compcogneuro/web: reinforcement-learning
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/reinforcement-learning.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Rubicon”, “Computation”, “Learning”] bibfile = “ccnlab.json” +++ 強化学習 (RL) は、試行錯誤による探索と報酬/罰の信号に基づいて学習する、より抽象的な機械学習および [[abstract neural network]] モデルを表す広く使用されている用語です。 [[Rubicon]] フレームワークは、[[Axon]] モデルのコンテキストで RL レベルの機能の生物学的に詳細な実装を提供します。
{id=”figure_rl-setup” style=”高さ:20em”}
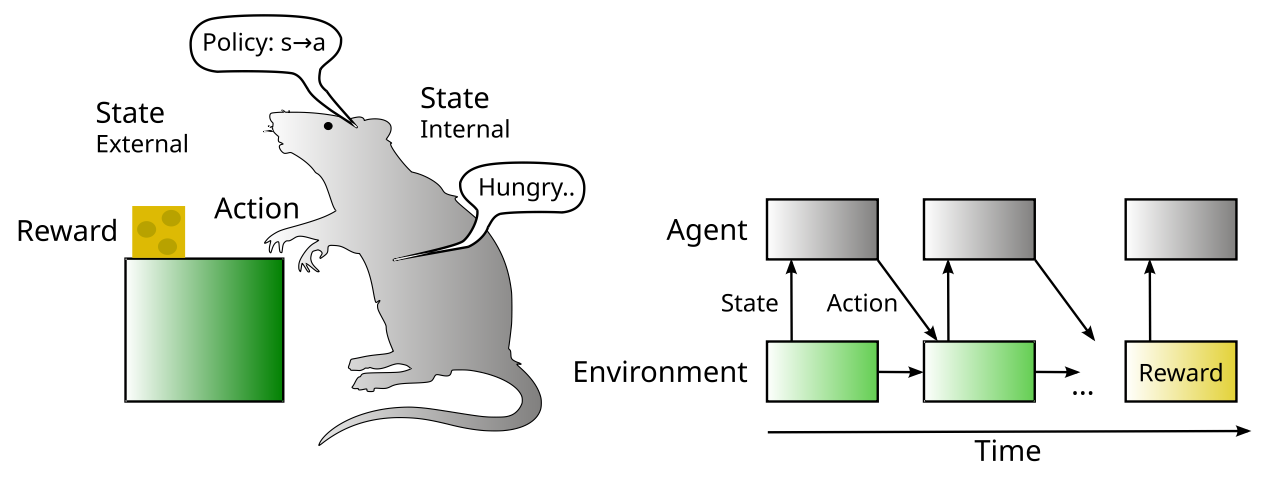
RL モデルの主要な要素は、[[#figure_rl-setup]] に示されています。ラット エージェント のコンテキストでは、環境 で アクション を実行し、特定の 状態 値 (ラットの感覚を介して) を提供し、エージェントのアクションの影響を受けて、独自のダイナミクスの下で時間の経過とともに進化します。環境は報酬 (および罰) も提供します。RL の標準的な目的は、時間の経過とともに報酬の受け取りを最適化する行動を取る方法を学ぶことです。
アクションを選択するための戦略は、連続体 (この連続体は実際には高次元空間です!) に沿った極の観点から考えることができる 2 つの異なるアプローチに分類することができます。
-
[[#Model-free]]: 状態からアクションへの_直接マッピング_であるポリシーを学習します。つまり、刺激 $\rightarrow$ 応答 (S-R) 学習です。
-
[[#Model-based]]: 環境の直接的な感覚経験に加えて、環境の内部_モデル_を使用して、モデル ([[#figure_rl-plan]]) に基づく_計画_に従ってアクションを選択します。
心理学の観点から見ると、これは、「習慣に基づいた」反応と、長年理論化の中心となってきた、より思慮深く検討された反応の基礎との区別であると考えることができます。たとえば、手段的条件付け_の背後にある中心的な考え方であるソーンダイクの_効果の法則 ([[@Thorndike1898]]) では、肯定的な結果につながる行動は確率が増加する(罰の場合はその逆)と考えられています。これは基本的にモデルフリーの RL であり、この脳領域での学習を形成するための [[basal ganglia]] の機能と [[dopamine]] の役割と長い間関連付けられてきました (ただし、おそらく完全に正確ではありません)。
{id=”figure_rl-plan” style=”高さ:20em”}
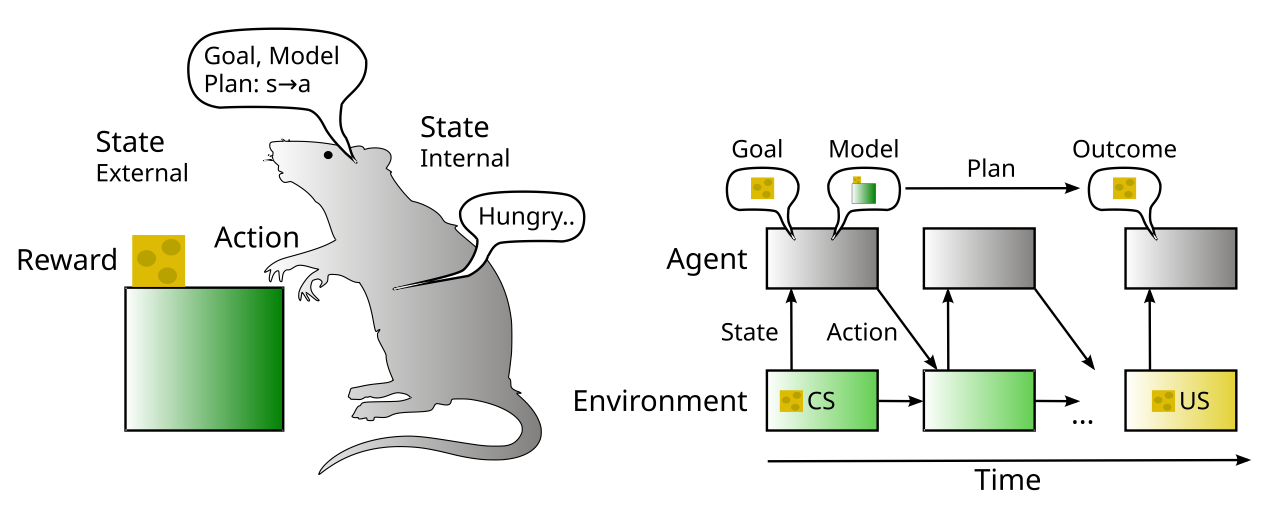
対照的に、「目標主導型」または「制御型」処理 ([[@Tolman48]]; [[@BalleineDickinson98]]; [[@ShiffrinSchneider77]]; [[@CohenDunbarMcClelland90]]; [[@MillerCohen01]]) は、単に刺激と反応に基づいて反応するのではなく、行動の起こり得る結果が実際に評価される、より考慮された処理モードを特徴づけます。勉強中。この処理モードは通常、[[prefrontal cortex]] に依存します。[[prefrontal cortex]] は、事後 [[neocortex]] では通常不可能な方法で (可能なアクションとその結果の) 内部表現を維持および操作する機能を備えています。この区別は、システム 1 (高速) と システム 2 (低速) の観点から [[@^Kahneman11]] によっても一般化されました。
[[@^Doya99]] および [[@^DawNivDayan05]] によって最初に提案されたように、RL モデルフリー概念とモデルベース概念をこれらの生物学的および心理学用語に直接マッピングするには、[[Rubicon]] モデル ([[@OReillyNairRussinEtAl20]]) のコンテキストで遭遇することになる多くの問題があります。それにもかかわらず、概念的には、これらのさまざまな用語はすべて、一般に同様の直観的なアイデアを捉えており、日常の経験という観点から私たち全員がそれを関連付けることができます。
用語的には、[[#figure_rl-plan]] は動物の学習、条件付けに関する文献からの主な用語を示しています。
-
