compcogneuro/web: predictive-learning
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/predictive-learning.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Learning”, “Neuroscience”, “Computation”] bibfile = “ccnlab.json” +++ 予測学習は、エラー信号が予測エラー、つまり次に何が起こるかを予測する能力のエラーから派生する [[error-driven learning]] の形式を指します。この形式の学習は、長年にわたって多くの研究者によってさまざまな形で研究されており、Chat GPT および関連モデルを強化する現世代の [[large language models]] (LLM) における学習の主な原動力となっています。これらのモデルの驚くべき機能は、この形式の学習の重要な利点を示しています。学習は単に次に何が起こるかを予測することによって推進されるため、ラベル付けされていない生のデータを処理します。
LLM のコンテキストでは、これはテキスト ストリーム内で次に出現する単語を予測することを意味します。これらのモデルの優れた能力は、インターネットからかき集めた膨大な量の文書コレクションから学習する能力に直接由来しており、これは予測学習の使用によってのみ可能になります。対照的に、以前のエラー駆動学習モデルでは、標準の [[error backpropagation]] モデルで学習を促進する教師ありターゲット信号を提供するには、人間がラベル付けしたデータセット (たとえば、画像ごとに人間が生成したカテゴリ ラベルを持つ イメージネット データセット) が必要でした。これらのラベルの生成には労力がかかるため (煩わしい reCAPTCHA 画像ラベル付けプロンプトの形でユーザーから盗まれた場合でも)、LLM が使用できるラベルのない生の大量のテキストに比べて、これらのデータセットのサイズが制限されます。
同じ原理が脳にも当てはまります。次に何が起こるかを予測しようとするだけで、私たちは世界について膨大な量を学ぶことができます。動く前の幼児の一見受動的な視線は、彼らの周囲の世界に存在するすべての「構造」を吸収するにつれて、彼らの脳で起こっている大量の予測学習を裏切ります。
