compcogneuro/web: rubicon
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/rubicon.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Neuroscience”] bibfile = “ccnlab.json” +++ ルビコン は、もともと [[@^HeckhausenGollwitzer87]] によって提案された理論で、[[@^OReillyHazyMollickEtAl14]] および [[@^OReilly20]] で独自に開発および詳細化されました ([[@HerdKruegerNairEtAl21]]、[[@OReillyNairRussinEtAl20]] も参照)。これは、[[Axon]] における目標駆動型の学習と認知のシステム神経科学モデルを動機付けます。モデル。
この理論の名前の由来となっている中心的な考え方は、目標達成 状態への移行にはかなりのレベルの心理的/感情的投資が伴うというもので、これはシーザーがルビコン川を渡り、それによって潜在的に重大な結果が生じる可能性を認識した上で、ある行動方針に完全にコミットすることに似ています。
主観的かつ直観的な観点から見ると、私たちのほとんどは、重大な影響を伴う人生の主要な選択(例:大学にどこに行くか、結婚するか、子供を産むかなど)に関して、この種の重大な決断を経験したことがあると思われます。しかし、ルビコン理論はさらに一歩進んで、調整された行動計画に参加するすべての決定には、少なくともある程度の心理的関与が関連していると主張しています。
この取り組みの結果の 1 つは、この計画の望ましい結果が達成されなかった場合、少なくともある程度の「失望」、「不満」、「悲しみ」、および/または「怒り」を経験することです。実際、目標の失敗に直接結びついているこれらの [[emotion]]al 状態の広範で普遍的な性質は、これらの目標に取り組んでいる状態の現実を裏付けています。
目標への関与のさらなる結果は、目標失敗時にこうした否定的な感情を経験するリスクがあるため、目標選択のプロセスが比較的保守的になるよう圧力をかけることです。これは、人々が何かを始めるのにしばしば「不合理に消極的」に見える理由、つまり「先延ばし」として知られる理由を説明することができます。あなたもおそらく、掃除、書類を書く、納税などの骨の折れる仕事を怖がるのに、実際にはそれが以前の予想に比べてどれほど簡単だったかにうれしい驚きを感じたという現象を経験したことがあるのではないでしょうか。
この不一致は、特定の目標に取り組むことに関連するコミットメント(および機会)コストの合理的な結果と見なすことができ、先延ばしのほぼ普遍的な経験は、私たちの日常生活を形成する際にこれらの目標中心の要因が広く浸透している性質のさらなる証拠を提供します。
計算の観点から見ると、ルビコン フレームワークの中心的な前提は、関連する目標を達成するには、エージェントが将来を見越して結果を重視した方法で特定の行動方針にコミットする必要があり、目標選択状態と目標関与状態では 2 つの異なる価値関数が有効であるということです。
-
目標に取り組む価値関数は、「現在選択されている目標の達成」に重み付けされます。これは重要な利点を提供するためです。その最も明白な点は、途中で「馬」を常に切り替えたり、一般に非コミット的な方法でふらふらしたりすることは、計画に完全にコミットするのと同じ種類の成功につながる可能性が低いことです。特に、目標に向かってすべてを注ぎ込み、失敗(または成功)することが最良の学習方法です。本当に努力せずに失敗した場合、[[credit assignment]] という重大な問題が発生します。失敗したのは、努力しなかったからですか、それとも次回は別の計画や目標を採用する必要があるからですか?
-
目標選択価値関数は、関連するすべての状況要因 (例: 飢餓などの内部状態、目に見える機会などの外部状態) を考慮して、_利用可能な目標オプションを保守的に評価_し、最良の利益対費用比を生み出すものを選択することに重み付けされます。私たちが先延ばし癖でよく経験するように、これは、長くて難しい目標よりも、簡単で短期的な目標を選ぶ傾向があることを意味します。
この強くシリアルで、単一の点に焦点を当てた目標に基づいた行動の組織化は、効果的な解決策を得るために [[search]]ing の [[curse of dimensionality]] を克服するために不可欠である、より並列、分散、段階的な処理および学習メカニズムを支持する強力な議論と矛盾します。しかし、ある時点で、環境内で行動する個々の生物の特異な性質には、単一の調整された行動計画が必要になります。つまり、多くの異なるアクションを同時に並行して部分的に実行することはできません。
したがって、各結果から可能な限り多くのことを学習し、専用の並列 [[constraint satisfaction]] 処理を使用して目標選択プロセスを最適化し、単一の最適な次のステップを選択するプロセスで多くの考えられる計画と制約が効果的に評価されるようにすることで、このシリアル検索プロセスの悪影響を最小限に抑えるために、目標駆動システムに関する他のすべてを最適化する必要があります。さらに、より大きな目標に向かって段階的にステップを進める「アジャイル」モードにより、システムの柔軟性が維持されます。
タイムスケール
Tao Te Ching のことわざは、目標のタイムスケールに関する重要な問題を要約しています。
「千里の道も一歩から始まる」
任意の時点で選択されるアクティブな目標は、旅全体そのものというよりは、長い旅に関連する方向への 1 つのステップに近く、個々の目標選択ステップに情報を与え、制約するアクティブなコンテキスト情報の広範なセットとして表されます。目標への取り組みのタイムスケールは、オーバーコミットによるコストを最小限に抑えるため、有意義で測定可能な結果が得られる一方で、できるだけ短くする必要があります。