US: 無条件刺激。 これは、価値があるものとして認識するために学習を必要としない、食物や水などの生物学的に特別な 結果 刺激です。米国は RL を駆動する reward スカラー値を生成しますが、この 2 つは同等ではありません。たとえば、お腹が空いていない場合、食事はやりがいを感じられない可能性があります。さらに、別の食べ物を食べても満足できないような、特定の種類の食べ物を渇望している可能性があります (特定の例の特定の味も大きな役割を果たす可能性があります)。ほとんどの RL モデルでは、これらの追加レベルの複雑さは省略されていますが、[[Rubicon]] モデルには、飢餓などの [[emotion drives]] とともに、複数レベルの結果表現を備えたこれらの追加レベルが含まれています。 - CS: 条件付き刺激。 これは、米国との信頼できる予測的関連性を持つ、最初は任意の刺激であり、この刺激の経験がその米国への期待を活性化することができます。環境状態のこれらの要素は強化学習の主な推進力であり、米国を獲得するために必要なアクションを推進します。
モデルフリーのコンテキストでは、CS は S-R 学習における S 刺激です。モデルベースのコンテキストでは、US を取得するための行動を組織化する目標/計画表現をアクティブ化するトリガーになります。 RL フレームワークは、これらの区別の正確な定義と方程式を提供します。これについては、次のセクションで要約します。興味深いことに、モデルベースの RL は原理的にはモデルフリーよりも強力であるはずですが、複雑さが増すため、実際に利点を実証するのは実際にはかなり困難になっており、最先端のモデルの多くはモデルフリーのスペクトルの終端 ([[@MoerlandBroekensJonker21]]; [[@PlaatKostersPreuss23]]) にはるかに近づいています。この理由については最初に次のセクションで説明し、その後でさらに詳しく説明します。
次元の呪い
| 試行錯誤の学習プロセスでは、結果として報酬を獲得するために、必然的に一連の段階的な一連のアクションが必要になります。このプロセスのシリアルな性質により、[[curse of dimensionality]] の影響を特に強く受けます。実行可能なアクションが増え、状態空間の複雑さが増大するにつれて、空間全体のサイズが指数関数的に爆発的に増大し、一人の個人が自分の生涯でこの空間の多くを探索することはすぐに不可能になります。基本的に、この問題を解決する方法は [[bias-variance tradeoff | no “free lunch”]] です。問題に対する適切な解決策を見つけると、最終的には組み合わせ的に巨大な空間を介して [[search]] の形式に帰着します。 |
この問題に対処するには、基本的な方法が 2 つあります。
-
スペースのサイズを削減する これは本質的に、シンボリック AI モデルと多くの現在の RL モデルがとる戦略であり、全体的な検索スペースが制限される可能性があるチェスやビデオ ゲームなどのゲームに焦点を当て、多くの場合、問題に関するドメイン固有の重要な知識 (個々のエージェントの学習経験の範囲外から「魔法のように」得られる) が関係します。
A more generally-applicable version of this approach is known as shaping, where a larger overall problem space is initially compressed into a much smaller, simpler space, in a way that can then be gradually expanded to encompass the much larger, richer space of interest. The educational curriculum is specifically designed in this way, with a long sequence of foundational building blocks that lead up to high levels of overall capability in complex, real-world problem spaces. Early learning in human development benefits from “starting small”, with limited memory, perceptual and motor capacities reducing the size of the search space ([[@Newport90]]; [[@Elman93]]; [[@Thompson-SchillRamscarChrysikou09]]; [[@YuSmithChristensenEtAl07]]).
