compcogneuro/web: oreilly-2026-cortlearn
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/oreilly-2026-cortlearn.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Name = “OReilly (2026) Cortical Learning” Title = “This is how the Neocortex Learns” Authors = “Randall C. O’Reilly” Affiliations = “Astera Institute, Department of Psychology and Center for Neuroscience, University of California Davis” Abstract = “A sufficient account of how the neocortex learns must meet three criteria: 1. Computationally, it must approximate a powerful, general-purpose learning algorithm known to scale to human-level intelligence; 2. Algorithmically, it must be implementable using known, well-established neural circuits within the neocortex and associated brain structures; 3. Implementationally, there must be a detailed account for how all of the algorithmic mechanisms actually function at a neurochemical level. At present, there is only one framework that meets all of these criteria: error-driven predictive learning via temporal derivatives, driven by corticothalamic circuits, based on competitive kinase synaptic plasticity induction mechanisms. This has been implemented in the Axon neural simulation framework using spiking neurons, and demonstrated to learn across a wide range of challenging cognitively-motivated tasks.” Date = “2026-05-16” Categories = [“Papers”] bibfile = “ccnlab.json” +++ ## 導入
新皮質がどのように学習するかを理解することは、おそらく人間の知能を理解する上で最も重要なステップです。なぜなら、私たちの認知機能は、この脳構造内での長年の経験に基づく学習を経て現れるからです。この脳構造は哺乳類に特有であり、霊長類、特に人間で最も大きく拡張されています。 [[@^Marr82]] に続いて、新皮質学習の理論を評価できるレベルは、計算、 アルゴリズム、、_ の 3 つのレベルがあります。この論文の結論は、時間微分 モデル ([[@JangFloresOReillyEtAl26]]) と名付けた現在の理論は 1 つだけであり、これら 3 つのレベルにわたって十分な説明を提供しており、したがって、学習がどのように行われるかについての最も実行可能な作業仮説を表しているということです。大脳新皮質は学習します。
