compcogneuro/web: principal-components-analysis
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/principal-components-analysis.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Computation”] bibfile = “ccnlab.json” +++ 主成分分析 (PCA) は、一連のデータ (経時的な神経活動のパターンなど) にわたる共分散行列の分散の一次次元を捕捉する新しい基本ベクトルを計算する、広く使用されている次元削減手法です。 2D または 3D プロットで表現できる少数の効率的な基底ベクトルを使用して高次元の状態空間を表現することにより、多くの場合、表現の本質的な構造を理解できます。これらの概念の背後にある数学的詳細と、PCA の数学の基礎となる固有ベクトル/固有値フレームワークについては、[[linear algebra]] を参照してください。
神経表現の分析に PCA を使用する実用性に加えて、[[categorization]] で説明されているように、軸または基底ベクトルの新しい「回転」セットで情報を再表現するこのプロセスは、脳内で情報を表現する基底ベクトルを提供するシナプスの重みを調整する学習メカニズムによって駆動される神経情報処理の重要な機能です。
実際、さまざまな形式の [[Hebbian learning]] が PCA の近似を実行することが示されており、PCA は、ヘビアン学習が達成できることの有用で抽象的で数学的に明確に定義された例を提供します。具体的には、PCA は入力変数間の_相関_に基づいており、ヘビアン学習が入力空間の_相関構造_をどのように有効に抽出できるかを示します。
[[information-theory]] フレーミングでは、分散が大きいほど entropy が大きくなり、information が大きくなることを意味するため、最大分散次元を見つけることは、最も有益な次元を見つけることと同じです。入力内の冗長な相関信号を削除することは、情報をより効率的に表現できるように情報を「圧縮」することと同じです。密接に関連する独立成分分析 (ICA) 手法 ([[@JuttenHerault91]]) は、相互情報量を最小限に抑えるという情報理論の原則から派生したもので、状況によっては PCA ([[@Hyvarinen13]]) よりも有利な点があります。