-
効率的な (多項式時間) 検索アルゴリズムを使用する: 専用の並列 状態表現と勾配ベースのアルゴリズムを使用することで、実際に次元と次元で戦うことができます。このアプローチにはさまざまな表現があります。
-
より一般的には、[[constraint satisfaction]] および [[optimized representations]] を介して、実行前の計画プロセスにおける専用並列、勾配ベースの [[search]]。つまり、効率的な検索アルゴリズムを使用して、「合理的な」一貫した計画を迅速に見つけて、実際の一連の行動の試行錯誤を通じて探索することができれば、有効な検索スペースのサイズを大幅に削減できます。この計画プロセスにより、スペースが効果的に圧縮され、上記の両方のソリューションが統合されることに注意してください。
-
アクションの [[distributed representations]] を使用し、段階的なダイナミクスを使用して、オンライン アクション コントロール スペースを介した専用の並列勾配ベースの検索。これにより、一度に 1 つの個別のアクションを選択することで、意味のある勾配を連続的にではなく並列的に探索できます。これは、[[basal ganglia]] の背外側運動野が行っているように見えます。これは、[[#state abstraction]] の勾配ベースの学習と連携して、状態のよりコンパクトで効率的な表現を作成し、それによって空間全体の次元を削減します。
-
[[Evolution]] は、[[bias-variance tradeoff#neural biases]] で説明したように、ゲノムと生物の空間にわたって効率的に生存と繁殖を最大化するものを見つけるための高度な並列検索アルゴリズムです。
-
文化の進化と文化に基づく学習 (教育システムなど) は、並行検索のもう 1 つの重要な形式を表しており、社会の各個人が時間をかけて空間全体の異なる部分を検索し、発見したものを他の全員と共有することができます。私たち全員が学校で学ぶ数学、科学、人文科学にわたる多くの著名な進歩は、個人が「自然状態で」単独で発見できるものと比較して、さらなる学習のための信じられないほど高度な基礎を提供します。もちろん、これらすべては [[language]] に大きく依存しており、[[large language models]] はこの方法でどれだけのことが学べるかを明確に示しています。また、他の人から共有し、学びたいという動機を与えるソーシャル [[emotion drives]] にも依存します。
したがって、人間の脳が「上記すべて」の方法で次元の問題に取り組んでいることは明らかであり、これは [[Axon]] および [[Rubicon]] でとったアプローチと同様です。これらのソリューションは、RL における標準的なモデルベースとモデルフリーの区別と正確には一致していませんが、「モデル」という用語がいくつかの場所で使用されています。いずれの場合でも、この区別を使用して、より単純なモデルフリーのアプローチから始めて、RL モデルの空間の理解を有益に形作ることができます。
モデルフリー
抽象的な数学的観点から、RL はマルコフ決定プロセス (MDP) として定式化できます。これは、現在の状態とエージェントが実行するアクションに基づいて、特定の将来の状態の確率を決定する単一 (正規化) 遷移行列 $T$ に従って、時間の経過とともに展開する個別の状態 $S$ が存在することを意味します。決定的な教科書的な治療法については、[[@SuttonBarto98]] を参照してください。
時間差 (TD) アルゴリズムは、このコンテキストで期待される報酬を最適化するための学習メカニズムを提供し、RL で使用される最も中心的な抽象的な学習ルールの 1 つです ([[@Samuel59]]; [[@SuttonBarto81]]; [[@Sutton88]]; [[@SuttonBarto98]])。さらに、これは、脳幹の腹側被蓋野 (VTA) にある [[dopamine]] ニューロンの発火特性の多くについて、驚くほど正確な説明を提供します ([[@MontagueDayanSejnowski96]]; [[@SchultzDayanMontague97]])。
{id=”figure_actor-critic” style=”高さ:20em”}
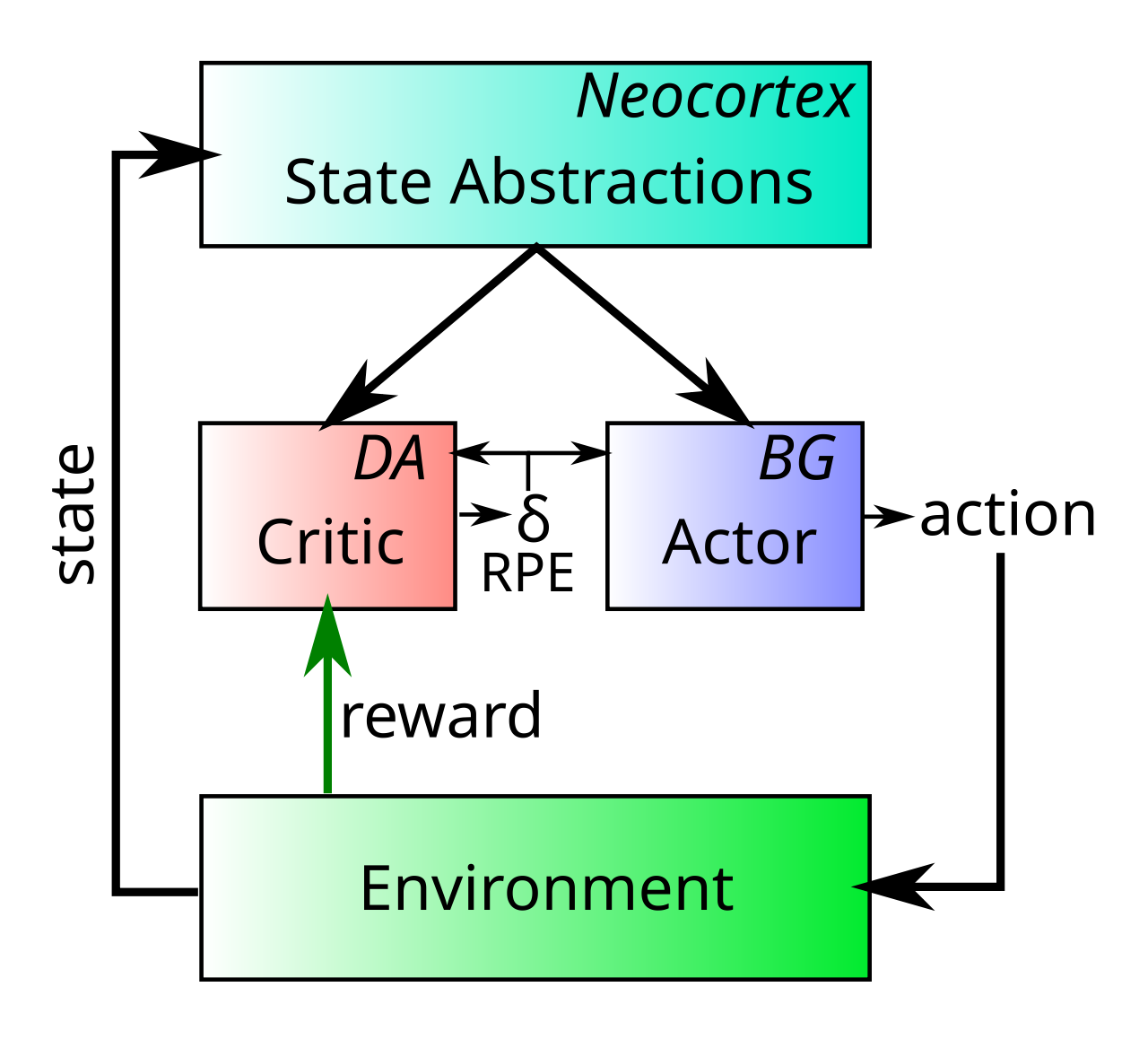