この理論は現在の著者によって長年にわたって開発されたものであるため、この評価は必然的に確証バイアスの影響を受けます。したがって、この最も中心的な科学的問題の理解を進めるために、この結論に対する建設的な批判と、同じ基準に従った競合する代替案の評価を強く歓迎します。
計算
新皮質学習メカニズムが原理的に経験主導型学習を通じて人間レベルの知能を達成できるはずである理由を理解するための数学的に証明された根拠はあるのでしょうか?この学習メカニズムの実装は実際にこの能力を実証しましたか?この基準を満たす学習メカニズムは、エラー逆伝播 ([[@RumelhartHintonWilliams86]]; [[@WidrowHoff60]]; [[@Werbos74]]) の 1 つだけです。これは、基本的に他のすべての種類の最新の強力なニューラル ネットワーク モデルとともに、トランスフォーマー アーキテクチャ ([[@VaswaniShazeerParmarEtAl17]]) に基づく現代の大規模言語モデル (LLM) での学習を推進します。現時点では、これは基本的に一か八かの事件であり、他にこれに近いものはありません。
誤差逆伝播を単純化または近似する方法については、多くの場合生物学的実装に適したものにすることを目的として多くの提案がなされてきましたが、実際には、現在の最先端 (SOTA) モデルの事実上普遍的な標準であり続けている確率的勾配降下法 (SGD) 手順の座を奪うことができたものは他にありません。したがって、生物学に基づいたメカニズムが完全な誤差逆伝播計算の合理的な近似を実装することが可能であれば、これらの他の変形の関連性は低下します。いずれにせよ、エラーバックプロパゲーションが、他のすべてのものと比較される計算レベルの「ゴールドスタンダード」であることは疑いの余地がありません。
アルゴリズム
回路および構造レベルで既知の神経生物学的メカニズムと原理的に互換性のある方法で、計算レベルのメカニズムをアルゴリズム的に実装できるでしょうか?既知の新皮質回路を使用して誤差逆伝播を実装する方法についてはさまざまな提案があります (最近のレビューについては [[@LillicrapSantoroMarrisEtAl20]] を参照)。しかし、次に説明する最終的な実装基準も満たしながら、既知の新皮質 (および視床皮質) の特性すべてに包括的に一致する提案は 1 つだけです。
{id=”figure_bidir-err” style=”高さ:25em”}
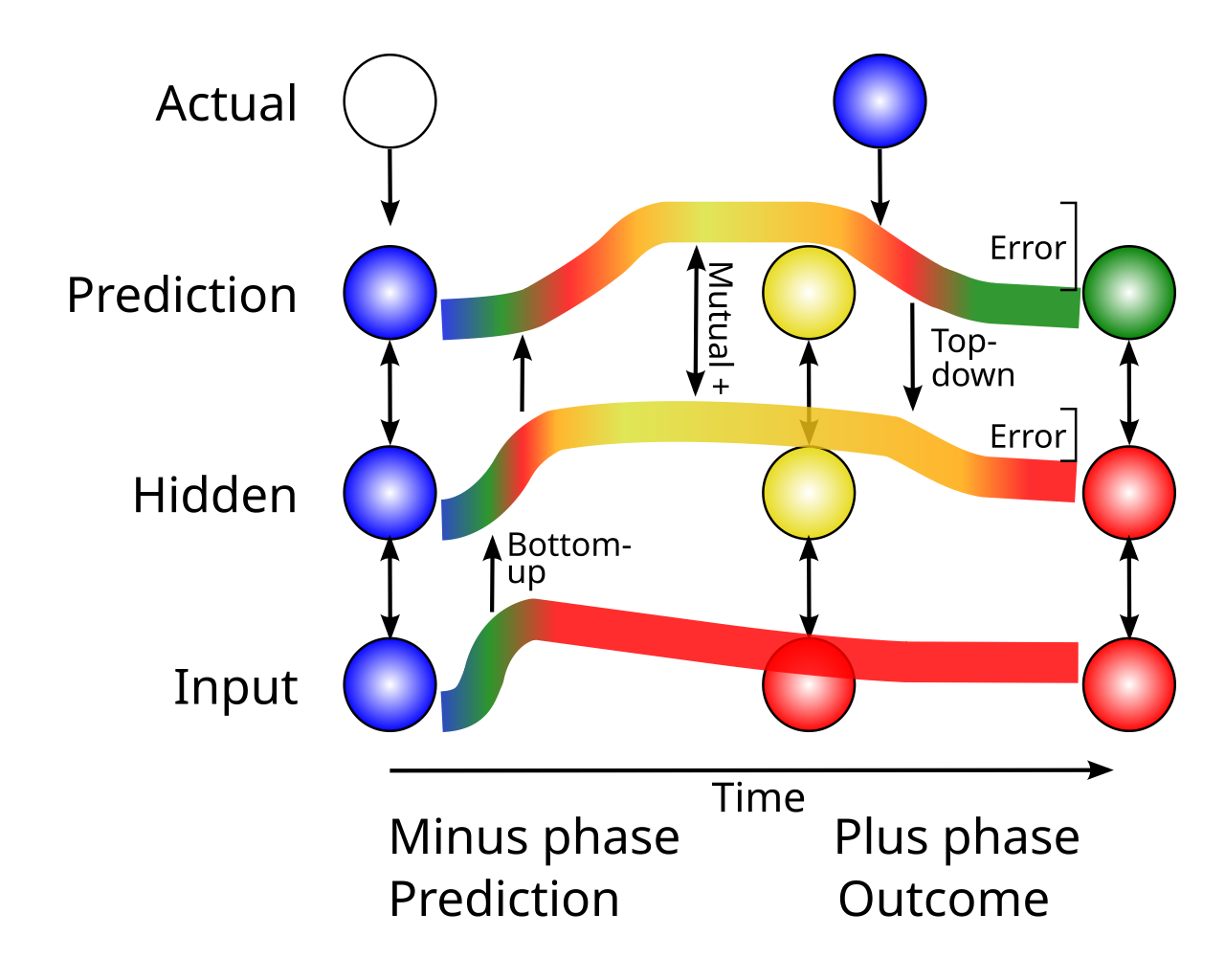
このアルゴリズムは、発火率の観点から勾配を「明示的に」表すために別個のニューロンの集団を必要とするのではなく、時間の経過とともに出現する 2 つの異なる活性化状態 ([[#figure_bidir-err]]) の間の時間導関数 (差分) として逆伝播された誤差勾配を「暗黙的に」表現することに基づいています。誤差勾配を計算するために神経活動の 2 つの異なる状態または「位相」を使用するというアイデアは、Boltzmann Machine ([[@AckleyHintonSejnowski85]]) に由来し、誤差逆伝播形式からの直接の派生は、GeneRec (Generalized Recirculation) アルゴリズム ([[@OReilly96]]) によって最初に提供されました。これは、元の Recirculation モデルを一般化したものです。 [[@^HintonMcClelland88]]。その後、他の派生型も開発されました ([[@XieSeung03]]; [[@ScellierBengio17]])。