予測学習の本質的な制約は、環境が何らかの形で予測可能でなければならないということです。これが「構造」の意味するところです。つまり、私たちの世界では物事は完全にランダムではありません (ただし、そのように感じることもあります)。たとえば、物理法則は、少なくとも巨視的なレベルでは決定論的であり、オブジェクトが予測可能な方法で動作する原因となります。生きている物体 (動物、特に他の人間) は予測可能性がはるかに低いですが、それでも私たちの脳は、少なくともある程度予測可能な方法で私たちを行動させます。さまざまな状況で他の人がどのように行動するかを発見することは、私たちが学習に時間を費やすことの大きな部分を占めています。
LLM は、人間の言語が人間の大量の知識を捕捉する深い構造を持っていることを実証します。実際、これらのモデルのほとんどのユーザーがおそらく評価していない大きな成果の 1 つは、明示的な指示や重要な生来の知識がなくても、人間の言語は高いレベルの能力まで学習できることを合理的な疑いを超えて実証したことです ([[@Piantadosi23]])。これにより、ノーム・チョムスキーの初期の著作([[@Chomsky65]])に遡る、言語学習における「刺激の貧困」に関する長い議論に終止符が打たれることになる。この議論は、私たちの言語学習能力の根底にある先天的普遍文法に関する彼の理論の動機付けとなった(筋金入りのチョムスキー理論家たちはそのような議論(例えば、[[@LanChemlaKatzir24]])をかわそうとしているが、彼らは、次のような問題に直面して負け戦を戦っているようだ) LLM のパフォーマンスは常に向上しています)。
予測学習の生物学的メカニズム
予測学習を介して環境から豊富な知識を抽出できるというこれらの「生態学的」議論を超えて、脳が予測エラー駆動学習を実行するように特別に構造化されているというかなりの証拠と長年の理論化があります ([[@Helmholtz67]]; [[@Elman90]]; [[@ElmanBatesKarmiloff-SmithEtAl96]]; [[@Mumford92]]; [[@KawatoHayakawaInui93]]; [[@DayanHintonNealEtAl95]]; [[@Friston05]]; [[@Clark13]];これらの提案のほとんどは、予測誤差の何らかの「明示的」表現を含み、多くの場合、ボトムアップの感覚信号と、より高いレベルの内部表現から生成されたトップダウンの予測を比較する計算が含まれます。
{id=”figure_minus-plus-pulvinar” style=”高さ:20em”}
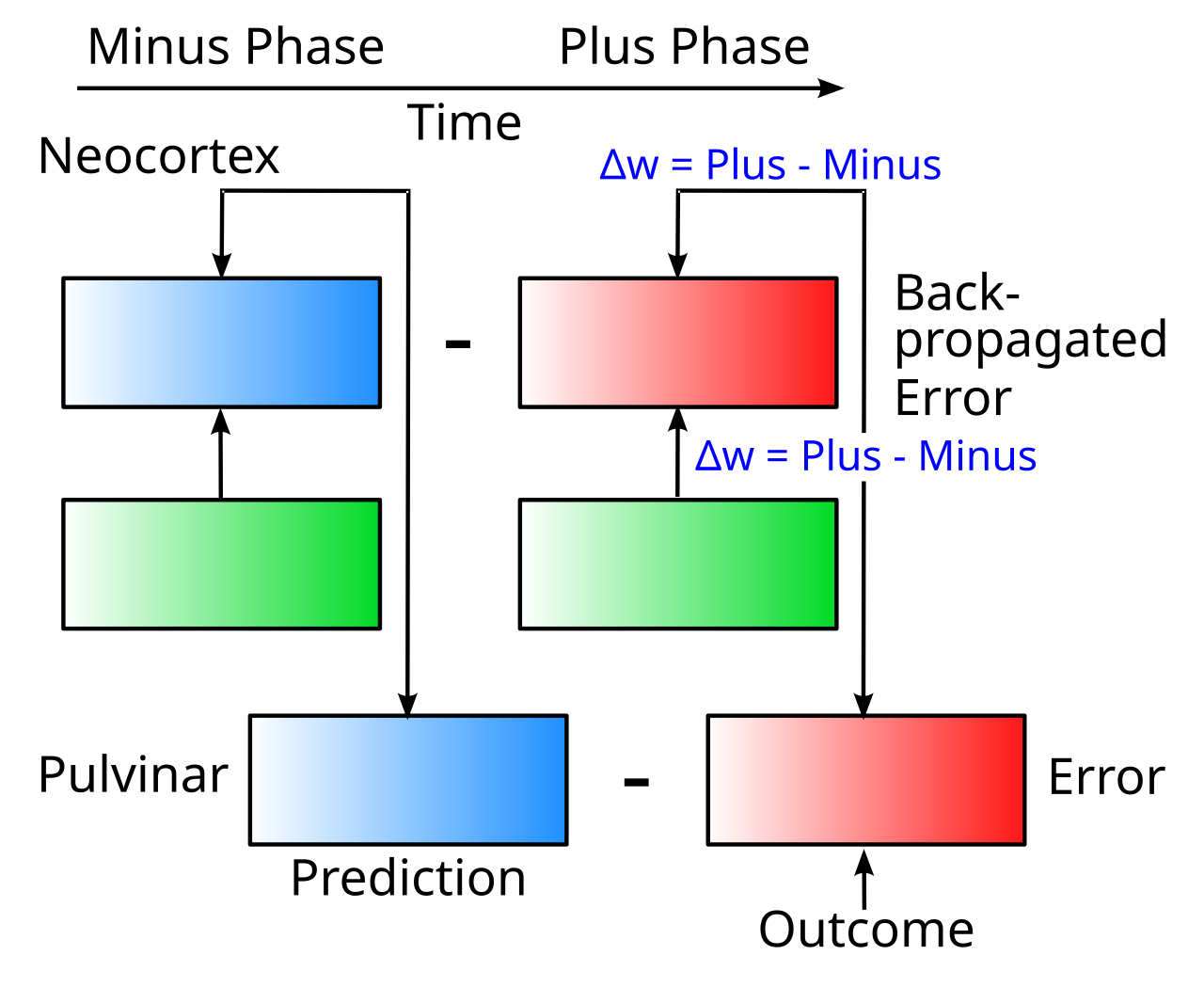