具体的には、TD は、予測された報酬結果と実際の報酬結果の差に基づいて [[#reward prediction error]] (RPE) 信号を計算する方法を提供します。 アクター批評家 アーキテクチャ ([[@BartoSuttonAnderson83]]) では、この RPE 信号は 批評家 によって生成され、報酬を得るために アクター が行う運動動作と批評家の報酬予測の精度の両方を向上させるためのトレーニング信号を提供します。これは、ドーパミンが脳全体、特に行為者と批評家の両方の機能を持つ [[basal ganglia]] の学習を調節することを示すかなりの神経科学データと一致しています。
報酬予測エラー
まず、報酬予測誤差の最も単純で影響力の高いモデルである レスコルラ・ワグナー 条件付けモデル [[@RescorlaWagner72]] から始めます。これは、デルタ ルール ([[error-backpropagation]] を参照) と数学的に同一です。
RPE $\delta$ は、実際の報酬 ($r$) と期待される報酬 ($\hat{r}$ の報酬) の差にすぎません。
{id=”eq_rw” title=”レスコルラ・ワグナー RPE”} \(\デルタ = r - \hat{r}\)
ニューラル ネットワークでは、この期待報酬 $\hat{r}$ は、感覚入力ユニットからのシナプスの重みによって計算できます。
{id=”eq_rw-net” title=”レスコルラ・ワグナー RPE”} \(\デルタ = r - \合計 x w\)
重みは実際の報酬値を正確に予測することを学習でき、このデルタ値は重みが変化する方向を指定します。
{id=”eq_rw-dw” title=”レスコルラ・ワーグナーの学習”} \(\デルタ w = \デルタ x\)
これは、刺激アクティビティ x への重要な依存性を含め、デルタ学習ルールと同じです。実際に存在する刺激 (つまり、ゼロ以外の x) の重みのみを変更する必要があります。
[[dopamine]] の [[dopamine#figure_da-schultz]] の 2 番目のパネルに示すように、報酬予測が正しい場合、実際の報酬値は予測によって_キャンセルされます_。このルールは、図に示されている他のケース (正および負の報酬予測誤差) も正確に予測します。
ただし、Rescorla-Wagner モデルが捉えていないのは、[[dopamine#figure_da-schultz]] の 2 番目のパネルの CS の開始までの [[dopamine]] の発火です。
TD
これに関連して、TD アルゴリズムは、(名前が示すように) 方程式に時間を導入することで CS 開始発火を捕捉します ([[@SuttonBarto81]]; [[@SuttonBarto98]])。 Rescorla-Wagner と比較して、TD はデルタ方程式 f に 1 つの追加項を追加するだけで、これは、将来発生する可能性のある_将来_の報酬値を表します。
{id=”eq_td-f” title=”TD 将来報酬”} \(\delta = (r + f) - \hat{r}\)
ここで、報酬期待値 $\hat{r}=\sum x w$ は、現在の報酬 r と将来の報酬 f の両方を予測する必要があります。 CS がその後の報酬を確実に予測する単純な条件付けタスクでは、CS が到着すると、近い将来に報酬が得られる可能性が高いため、CS の開始によってこの f 値が増加します。さらに、CS の開始は以前のどの合図によっても予測されないため、この f 自体は予測不可能です (もし予測できた場合、その初期の合図が実際の CS であり、ドーパミン バーストを駆動することになります)。したがって、r-hat の期待値は f 値を打ち消すことができず、ドーパミンのバーストが発生します。
この f 値はCS開始時のドーパミン発火を説明していますが、システムは将来どのような報酬が得られるかをどのようにして知ることができるのでしょうか?という疑問が生じます。未来に関係するものと同様に、基本的には、可能な限り過去をガイドとして使用して、推測する必要があります。 TD は、報酬推定値の長期にわたる一貫性を確保_することによってこれを実現します。実際には、時間 _t での推定値は、時間 t+1 での推定値のトレーニングに使用されるなど、時間の経過とともにすべての一貫性が可能な限り維持され、時間の経過とともに受け取られる実際の報酬との一貫性が保たれます。
これはすべて、現在および将来のすべての報酬の合計である 値関数 V(t) を指定することで、非常に満足のいく方法で導出できます。将来の報酬は gamma 係数で 割引されます。これは、将来の報酬は、より早く発生する報酬よりも価値が低いという直感的な概念を捉えています。ポパイの中でウィンピーのキャラクターが言うように、「今日のハンバーガーの代金は火曜日に喜んで払います。」これは、将来に向かう無限和である値関数です。
