入力で開いているイオン チャネルの平均数を計算することで実行できます。 [[neuron channels]] で説明したように、興奮 ([[neuron channels#AMPA]]) と抑制 ([[neuron channels#GABA-A]]) に関与する高速シナプス チャネルは、新しい神経伝達物質の結合に 1 ミリ秒未満で応答し、この最初の結合の後、数ミリ秒間開いたままにする指数関数的な減衰定数を持っています。
興奮性コンダクタンスの上昇 (開始) 成分は、AMPA チャネルに結合するシナプス前送信ニューロンによって放出される新しい グルタミン酸 神経伝達物質の関数として計算されます ([[#figure_synapse]] に示すように)。シミュレーション コードでは GeRaw としてラベル付けされます。
{id=”eq_ge-raw” title=”興奮性生グルタミン酸”} \(g_{e-raw}(t) = \frac{1}{n} \sum_i x_i w_i\)
ここで、$x_i$ は、下付き文字 $i$ によってインデックス付けされた特定の送信ニューロンの 0 または 1 スパイク活動であり、以下で説明するように、シナプスに到着する際に軸索コンダクタンスの遅延の影響を受けます。 $w_i$ は、送信ニューロン $i$ を受信ニューロンに接続する シナプス重み強度 であり、このシナプスの AMPA 受容体の数と有効性の関数です。 $n$ は、関連するすべてのシナプス入力にわたるそのタイプ (この場合は興奮性) のチャネルの総数であり、この用語を正規化するために使用します。 [[neuron detector]] で説明したように、シナプスの重みは、受信ニューロンがどのようなパターンに敏感であるかを決定し、学習に適応するものです。この方程式は、興奮性コンダクタンスの総量の計算に数学的にどのように入力されるかを示しています。
結果として得られる AMPA 興奮性コンダクタンスは、この生の新しい入力と、以前に開かれたチャネルの指数関数的減衰から時間の経過とともに積分されます。
{id=”eq_ge” title=”興奮性 AMPA コンダクタンス”} \(g_e(t) = g_{e-raw}(t) + g_e(t-1) \left( 1 - \frac{1}{\tau_d} \right)\)
[[#eq_ge-raw]] は、ニューロンが受信している入力量を決定する非常に単純な機能を実行することを示唆しています。さまざまなソースすべてから入力を合計するだけです (合計ではなく平均を計算して比率を計算します)。各入力ソースは、送信者のアクティブ度に、受信ニューロンがその情報をどの程度気にするかを掛け合わせた値に比例して寄与し、シナプスの重み値によって決まります。この平均合計投入量を 正味投入量 とも呼びます。これは、[[abstract neural network]] モデルで使用される用語です。
同じタイプの方程式が抑制性入力コンダクタンスにも適用されます。抑制性入力コンダクタンスは、抑制性送信ニューロンの活性化と抑制性重み値の積という観点から計算され、GABA 神経伝達物質と GABA-A 受容体が関与します。
AMPA 受容体コンダクタンスは、約 5 ミリ秒の時定数 $\tau_d$ ([[@HestrinNicollPerkelEtAl90]]) で指数関数的に減衰しますが、GABA-A 阻害チャネルの時定数は約 7 ミリ秒 ([[@XiangHuguenardPrince98]]) です。
機能的には、離散スパイク入力のこの追加のトレースは、時間の経過に伴う入力の「時間的合計」をサポートするため、この時間積分ウィンドウ内に到着する入力を加算して、全体の興奮性コンダクタンスを大きくすることができます。
{id=”table_conduction” title=”軸索伝導遅延”} |経路 |最小 |平均値または中央値 | |—————–|———–|—————————-| |皮質皮質 | 2ミリ秒 | 2.3 (マグノビジュアル) – ~10 ミリ秒 | |皮質視床 | 2ミリ秒 | ~10ミリ秒 | |視床皮質 | 0.5ミリ秒 | ~1 ミリ秒 | |巨大な | ~2ミリ秒 | ~10ミリ秒 |
活動電位が軸索を伝播するには時間がかかります。これは一般に、移動距離と軸索の髄鞘形成の程度の関数です。ミエリンは、軸索膜の静電容量を減少させることで伝導速度を速める絶縁体として機能します。 [[#table_conduction]] は、さまざまな情報源および種から集められた 学者ペディア の近似値を示します (例: [[@FerrainaPareWurtz02]]、[[@Swadlow90]]、[[@Swadlow00]])。この時点でほとんどのモデルが比較的小さな脳を表すという仮定の下で、デフォルト値 2 ms でこの軸索伝導遅延をモデルに含めます。実際には、10 ミリ秒の値を使用してもモデルのパフォーマンスに大きな影響はありません。
異なる入力ソースからの入力をどのように統合するか (つまり、異なるソース脳領域から特定の受信ニューロンへの投影) についてはさらに複雑な点があり、これについては [[neuron dendrites]] で説明します。これらのメカニズムは、樹状突起上のさまざまな分岐に入る入力に関連する生物学的複雑性の一部を説明します ([[@MiglioreHoffmanMageeEtAl99]]; [[@PoiraziBrannonMel03]]; [[@JarskyRoxinKathEtAl05]])。
{id=”sim_vm_g” title=”膜電位の綱引き: 海流” Collapsed=”true”} 「ゴール」 vmTau := 10.0 // VM 統合の時定数 gbarE := 0.2 gbarI := 0.4 var gbarEStr、gbarIStr、vmTauStr 文字列
## 合計時間 := 100 iE := zeros(totalTime) // 興奮電流 iI := zeros(totalTime) // 抑制電流 Vm := zeros(totalTime) // 膜電位 ##
func vmRun() { gbarEStr = fmt.Sprintf(“gbar E: %7.4g”, gbarE) gbarIStr = fmt.Sprintf(“gbar I: %7.4g”, gbarI) vmTauStr = fmt.Sprintf(“Vm タウ: %7.4g”, vmTau) ## vm := 0.0 // 現在の励磁 タウ := 配列(vmTau) gbE := 配列(gbarE) gbI := 配列(gbarI) ## for t := 範囲 100 { ## つまり := gbE * (1.0 - vm) ii := GBI * (0.0 - vm) dvm := (1.0 / タウ) * (ie + ii) vm += dvm Vm[t] = vm iE[t] = ie iI[t] = -ii ## } }