時間の経過に伴う活動状態の変化として、エラーをより「暗黙的に」表現するための [[temporal derivative]] メカニズムは、視床の髄核を含む特定の神経メカニズムのセットと一致しています。粉体は、初期の prediction アクティビティ状態とそれに続く outcome アクティビティ状態を表します ([[#figure_minus-plus-pulvinar]]; [[temporal derivative]] の [[temporal derivative#figure_minus-plus]] と比較してください。粉体は事実上、標準的な 3 層ネットワークの出力層です)。
{id=”figure_prjn-screen” style=”高さ:20em”}
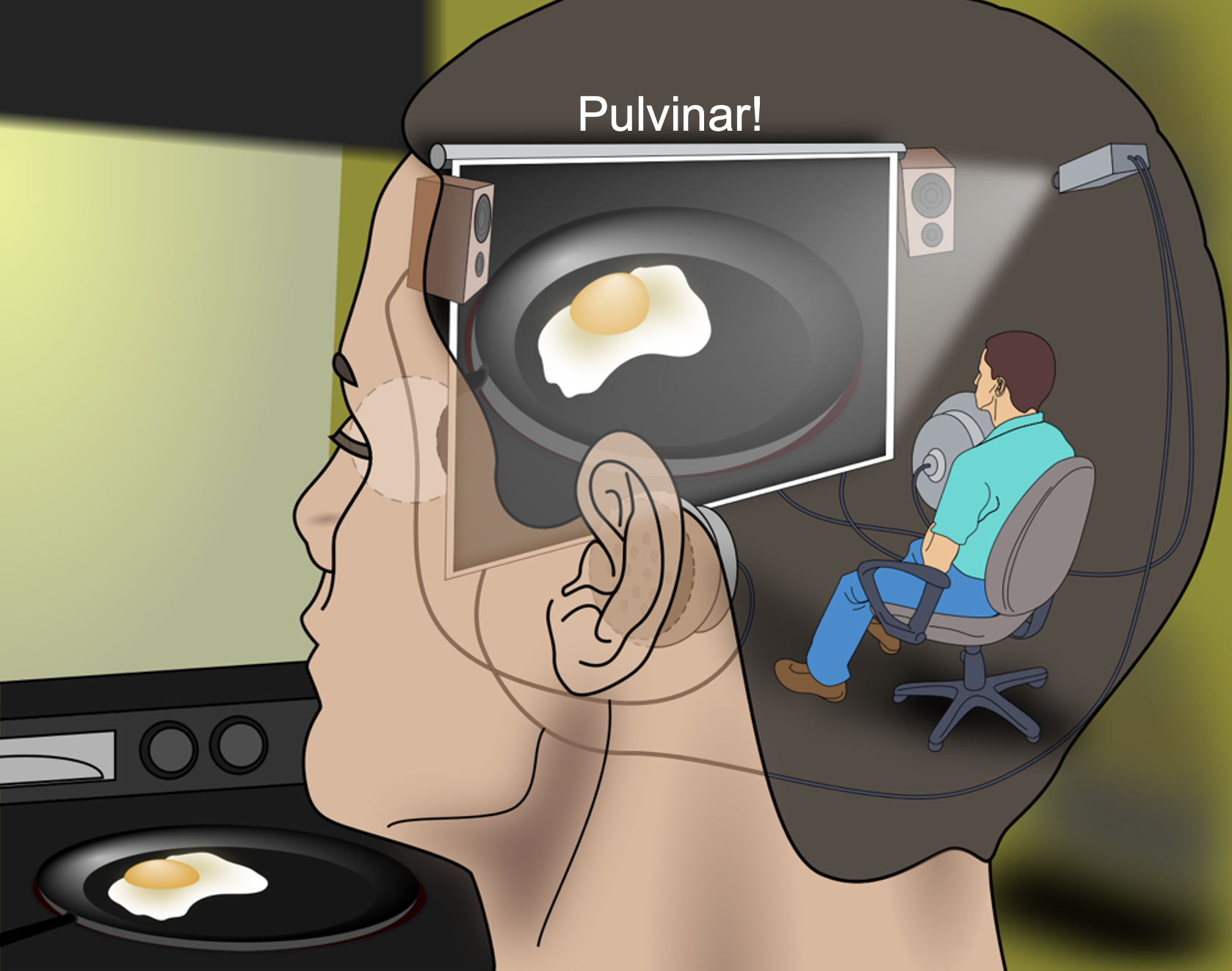
肺床のこの機能は、かなりの神経生物学的データや、新皮質との広範な相互接続性を強調した初期の理論的枠組みと一致しており、脳床が_黒板_ ([[@Mumford91]]) または_投影スクリーン_ ([[#figure_prjn-screen]]) のように機能することを可能にしています。
{id=”figure_pulv-conns” style=”高さ:15em”}
![一次視覚野と二次視覚野の場合、新皮質と視床の肺核の間の接続性は、予測エラー主導型学習を推進するのに非常に適しています。第 6 層 (VI) ニューロンからの多数の比較的弱い投射は、骨盤上の予測を活性化するのに適しており、複数の皮質領域およびニューロンからの信号を統合して予測を合成します。これは、学習の過程で新皮質全体で、およびこれらの最終投射で肺骨へ改善されます。対照的に、第 5 層(V)固有バースト(5IB)ニューロンからの強力な焦点ドライバー入力は、本質的に下位皮質層の活動パターンの未学習コピーである結果表現を活性化することができます(たとえば、この場合、V1 は V2 予測を訓練します)。 5IB ニューロンの周期的なバーストにより、この結果アクティビティは一時的にのみ存在し (つまり、プラス フェーズ)、完全な予測、つまり結果学習サイクルがおよそ 200 ms (つまり、シータ周波数、5 Hz) 以内に発生することが保証されます。 [[@^ShermanGuillery06]] に基づく図。](https://raw.githubusercontent.com/compcogneuro/web/main/content/media/fig_pulvinar_connectivity.png)