このアルゴリズムは、誤差勾配を 2 つの活性化状態の差として暗黙的に表すことにより、フィードフォワード活動と逆伝播誤差信号をコーディングする 2 つの異なるニューロン集団を維持するために必要な大幅な追加の複雑性を回避し、3 番目の異なる集団がそれらの差を表します。代わりに、この時間微分フレームワークの下では、新皮質のすべてのニューロンは常に、新皮質の十分に確立された比較的ユニークな特性である双方向の興奮性接続を通じて、現在の状態の正の相互互換性のある表現をエンコードしています ([[@MarkovErcsey-RavaszLamyEtAl13]]; [[@VanEssenMaunsell83]])。 1 つのフェーズでは、この現在の状態は 予測を反映し、その後、以前の予測とは異なる可能性のある 結果が続きます。ネットワーク全体の対応する活性化状態の違いにより、結果と予測の間の誤差勾配が近似されます。
{id=”figure_pulv-conns” style=”高さ:15em”}
![一次視覚野と二次視覚野の場合、新皮質と視床の肺核の間の接続性は、予測エラー主導型学習を推進するのに非常に適しています。第 6 層 (VI) ニューロンからの多数の比較的弱い投射は、骨盤上の予測を活性化するのに適しており、複数の皮質領域およびニューロンからの信号を統合して予測を合成します。これは、学習の過程で新皮質全体で、およびこれらの最終投射で肺骨へ改善されます。対照的に、第 5 層(V)固有バースト(5IB)ニューロンからの強力な焦点ドライバー入力は、本質的に下位皮質層の活動パターンの未学習コピーである結果表現を活性化することができます(たとえば、この場合、V1 は V2 予測を訓練します)。 5IB ニューロンの周期的なバーストにより、この結果アクティビティは一時的にのみ存在し (つまり、プラス フェーズ)、完全な予測、つまり結果学習サイクルがおよそ 200 ms (つまり、シータ周波数、5 Hz) 以内に発生することが保証されます。 [[@^ShermanGuillery06]] に基づく図。](https://raw.githubusercontent.com/compcogneuro/web/main/content/media/fig_pulvinar_connectivity.png)
新皮質の視床皮質の接続は、全体的な 予測学習 フレームワーク内で、これら 2 つの状態の生成を直接サポートします。これは、今起こったこと ([[@OReillyRussinZolfagharEtAl21]]) に基づいて次に何が起こるかを予測することを学習します。具体的には、視床の高次の pulvinar 核と mediodorsal 核にある視床中継細胞 (TRC) は、2 つの異なる入力 ([[#figure_pulv-conns]]; [[@ShermanGuillery06]]; [[@UsreySherman18]]) を受け取ります。
-
広範囲の高レベル新皮質脳領域から、より遠位の樹状突起への多数の通常強度の入力。
-
階層的に下位の新皮質領域の第 5b 層固有バースト (5IB) ニューロンから発生する、はるかに少数の (1 つだけでも) 異常に強いドライバー入力。
この一連の特性は、最初の経路によってもっぱら駆動される予測状態と、ドライバー入力の強い影響を反映する結果状態との間の位相的交互を作成します。これは、100 ~ 200 ミリ秒ごとに (つまり、アルファまたはシータ リズムで) 位相的にのみ発生します。
TRC は、通常強度の予測生成入力を大量に送信する領域に広範な興奮性相互投影を送り返し、それによって予測状態と結果状態の間の時間的差異を新皮質に送り返します。さらに、新皮質内の双方向接続により、他の領域からの神経活動の送信に関連するこれらのエラー信号の偏導関数が効果的に計算され、それによって重大なエラー逆伝播_クレジット割り当て_学習プロセス ([[@OReilly96]]) が達成されます。