{id=”eq_v” title=”値関数”} \(V(t) = \left。 r(t) + \gamma^1 r(t+1) + \gamma^2 r(t+2) ... \right。\)
この方程式を再帰的に書くことで無限大を取り除くことができます。
{id=”eq_v-r” title=”再帰値関数”} \(V(t) = \left。 r(t) + \ガンマ V(t+1) \right。\)
そして、確かなことは何も分からないため、これらの値の用語はすべて実際には推定値であり、その上の小さな「帽子」で示されています。
{id=”eq_v-hat” title=”推定値関数”} \(\hat{V}(t) = r(t) + \gamma \hat{V}(t+1)\)
したがって、この方程式は、時刻 t+1 における将来の推定値に関して、現在の時刻 t における推定値がどのようになるかを示します。次に、両辺から V ハットを差し引きます。これにより、上記の等式を別の方法で表現する式が得られます。つまり、これらの項の差はゼロに等しくなるはずです。
\[0 = \left( r(t) + \gamma \hat{V}(t+1) \right) - \hat{V}(t)\]これは、TD が時間の経過とともに推定値の一貫性を維持しようとする点を数学的に示しています。つまり、推定値の差はゼロである必要があります。しかし、V ハットの推定値を学習しているとき、この差はゼロではなくなり、実際、ゼロではない程度が報酬予測誤差の程度となります。
{id=”eq_td-delta” title=”TD デルタ RPE”} \(\delta = \left( r(t) + \gamma \hat{V}(t+1) \right) - \hat{V}(t)\)
これを上記の f を含む方程式と比較すると、次のことがわかります。
\[f = \gamma \hat{V}(t+1)\]すべての変数の時間依存性を明確にし、報酬の期待値が代わりに「値の期待値」になったことを除いて、他のすべては同じです (r ハットを V ハットに置き換えます)。また、Rescorla-Wagner と同様に、ここでのデルタ値は値の期待値の学習を促進します。
TD 学習ルールは、さまざまな条件付け現象を説明するために使用でき、脳内のドーパミン ニューロンの発火との適合により、膨大な量の研究が進歩しました。これは、脳機能を理解 (および予測) するための計算モデリング アプローチの真の勝利を表しています。
神経科学の観点から見ると、[[PVLV]] モデル ([[@OReillyFrankHazyEtAl07]]; [[@HazyFrankOReilly10]]; [[@MollickHazyKruegerEtAl20]]) に要約されているように、実際には、連携して VTA ドーパミン ニューロンの発火を駆動するさまざまな脳領域と回路が多数存在します。これらのメカニズムは、特に、US の時点から CS の時点までの発火の連鎖状の進行が存在しないことなど、TD モデルの予測と比較してドーパミン発火挙動にいくつかの重要な違いを生み出します ([[@MollickHazyKruegerEtAl20]])。それにもかかわらず、TD モデルは、さまざまな脳領域にわたる学習におけるドーパミンの役割の多くの重要な側面を説明する、洗練された計算能力の高い学習フレームワークを提供します。
TD と時間微分学習
これらはいくつかの核となる概念的な類似点と非常によく似た名前を共有していますが、TD フレームワークを、[[kinase algorithm]] を介して [[neocortex]] の [[error-driven learning]] に対して [[Axon]] で使用される [[temporal derivative]] ベースの学習メカニズムと区別することが重要です。生物学的な観点から最も重要なことは、TD は時間差信号をドーパミン ニューロンの発火に変換し、それが RPE 信号を「明示的に」表すことです。対照的に、時間微分フレームワークの予測誤差信号は、時間の経過に伴う神経活動の差として暗黙的に残り、双方向接続を介して新皮質全体に伝播します。次に、各シナプスは、ドーパミンが果たす直接的な神経調節の役割とは対照的に、これらの時間微分に敏感な方法でシナプスの重みを局所的に調整します。
モデルベース