特に、[[#figure_pulv-conns]] に示されているように、新皮質と肺髄を含む視床皮質ネットワークには、予測学習でこの役割を果たすのに非常に適した 2 つの重要な特性があります ([[@OReillyRussinZolfagharEtAl21]])。
-
[[neocortex]] の 2 つの異なる層にある細胞から 2 つの異なる投影を受け取ります。これらはまったく異なる特性を持ち、(a) 新皮質によって生成された予測を別々に伝達するのに適しています。 (b) 実際に起こったことの結果。この予測は、第 6 層 (VI) のニューロンからの非常に高密度 (多数)、広範囲に収束 (複数の異なる新皮質領域から生じる)、個別に弱い接続を介して到着します。これらの接続により、複数の多様な入力を使用して予測が合成され、新皮質全体および肺骨への最終投影における予測誤差主導の学習を介して時間の経過とともに改善されます。一方、結果は、大脳新皮質の最も特殊なタイプのニューロンである第 5 層内因性バースト (5IB) ニューロンから生じる、非常にまばら (少数、多くの場合は 1 つだけ) の強力で集中的な投影を介して届きます。これらの_ドライバー_入力 ([[@ShermanGuillery06]]) は学習する必要はなく、本質的にソース層に存在する情報の_コピー_を提供するだけです (たとえば、図の V1 感覚表現)。
-
5IB ニューロンは、その名前の通り、活動の一時的なバーストでのみ発火し、それ以外の場合は一定期間沈黙します。この沈黙は、強い運転入力の結果バーストを受け取る前に、予測経路がマイナスフェーズで予測を生成する絶好の機会を提供します。
これらの重要な特性の収束は、[[@^OReillyRussinZolfagharEtAl21]] でレビューされた他の大量の一貫したデータとともに、予測学習におけるこの回路の仮説的な役割と著しく一致しています。
さらに注目すべき特性の 1 つは、肺床における予測を駆動すると仮定されている第 6CT 層 (皮質視床) ニューロンが、進行中の感覚入力 ([[@HarrisShepherd15]]; [[@SakataHarris09]]; [[@Thomson10]]) に比べて遅延した発火パターンを示すことが知られていることであり、これは予測学習のコンテキストにおけるすべての全体的なタイミングにとって重要です。具体的には、この遅延発火特性により、システムは「t-1」以前の状態を使用して、本質的に「今何が起こっているのか」を予測できるようになります。これにより、皮質内のほとんどすべてが現在の瞬間 (「t」、または少なくとも特定の神経処理遅延にできるだけ近い値) を表現できるようになりますが、t-1 で利用可能な「古い」情報のみを使用してこの現在の状態を予測する方法を学習することもできます。