[[@^OReillyRussinZolfagharEtAl21]] でレビューされているように、この全体的な枠組みと一致する詳細な神経科学データが豊富にあります。
実装
神経生物学的な詳細レベルを下げると、予測状態と結果状態の間の時間導関数のアルゴリズム特性が実際にすべての新皮質シナプスと視床シナプスで局所的にシナプス可塑性を実際に駆動できるのでしょうか?数学的には、時間微分は、共通の駆動入力信号の fast 積分から slow 積分を引いたものの差として計算できます。直観的には、高速積分はより最近の結果状態をより厳密に反映しますが、低速積分は以前の予測状態からの痕跡をより多く保持します。この原則の対話型デモンストレーションについては、compcogneuro.org の [[temporal derivative]] を参照してください。
神経化学的には、LTP (長期増強、すなわちシナプス重量増加) と LTD (長期抑圧、体重減少) の違いは、部分的には 2 つの異なるキナーゼ、CaMKII (カルシウムカルモジュリンキナーゼ II) と DAPK1 (死関連プロテインキナーゼ 1) 間の競合によって決まります。どちらもカルシウム活性化カルモジュリンによって駆動されます。 (CaM) ([[@GoodellZaegelCoultrapEtAl17]]; [[@GoodellTullisBayer21]]; [[@CookBuonaratiCoultrapEtAl21]]; [[@TullisBayer23]]; [[@BayerGiese25]])。 CaMKII の方が一般的な CaM ドライバーの全体的な統合が速く、DAPK1 の統合が遅い場合、これは必要な時間微分メカニズムを実装することになります。
驚くべきことに、現在、この予測と一致する直接的な実験証拠が得られています ([[@JangFloresOReillyEtAl26]])。具体的には、in vitro スライスにおける標準的な CA1 シナプス可塑性標本のシナプス前ニューロンとシナプス後ニューロンは、最初の 100 ms の 1 つの活動レベル (つまり、予測状態を反映する) と、次の 100 ms の別の活動レベル (結果の状態) を持つ、200 ms シータサイクル ウィンドウにわたる活動の異なる時間的パターンによって駆動されました。
{id=”figure_results” style=”高さ:35em”}
![[[@^JangFloresOReillyEtAl26]] からの結果。これは時間微分学習メカニズムの予測と一致します。 a) 200 ms シータ サイクルの 2 つの 100 ms の半分 (予測、結果) にわたって、シナプス前およびシナプス後ニューロンを 25 Hz または 50 Hz で刺激しました。 b) 予測と結果の頻度の 2x2 の組み合わせの 4 つのセルすべてがテストされました。 c) 時間 0 での刺激プロトコル周囲のプローブ EPSP 振幅の進行。時間微分値の増加 (シナプス前ニューロンとシナプス後ニューロンの両方で 25 ~ 50 Hz、オレンジ色) が LTP をもたらし、時間微分値の減少 (50 Hz から 25 Hz、青色) が LTD をもたらしたことを示しています。両方のフラット プロファイル (一定の 25 Hz または 50 Hz) では、正味のシナプス効率の変化はありませんでした。 d) さまざまな時点での増加および減少条件の要約データ。統計的に有意な結果は星印で強調表示されます (** = P < .01、*** = P < .001)。 e) 2 つのフラット条件の概要データ。](https://raw.githubusercontent.com/compcogneuro/web/main/content/media/fig_ltp_jang_etal_stim_results.png)