モデルフリー RL ([[@MoerlandBroekensJonker21]]; [[@PlaatKostersPreuss23]]) に加えて、またはモデルフリー RL の代わりに、さまざまなモデルベースのメカニズムを使用できます。これらのメカニズムの多くは、認知および神経科学の領域に直接類似しており、これらの領域に対する計算上の洞察を提供するのに役立ちます。これから明らかになるように、これらのアプローチにはそれぞれ明確な直観的な利点がありますが、より現実的で複雑なタスク ドメインではこれらの利点の実現を妨げる重大な計算上の課題もあります。
| これらの課題のほとんどの根本は、上で説明した [[curse of dimensionality]] に他なりません。具体的には、標準的なモデルベースの RL アプローチの多くは、さまざまな可能なモデル、計画、または目標の空間を介したシリアル [[search]] に基づいていますが、関連する空間の次元が増加すると、すぐに扱いにくくなります。この問題は、モデル自体の複雑さの増大と相まって、モデルベースのアプローチが、特定の明確に定義された問題に対する、より「強引な」[[bias-variance tradeoff | big-data]] 学習ソリューションで回避できるモデルフリーのアプローチよりもパフォーマンスが劣る傾向がある理由です。 |
ただし、モデルフリーのアプローチでは、新しい環境や問題に効果的に対処できる真に柔軟なシステムが決して得られないことは明らかです。これは、これらの新しい状況に適応するために必要な抽象化やメカニズムがなければ、直接のアクション ポリシーを学習するだけだからです。
したがって、モデルフリーのアプローチがその理論的可能性を最大限に発揮するには、前に説明した解決策を適用する必要があります。つまり、学習を構築する進化的基盤を含む、探索空間全体を圧縮するさまざまな方法や、(脳などの並列ハードウェア上で) 高次元空間に効果的に拡張する並列探索アルゴリズムを使用するなどです。
[[Axon]] の [[bidirectional connectivity]] を介した並列 [[constraint statisfaction]] は、高次元空間を効率的に検索し、より単純な低次元の抽象化に還元する [[optimized representations]] を動的にアクティブ化できます。これらの小さな空間は、進化に基づいた [[Rubicon]] 目標駆動システム内で順次操作することができます。このシステムは、追求すべき当面の最適な目標を保守的に選択し、これらの決定を下すための適切な情報を提供するように学習を形成することによって、空間を最も効果的に検索する方法について強いバイアスを提供します。
これらすべてを念頭に置いて、モデルフリーの傘に該当する特定のアプローチのいくつかを以下で説明します。
状態の抽象化
多くの場合、生の状態入力を直接使用する代わりに、より高いレベルの抽象化により、どのアクションを実行するかを決定するためのより良い基礎空間が提供されます。この計算原理の重要性については、[[categorization]] および [[generalization]] で詳しく説明されており、人間の知能の多くの重要な側面は、事後 [[neocortex]] で実行される強力な抽象化に依存しています。実際、私たちの脳は、さまざまな抽象レベルで、世界の豊富で複雑な内部モデルを提供します。
[[abstract neural network]] の深い層のアーキテクチャにより、この種の抽象化の開発が可能になり、そのようなアーキテクチャと強化学習の組み合わせにより、Atari ビデオ ゲームからチェスや囲碁などの古典的なゲーム (例: [[@SilverHuangMaddisonEtAl16]]) まで、さまざまなゲームのプレイなどの難しいタスクで印象的なパフォーマンスが実現しました。模範的な例は、ディープ Q ラーニング ネットワーク (DQN) ([[@MnihKavukcuogluSilverEtAl15]]) です。これは、前述のように、ディープ畳み込みネットワーク (DCN) と TD スタイルの Q ラーニングを結合し、「エンドツーエンド」の [[error backpropagation]] を使用して、多くのネットワーク層にわたって表現をトレーニングします。これにより、アクションの選択と報酬予測に特化して最適化されます。
DQN モデルから得られる重要な洞察の 1 つは、オンラインでトレーニングすると、試行錯誤学習の逐次的な性質が強力な正のフィードバック ループを引き起こすということです。これは、実際の経験と比較して学習の順序をランダムに再シャッフルすることで軽減できるということです ([[@Lin92]])。 [[@^MnihKavukcuogluSilverEtAl15]] は、このメカニズムについて [[hippocampus]] からの生物学的インスピレーションを引用しましたが、ほとんどの形式の RL 学習が海馬病変を持つ人々 (例: [[@Corkin02]]) に保存されているため、これは実際にはあまり妥当ではありません。したがって、この問題は、生物学に基づいたアプローチにとって解決すべき重要な課題として残っています。