共分散行列
{id=”figure_iris-petal” style=”高さ:20em”}
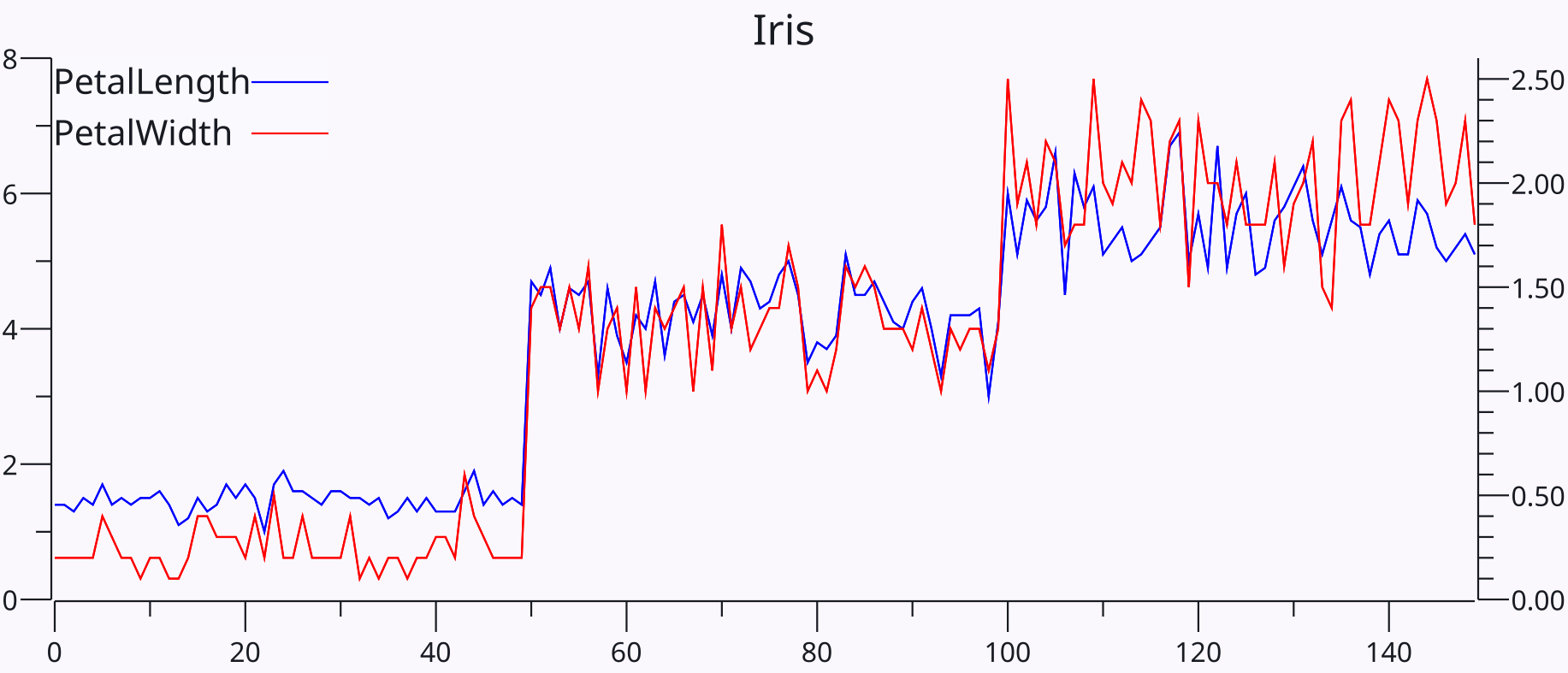
PCA コンポーネントの計算は、データの共分散行列から始まります。この行列は、さまざまな変数 (ニューロンの活動状態など) がデータの行全体でどの程度相互に共変動する (相関する) かを捕捉します。直感的には、2 つの変数が時間の経過とともに同じアクティビティのパターンを示す場合、それらは_冗長_であり、2 つの変数ではなく 1 つの変数だけでキャプチャできます ([[#figure_iris-petal]])。これと同じ原則は、部分的にのみ冗長である複数の変数にわたる中心傾向を捉えることによって、「ソフト」な方法で拡張できます。これが PCA が実現できることです。
{id=”figure_iris-covar” style=”高さ:10em”}

[[#figure_iris-covar]] は、UCI 機械学習標準 アイリスデータセット の共分散行列を示します。 4 つの特徴のうち 3 つは、データセット内の 3 つの異なるアイリスの花種と各種の 50 個の個別サンプルにわたって相互に強く共変動するため、わずか 2 つの主成分でより効率的に表現でき、このデータセット全体にわたる大量の分散を捕捉できます。
PCA 投影
{id=”figure_iris-pca” style=”高さ:20em”}
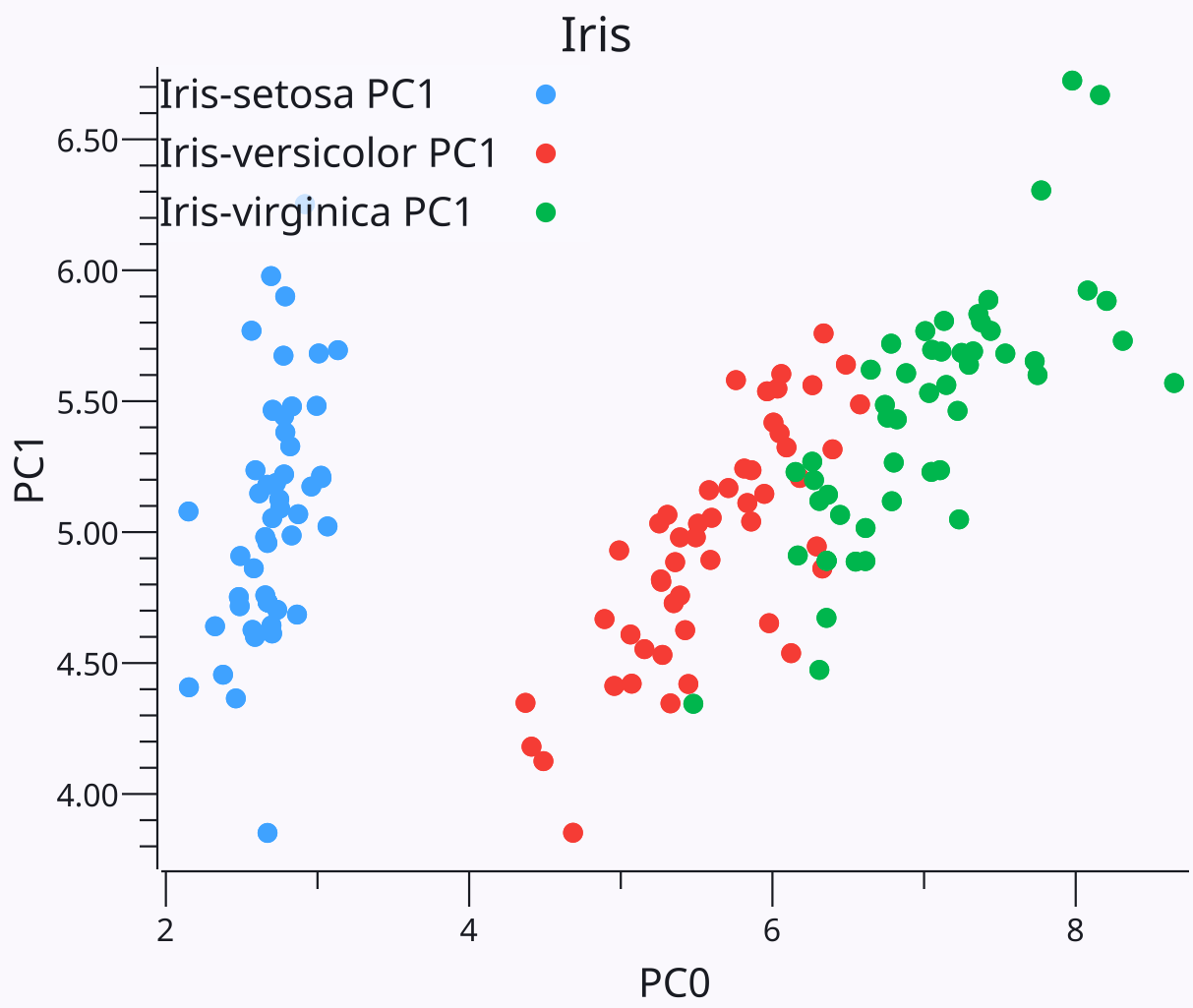
[[#figure_iris-pca]] は、2 つの最も強い主成分に沿った虹彩データの投影を示します。一般に、ポイントが比較的広がっているという性質は、PCA 投影がデータ内の最大分散の次元を捕捉する軸を見つけていることを示しています。 X 軸に沿った最初の主成分はアヤメの異なる種を明確に区別し、Y 軸に沿ってプロットされた 2 番目の主成分は種内の分散を最大化します。