これらの異なる時間パターンを 10 回繰り返し提示した後、ベースラインのシナプス有効性強度から得られた変化は、時間微分学習メカニズム ([[#figure_results]]) の予測と一致しました。具体的には、予測と結果の間に上昇パターンがある場合 (25 Hz から 50 Hz)、LTP が発生しました。このパターンが逆方向(50 Hz から 25 Hz)に進むと、LTD が発生しました。最後に、そして重要なことに、両方の安定条件 (25 Hz から 25 Hz および 50 Hz から 5 Hz) では、正味のシナプス効率の変化は発生しませんでした。この後者の条件は、シナプス可塑性に関する標準的なヘビアン型の説明と直接矛盾します。50-50 の場合は全体的なシナプス活動が最も多いにもかかわらず、LTP を引き起こさなかったのに対し、25-50 の場合はそうなったからです。さらに、25 対 50 の場合と 50 対 25 の場合は両方とも、シナプス活動の正味量は同じですが、時間の経過とともに構成が異なるだけです。
### まとめ
したがって、この要約評価から得られる強力な結論は、エラー駆動型の予測学習の時間微分形式は、関連する 3 つの分析レベルすべてにわたって、新皮質の学習方法について一貫した経験的に裏付けられた説明を提供するという点で独特であるということです。さらに、この理論は、compcogneuro.org で詳しく説明されている [[Axon]] フレームワークの大規模スパイキング ニューラル ネットワークに実装されています。この Web サイトでは、GPU ベースのアクセラレーションのための WebGPU フレームワークを使用して、Web ブラウザーを通じて実行できるこれらのモデルの例を多数提供して、適切なパフォーマンスを提供します。詳細については、[[kinase algorithm]] を参照してください。
代替フレームワーク
関連する区別を明確にするために、他の可能な学習アルゴリズムとのさまざまな対照点について以下で簡単に説明します。
明示的エラーと予測コーディング
誤差逆伝播アルゴリズム ([[@LillicrapSantoroMarrisEtAl20]]) と古典的なベイジアン予測コーディング フレームワーク (例: [[@RaoBallard99]]; [[@Friston09]]) を実装するためのさまざまな代替提案は、両方とも、ボトムアップの実際の結果からトップダウンの予測を差し引くことによって、ニューロンの部分集団が「誤差」を直接表すと仮説を立てています。したがって、異なるニューロン集団が基本的に異なる情報を表現できるように、何らかの方法で分離する必要があります。さらに、これら 3 つの異なる信号 (予測、結果、エラー) はすべて、原理的には層を越えて異なる方向に伝達される必要があり、強力に分離された経路が必要です。
対照的に、上記で強調したように、時間微分フレームワークは、時間の経過に伴う活動状態の差として誤差勾配表現 implicit を保持するため、必要な生物学的実装が大幅に簡素化されます。さらに、ネットワーク内のすべてのレベルが連携して、トップダウンとボトムアップの制約を統合して並列の制約満足処理を推進し、現在の状態の一貫した解釈を推進することができます ([[@HopfieldTank85]]; [[@OReillyWyatteHerdEtAl13]])。これは、表現空間を介した [[search]] の強力な形式を表し、シナプス重み空間を介した誤差逆伝播検索の外側ループ内の一種の内側ループ最適化として動作し、システムの予測精度を向上させます。