| 環境の内部モデルの [[Predictive learning]] は、アクションを生成するための低次元の基礎を提供する、コンパクトで体系的な [[combinatorial-vs-conjunctive | combinatorial]] 表現を生成できます。予測学習で訓練された [[large language models]] の強力な内部表現は、このアプローチの良い例であり、人間が新皮質で学習する種類の深い意味論的知識の優れたモデルを提供します。 |
状態抽象化が並列勾配ベースの学習に依存する限り、次元の呪縛を回避できるため、多くの成功した RL モデルの確立された不可欠な要素となります。
世界のモデル
ロボット工学の分野で広く議論されている「ワールド モデル」の概念は、状態抽象化の概念を拡張して、環境の MDP 遷移行列を形式的に近似できる時間ダイナミクスを含めます。したがって、このようなモデルは、モデルベースの RL の本来の定義である、さまざまな可能な行動方針の「精神的シミュレーション」または「想像」に使用できる可能性があります。この初期の模範的な例は、[[@^Sutton91a]] の Dyna アーキテクチャです。これは、学習済み遷移行列関数を使用して合成トレーニング データを生成し、学習プロセスを加速します。
ワールド モデルは、環境 [[@JordanRumelhart92]] の_順モデル_としても知られており、本質的には [[predictive learning]] が行うこと、つまり次に何が起こるかを予測することを学習することです。このページで詳しく説明したように、環境内に逐次構造がある場合、予測学習は基本的に「無料」であり、これが [[large language models]] が大量のテキスト データでトレーニングできる理由です。したがって、後部新皮質学習の主要な要素は、世界のこの種の動的、予測的、前向きモデルの学習であると想定されます。
このようなモデルの最近の例には、さまざまな Dreamer ネットワーク ([[@HafnerLillicrapNorouziEtAl22]]; [[@HafnerLillicrapFischerEtAl18]]) が含まれます。これは、さまざまなビデオ ゲーム ベースの環境のコンテキストで学習された世界モデルを使用して、予測された一連のイベントのマルチステップ ロールアウト を行います。これらのロールアウトにより、考えられる行動の選択による将来の結果を予測できるため、より適切な意思決定が可能になる可能性があります。
ただし、このようなモデルの主な問題は、タイム ステップが反復されると不正確さが指数関数的に増大し、通常、環境が十分に確率的であるため、将来のさまざまな「タイムライン」の分岐係数も指数関数的に増加することです (最近のマーベル ユニバース映画は、この問題をうまく捉えています)。したがって、このアプローチは、特定の状態内の時間と複雑さの関数として、状態空間の [[curse of dimensionality]] の下ですぐに破綻します。
マルチスケール モデル
階層的なマルチスケール表現の長年の原理 (例: [[@BartoMahadevan03]]) は、次元が十分に低く、確率性がダイナミクスに直接現れるのではなく抽象化にカプセル化される、より抽象的で粗粒なレベルで予測を実行することにより、ワールド モデルにおける上記の問題の解決に役立つ可能性があります。これは、[[Rubicon]] モデルの重要な要素です。
RL への階層的アプローチには、subgoals の概念が含まれています。これは、広く議論されている RL の options フレームワーク ([[@SuttonPrecupSingh99]]) や ACT-R フレームワークの chunking メカニズム ([[@AndersonLebiere98]]) のように、複雑な問題をより管理しやすいサブタスクに分割することです。これらおよび関連する階層 RL アプローチの難しさは、関連するサブタスクをいつ、どのように編成するかを知るのが難しいことが多く、そうするための方法の数が再び指数関数的組み合わせ爆発問題 ([[@PateriaSubagdjaTanEtAl21]]) にさらされる可能性があることです。したがって、タスクおよび計画の表現を形成するためのさまざまなヒューリスティック メカニズムが、より複雑な現実世界のケースにまでスケールアップされるかどうかは楽観的ではありません ([[@CollinsFrank13]]; [[@SchapiroRogersCordovaEtAl13]])。