vmRun()
プロットスタイル := func(s *plot.Style) { s.Range.SetMax(1).SetMin(0) s.Plot.XAxis.Label = “時間” s.Plot.XAxis.Range.SetMax(100).SetMin(0) s.Plot.Legend.Position.Left = true } プロット.SetStyler(Vm, プロットスタイラー)
fig1, pw := lab.NewPlotWidget(b) Vml := プロット.NewLine(fig1, Vm) iIl := プロット.NewLine(fig1, iI) iEl := プロット.NewLine(fig1, iE) fig1.Legend.Add(“Vm”, Vml) fig1.Legend.Add(“I_i”, iIl) fig1.Legend.Add(“I_e”, iEl)
関数 updt() { vmRun() Vml.SetData(Vm) iEl.SetData(iE) iIl.SetData(iI) pw.NeedsRender() }
func addTauSlider(label *string, val *float64, mxVal float32) { tx := core.NewText(b) tx.Styler(func(s *styles.Style) { s.Min.X.Ch(40) // 可変幅コンテンツによるクリーンなレンダリング }) core.Bind(ラベル、tx) sld := core.NewSlider(b).SetMin(1).SetMax(mxVal).SetStep(1).SetEnforceStep(true) sld.SendChangeOnInput() sld.OnChange(func(e events.Event) { updt() tx.UpdateRender() }) core.Bind(val, sld) }
func addSlider(label *string, val *float64, mxVal float32) { tx := core.NewText(b) tx.Styler(func(s *styles.Style) { s.Min.X.Ch(40) // 可変幅コンテンツによるクリーンなレンダリング }) core.Bind(ラベル、tx) sld := core.NewSlider(b).SetMin(0.02).SetMax(mxVal).SetStep(0.02).SetEnforceStep(true) sld.SendChangeOnInput() sld.OnChange(func(e events.Event) { updt() tx.UpdateRender() }) core.Bind(val, sld) }
addSlider(&gbarIStr, &gbarI, 1) addSlider(&gbarEStr, &gbarE, 1) addTauSlider(&vmTauStr, &vmTau, 50) 「」
[[#sim_vm_g]] は、これらの神経統合ダイナミクスのインタラクティブな概要を提供し、[[#sim_vm_gbar]] のようなコンダクタンスの代わりに興奮性と抑制性の電流をプロットします。抑制電流は絶対値としてプロットされているため (式では実際には負の符号が付いています)、興奮電流と直接比較できます。
以前と同様、$V_m$ 値は励起と抑制の間の相対的なバランスを反映し続けますが、電流に関してそのバランスがどのように生じるかを確認できます。励起と抑制の強さを制御する gbar スライダーに何を行っても、結果として生じる電流は時間の経過とともに常に同じ大きさに収束することがわかります。これはなぜでしょうか?
AdEx スパイクの方程式
[[@^HodgkinHuxley52]] 方程式に従った実際のニューロンのスパイクは、膜電位が臨界閾値レベルを超えると膜電位の急激な上昇を引き起こす「電位依存性ナトリウム チャネル」の高速シーケンスによって駆動され、続いて膜電位を静止電位未満のレベル (過分極後、AHP) 未満のレベルに急速に戻す「ナトリウム依存性カリウム チャネル」が続きます。
これらの HH ダイナミクスをモデルに実装するには、計算速度が大幅に低下する非常に高速な時間積分速度が必要です。そのため、膜電位がスパイクしきい値を超えるたびに Spike 値を 1 に設定するだけの、より単純な近似を使用します。このスパイク値は、次のタイム ステップで 0 にリセットされます。これは、スパイク インパルスが通常約 1 ミリ秒続くという事実を考慮しており、これが、使用する数値積分ステップ サイズです。
このロジックは、疑似コードで表現する方が簡単です。
if (Vm > Theta) then: Spike = 1; Vm = Vm_r; else Spike = 0
where Theta is the effective spiking threshold, and Vm_r is the “reset” or “refractory” membrane potential that the Hodgkin-Huxley sodium-gated potassium channels produce. The extra potassium from these channels stays around for a few additional milliseconds, producing a refractory period when the neuron is effectively inactivated and cannot spike again. We use a time constant of 3 ms for this refractory period, during which we simply do not update the Vm variable.