利用可能な神経証拠は、皮質のすべてのレベルにわたる情報の一貫性、相乗的、冗長エンコーディングと一致しており、明示的なエラー モデルで必要とされる種類の構造的分離に関する重要な証拠はありません ([[@WalshMcGovernClarkEtAl20]]; [[@HeilbronChait18]])。発見された主要な肯定的な証拠、つまり予期せぬ結果に対する期待される結果に対する神経活動の抑制は、十分に確立された神経適応/順応メカニズムと組み合わせた代替時間微分モデルと互換性があります ([[@KokLange15]]; 詳細な議論については [[@OReillyRussinZolfagharEtAl21]] を参照)。
したがって、時間微分フレームワークは、新皮質が、複数のレベルの分析で利用可能な神経証拠とより互換性があると思われる方法で、次に何が起こるかについてトップダウンの予測を生成することによって学習するという広く受け入れられている考えをサポートしています。
ヘビアン学習
文献における新皮質学習の主な計算レベルの解釈は一般に、NMDA受容体を介して入るシナプス後カルシウムのレベルとシナプス可塑性の方向と大きさとの関係を示す十分に確立されたデータに基づいて、さまざまな形のヘビアン学習に焦点を当ててきた([[@Lisman89]]; [[@BearMalenka94]])。具体的には、カルシウムのレベルが低いとLTDが発生し、カルシウムのレベルが高いとLTPが発生します。これは一般に、ヘビアン学習アルゴリズムの BCM ([[@BienenstockCooperMunro82]]) バージョンと一致しています。
実装レベルでは一見利点があるように見えますが、ヘビアン学習は、共活性化の統計的規則性を抽出するという点で局所的なヒューリスティック関数しか持たないため、計算レベルでは本質的には役に立ちません ([[@Oja82]]; [[@RumelhartZipser85]]; [[@IntratorCooper92]])。したがって、ヘビアン学習が新皮質に存在するような深層ネットワークを効果的に訓練できると信じる理由はありませんが、これはまさに誤差逆伝播が優れている場合です。
最近では、スパイクタイミング依存可塑性 (STDP) ([[@BiPoo98]]) が計算モデルの主な焦点となっています (例: [[@KheradpishehGanjtabeshThorpeEtAl18]]、[[@DiehlCook15]])。しかし、最初に説明された STDP の単純な計算強制形式は、1 秒間隔で分離された個々のスパイクのペアによる非常に特殊な刺激プロトコルを必要とし、一般に、より現実的な神経活動パターンには適用できないことが明らかになりました ([[@DebanneInglebert23]])。実際、同じ BCM のようなパターンが、より現実的で密度の高いアクティビティ パターンで現れます ([[@ShouvalWangWittenberg10]])。したがって、STDP には、実装レベルのサポートと、STDP が強力な学習メカニズムである理由についての一貫した計算レベルの説明の両方が欠けています。
## 結論
ここで示されている視点は必然的に著者の意見を反映していますが、おそらく、関連する 3 つの分析レベルすべてにわたって競合する可能性のある対案を刺激するのに役立つ可能性があります。最も強力な制約は計算レベルから来ているように見え、効果的にフィールドを 1 つの計算レベル関数、つまり誤差逆伝播に絞り込みます。もし誰かがエラーバックプロパゲーションよりもさらに一般的に強力なものを発見したとしたら、それは確かに多くの分野にわたって重要な進歩を意味するでしょうが、計算レベルでのアルゴリズムの探索に膨大な量の研究が投資されてきたことを考えると、その可能性はますます低くなりそうです。
これにより、上で概説したアルゴリズムおよび実装レベルの議論により多くの責任が課せられますが、それぞれの議論は現在、それらを裏付ける重要な経験的証拠を持っています。それにもかかわらず、予測エラー駆動型学習を達成するために進められているさまざまなアルゴリズムと実装の可能性をさらにテストするには、より多くの実証的研究が不可欠です。