さらに、あらゆる種類の「厳格な」階層システムが提案されているほぼすべての場所で、現実世界は実際にはそのようなシステムにそれほど適しておらず、より段階的で柔軟な「ソフト」なフレームワーク (例: [[@RogersMcClelland04]]) が必要であることがすぐにわかります。
計画メカニズム
計画アルゴリズムに関する膨大な文献があり、多くの場合、RL の世界で使用されるアプローチに収束しています ([[@RussellNorvig16]]; [[@MoerlandBroekensJonker21]])。直観的なアイデアには、現在の状態から前方に検索して望ましい結果を見つけることと、望ましい結果の状態から逆方向に検索して現在の状態に接続するパスを見つけることが含まれます。どのような場合でも、計画プロセスには、空間を探索するためにさまざまな可能なアクションをシミュレートできるワールド モデルのようなものが必要です。
人間に勝つ AI は、チェスと囲碁のゲームにアプローチします。このアルゴリズムは、深刻な組み合わせ爆発問題 ([[@SilverHuangMaddisonEtAl16]]; [[@SilverSchrittwieserSimonyanEtAl17]]) に対処するために、これらのゲームのルールと関連構造に関するドメイン固有の知識を使用して構築された、古典的なスタイルの状態空間計画アルゴリズムに依存していました。したがって、これらの特定の例は成功しているにもかかわらず、問題空間を探索するために必要なドメイン固有の知識を活用する能力に欠けている、より複雑な現実世界のタスクに一般化することはできません。
上で説明したこれらの組み合わせ爆発問題に対する全体的な解決策と一致して、計画を並行して実行する必要があることは明らかであり、これはまさに並列 [[constraint satisfaction]] プロセスが効果的であることが知られているものです。このプロセスでは、一方向または別の方向に逐次的に検索するのではなく、スペースの形状、ツール、または利用可能なその他の成果物などの観点から、環境から利用可能な他の任意の数の制約とともに、開始結果状態と目標結果状態の両方と一致する計画を並行して検索します。
探索と活用
RL フレームワークは、潜在的により大きな報酬を獲得するために新しい行動計画や環境の領域を探索することと、現在最適な選択を行うことで報酬を最適化するためにすでに学習したことを活用することとの間の基本的なトレードオフを明らかにします。私たちは、新しいレストランやメニューの新しいアイテムを試すか、確立されたお気に入りを選ぶか選択するたびに、このトレードオフを経験します。興味深いことに、これらの行動には個人差があり、新しい経験に対する寛容さなどの安定した性格特性に関連しており、単一の最適な解決策は存在せず(だからこそトレードオフになる)、すべての基盤をカバーするには集団全体の変動が有益であることを示唆しています。リスクを冒して素晴らしい新しい発見をする人もいますが、確立された報酬を確実に確実に享受する人もいます。
年齢は探索と活用のバランスにおいても重要な役割を果たしており、若いうちは空間のより広い範囲で何が機能するかを発見するためにより多くの探索が必要ですが、高齢者は蓄積された知恵をより安全に信頼できます。このバランスの変化は、学習が進むにつれて RL システムで自然に発生する可能性があります。アクションの選択が、最初は小さく曖昧な学習された重みに基づいている場合です。重みが強くなり、より鋭く調整されるにつれて、動作は自然に既存の重みによってより決定されるようになります。追加のハイパーパラメータを調整して、このバランスを変更することもできます。
たとえば、青少年の悪名高い危険な行動は、落ち着いて退屈な老人になる前の探求バイアスの高まりに起因すると考えられています ([[@CaseyGetzGalvan08]])。 [[dopamine]] 神経調節レベルの変化は、この変化 ([[@Spear00]]) に起因すると考えられています。
[[Rubicon]] モデルには、他に利用可能な学習済みオプションがない場合に探索を誘導する新規性バイアスが含まれており、満腹感によってさらなる探索を促進できるように内部ドライブ状態も更新します。さらに、Rubicon は、個々のアクション ステップではなく、全体的な目標状態のレベルで探査を実装します。これは、より戦略的な探査戦略をサポートするために重要です ([[@EcoffetHuizingaLehmanEtAl21]])。