To capture the HH spiking dynamics more accurately, yet still efficiently, [[@^BretteGerstner05]] added an exponential term to the Vm computation (introduced by [[@Fourcaud-TrocmeHanselVreeswijkEtAl03]]), that simulates the rapid rise caused by the voltage-gated sodium channels:
{id=”eq_adex-exp” title=”Exponential rise”} \(\overline{g}_l \Delta_T e^{\frac{V_m - \Theta}{\Delta_T}}\)
where $\Delta_T = 2 mV$ is the slope factor for the exponential function, and $\Theta = -50 mV$ is the spiking threshold.
| The other main feature of the AdEx model is [[adaptation]] which makes it harder for the neuron to fire spikes as a function of ongoing activity. This is implemented in [[Axon]] using specialized [[neuron channels | channels]]. |
Units and parameters
{id=”table_units” title=”Neural scale units”} | Dimension | Unit | Multiplier | Axon Unit | |————-|——————————|————|—————-| | potential | volt (V) | 0.001 | mV millivolt | | current | ampere (A) | $10^{-12}$ | pA picoamperes | | time | second (s) | 0.001 | ms millisecond | | conductance | siemens S = A / V | $10^{-9}$ | nS nanosiemens | | capacitance | farad F = (s ⋅A) / V | $10^{-12}$ | pF picofarads |
[[#table_units]] shows the standard neural-scale units that are used in [[Axon]] for all of the electrical parameters. [[#table_units-ex]] shows some example parameters in these units, with relevant values from [[@^DestexheMainenSejnowski98]] and [[@^MiglioreHoffmanMageeEtAl99]].
{id=”table_units-ex” title=”Neural scale parameters”} | Parameter | Value | |—————————————————————–|———| | Resting potential | -70 mV | | Spiking threshold $\Theta$ | -50 mV | | $g_{ampa}$ = conductance per excitatory AMPA channel | 0.05 nS | | $g_{syn}$ = conductance per excitatory synapse = ~20 channels | 1 nS | | $\overline{g}e$ = ~ max total excitatory input = ~100 synapses | 100 nS | | $\overline{g}{leak}$ | 20 nS | | max $I_e(V=-70 mV)$ | 7000 pA | | standard membrane capacitance C | 281 pF | | change in V over 1 ms from $I_e(V=-70 mV)$ = I_e / C | 25 mV |
[[#table_erev]] shows the full set of reversal potentials for the basic channels:
{id=”table_erev” title=”Electrical potentials”} | Parameter | Value | |—————————-|———| | Resting potential | -70 mV | | Leak $E_l$ | -70 mV | | Excitatory $E_e$ | 0 mV | | Inhibition $E_i$ | -90 mV | | Spiking threshold $\Theta$ | -50 mV | | Exp Slope $\Delta_T$ | 2 mV |
Other channels
See the page on [[neuron channels]] for more details about the biological properties of the excitatory and inhibitory channels, and a number of other channel types that further modify the dynamics of neurons in functionally important ways. The most important of these additional channels are [[adaptation]] channels that cause the neuron to reduce its firing over time in response to sustained excitatory input, and the synergistic effects of [[neuron channels#NMDA]] and [[neuron channels#GABA-B]] channels that work together to support [[stable activation]] states which are critical for learning.
Additional details
There are several additional in-depth pages providing more details about biological and computational neurons:
-
[[Neuron simulation]]: provides an interactive exploration of the full set of [[Axon]] neuron equations responding to a simple pulse of excitation.
-
[[Neuron detector]]: describes the high-level conceptual model of a neuron as a detector, including a simulation thereof.
-
[[Neuron electrophysiology]]: more detailed description of the electrophysiology of the neuron, and how the underlying concentration gradients of ions give rise to the electrical integration properties of the neuron.
-
[[Neuron dendrites]]: details on how excitatory and other neural inputs are computed and scaled across multiple different input projections, in ways that capture some of the additional computational power of dendritic processing within individual neurons.
-
[[Neuron equilibrium potential]]: shows how to derive the equilibrium (steady-state) $V_m$ equation, which clearly exhibits the relative tug-of-war dynamic.
-
[[Neuron bayesian Neuron as a Bayesian optimal detector]]: shows how the equilibrium membrane potential represents a Bayesian optimal way of integrating the different inputs to the neuron.
Links
Next in [[Intro Book]]: [[Neuron Detector]]