5IB ニューロンの固有バースト周波数が 10 Hz (つまり、100 ミリ秒ごと、アルファ リズムとも呼ばれる) であるとすると、最小予測時間ウィンドウは約 100 ミリ秒です。実際、多数の知覚効果や錯覚があり、それらはすべて 100 ms / 10 Hz のこの重要な時間窓の周りに収束します (例: [[@BuffaloFriesLandmanEtAl11]]; [[@VanRullenKoch03]]; [[@MathewsonGrattonFabianiEtAl09]]; [[@JensenBonnefondVanRullen12]]; [[@ClaytonYeungKadosh18]])。
5IB ニューロンからのこの相的バーストは、肺床上の結果活動と第 6CT 層ニューロンの更新の両方を駆動すると仮説が立てられ、その後、これらのニューロンは持続的な残留コンダクタンスを受け取ります。このコンダクタンスは、5IB バースト入力の結果として大きな NMDA 駆動コンダクタンスを表すと我々は仮説を立てています。 5IB ニューロンは次のアルファ サイクルまで再びバーストしないため、これにより 6CT ニューロンが追加の入力から効果的に遮断され、t-1 前の状態情報を表現できるようになります。
{id=”figure_deep-time-v1v2” style=”高さ:20em”}
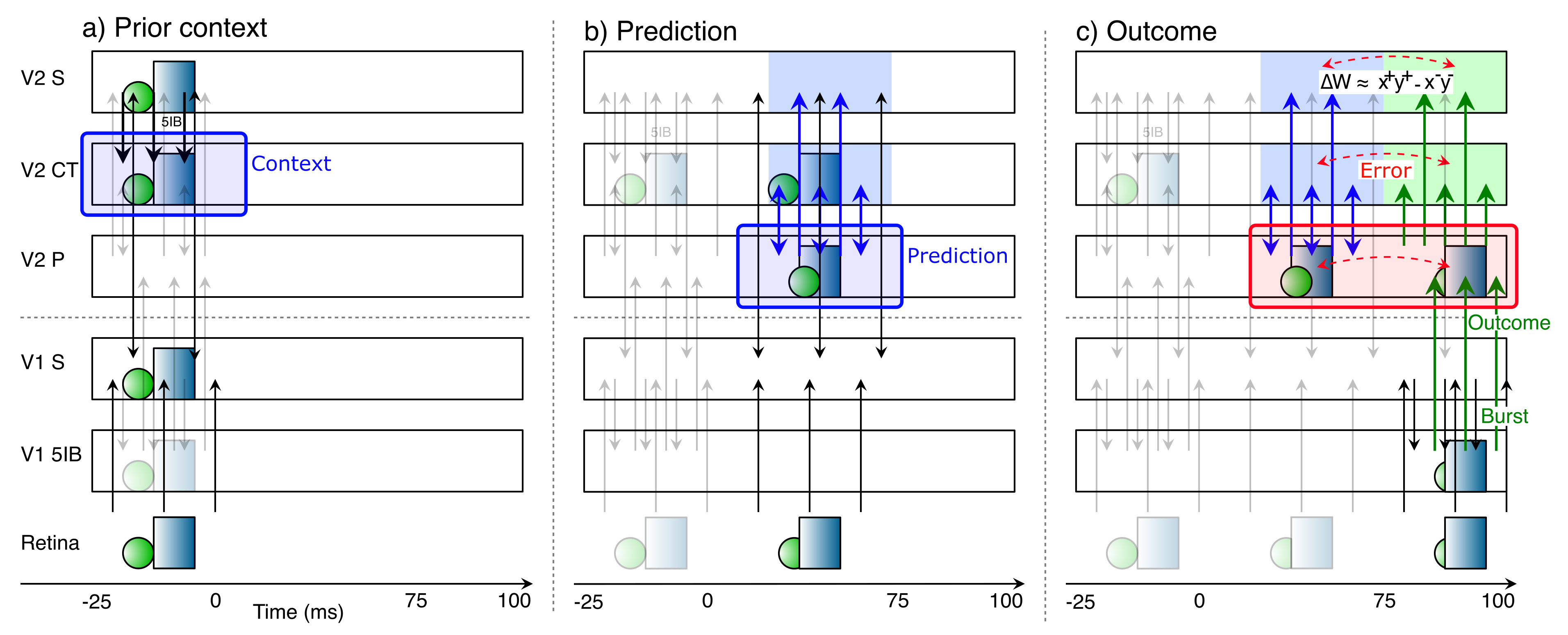
[[#figure_deep-time-v1v2]] は、[[#figure_pulv-conns]] に示されている V1 - V2 回路が、予測学習の 1 サイクルの過程でこのアルファ リズム時間枠にわたってどのように進化するかの概略図を示しています。
[[@^OReillyRussinZolfagharEtAl21]] では、視覚システムでの予測学習が空間を転がる 3D オブジェクトのショート ムービーからどのように構造を抽出できるかを示す多くの詳細と実装モデルを提供します。[[deep vision simulation]] を参照してください。
有限状態オートマトン (FSA) に基づいて確率的に生成されたシーケンスの予測学習のより単純なモデルについては、[[FSA simulation]] を参照してください。このモデルは、学習の研究に長年使用されてきました ([[@Reber67]]; [[@CleeremansMcClelland91]])。このモデルは、予測学習に関与する重要な計算メカニズムを理解するためのシンプルかつ具体的な方法を提供します。
モーター制御のコンテキストでは、予測学習は、時間の順方向の矢印に沿って、特定のコンテキスト ([[@JordanRumelhart92]]) で特定のアクションを実行した場合に何が起こるかを予測する「順方向モデル」を学習します。これは [[Rubicon]] モデルの中心的なコンポーネントであり、より一般的には [[reinforcement learning]] で一般的に使用されます。
## 実装
関与する主要な新皮質要素は深層層 (第 5 層と第 6 層) に位置するため、この予測学習メカニズムを「深層予測学習」と呼びます (アルゴリズムのコンテキストでは以前は深層 [[Leabra]] でした)。これは、環境から深層構造も抽出することが期待されます。
Axon での実装では、層 6CT ニューロンに特化した層タイプが追加され、以前の t-1 時間コンテキストを保持できるようになり、肺髄ニューロン用の層タイプが追加されて、層 5IB ニューロンからのドライバー入力の効果をシミュレートできます。当分の間、層 5IB ニューロン自体の明示的な実装は必要ありません。これは、外部の感覚イベントによるアルファ リズムの柔軟な同調を捕捉できないという代償を払って、単純化された理想化された方法でニューロンの動作をより簡単にシミュレートできるためです。生物物理学的に現実的な 5IB 層を追加することは将来の研究の重要な目標であり、そのためにはより複雑な神経力学が必要になることがあらゆる兆候で示されています (例: [[@BeniaguevSegevLondon21]])。
6CT ニューロンと経路
層 6CT ニューロンは、プラスフェーズの終わりにのみアクティブ化される投影から context 入力コンダクタンスを受け取り、この時点で 5IB バースト入力を反映します。これは CtxtGe 変数に保存され、通常はその後の試行の過程で減衰します。
一方、6CT ニューロンは、予測を投影している骨盤層からの相互入力も受け取り、現在の状態情報によって「汚染」されない持続的な興奮性コンダクタンスも提供します。
歯髄ニューロンと神経経路
Pulvinar ニューロンには、同じジオメトリを持つ対応するドライバー入力層があり、そこから 1 対 1 のドライバー投影を暗黙的に受け取ります。