広く引用されている SMART 目標設定フレームワーク (具体的、測定可能、達成可能、関連性、期限付き ([[@Doran81]]) は、積極的に取り組む目標がどうあるべきかについての良い経験則を提供します。具体性は、実際に積極的な目標状態への移行を促進するために重要であるため、行動を導くための実際の具体的な行動計画が存在します。これは、以下で説明されている実装意図の if-then 計画と一致しています) [[@^GollwitzerSheeran06]]。
| したがって、中核となる目標主導型システムは、行動の「内部ループ」を制御し、数秒から数分の比較的短い時間間隔で動作して、行動を積極的にガイドします。このコア目標システムは [[evolution | evolutionarily]] 古くから存在し、新皮質と連携して機能する多くの皮質下脳領域によってサポートされているため、[[conscious awareness]] のレベルを下回る傾向があります (興味深いことに、この目標システムは [[evolution#evolution of neocortex]] の主な推進力であるようです)。 |
目標選択のより意識的で熟慮的な側面は、より拡散したコンテキストと制約の「外側ループ」を構成します。これらも内側ループの目標選択と関与プロセスの過程でアクティブ化および更新されますが、アクティブな目標のようにオンラインの行動選択を直接導くものではありません ([[@HerdKruegerNairEtAl21]])。
したがって、何をすべきかを座って考えているときは、さまざまな可能性を評価するために、これらのインナーループの目標に関わるステップを数多く実行する可能性があります。より大きな旅の最初のステップを踏み出すことを決定した場合、目標への取り組みへの移行に関連するアクティブなメンテナンス サポートも、これらのより長いタイムスケールの計画に関連する漠然とした計画の「船を持ち上げる」ため、内側のループの目標ステップの流れに沿って実行されます。 [[@^Gollwitzer12]] は、これらのより広範な計画を「望んでいる」(およびそのさらに漠然とした前任者は「希望」) と呼んでいますが、アクティブな内部ループは「喜んでいる」としています。
神経科学の観点から見ると、これらの目標関連の原則には、目標の選択と関与の全体的なダイナミクスを何らかの方法で組織化し、さまざまなオプションなどの費用と利益のトレードオフの適切な推定値を目標選択プロセスに提供する神経メカニズムが必要です。目標の成功または失敗の感情的な結果として主観的に経験するものは、生存に関連した行動に向けて私たちを導くために進化した脳幹回路によって駆動されるため、[[emotion]]al / 動機付けシステムが中心となります。
広範な研究に基づいて、これらの脳システムには、腹側および内側の [[prefrontal cortex]]、[[basal ganglia]]、[[amygdala]]、および [[dopamine]] および [[acetycholine]] を含む神経調節システムを含む、相互接続された複数の層の領域が関与しています。従来、これらの領域は [[limbic system]] としてグループ化されてきましたが、この用語はおそらく明確さよりも混乱を招く可能性があります。
後続のセクションでは、ルビコン フレームワークの基礎となる関連する計算、認知、および神経科学の問題のより詳細な概要を説明します。さらに詳しくは、次のページで説明します。
-
[[PVLV]] は、これらの脳領域に基づいた [[reinforcement learning]] メカニズムの生物学的ベースの中核であり、相次 [[dopamine]] 発火および動物の条件付けに関する文献に関する幅広いデータを説明します。
-
[[Arm maze simulation]] は、シミュレートされたげっ歯類のようなエージェントを使用して、マルチアーム意思決定パラダイムにおける基本的な手段選択の統合モデルにすべてをまとめます。
計算の概要
既存の [[reinforcement learning]] モデル (このページは、この概要の次のステップとして読むことを強くお勧めします) の観点から、Rubicon フレームワークは、予測世界モデルによる状態抽象化を含む、さまざまな形式の [[reinforcement learning#model-based]] RL を実装しており、[[constraint satisfaction]] 経由で [[bidirectional connectivity]] を使用して並行して計画を実行できるため、[[curse of dimensionality]] を軽減できます。シリアル計画のダイナミクスに関連しています。
[[reinforcement learning]] 問題を定義する、さまざまな環境のアクション空間での試行錯誤プロセス [[search]] は、アクション空間と状態空間がより複雑になるにつれて、この次元性の呪いに悩まされます。したがって、RL ページで広く説明されているように、学習を成功させるには、環境状態表現を圧縮するさまざまな方法と、Axon メカニズムによってサポートされる制約満足や [[optimized representations]] などの複数のレベルでの専用並列検索戦略を採用する必要があります。
さらに、ルビコンは、与えられた状況でどの目標を追求するかについて十分な情報に基づいた選択をするために必要な情報を獲得することに重点を置いた学習に基づいて、目標の選択と維持のプロセスをサポートする重要な神経回路を組み込むことによって、数百万年分の [[computational-cognitive-neuroscience#reverse engineer]] を実行する試みを表しています。この進化的基盤は、既存の RL モデルからの大きな逸脱を表していますが、環境とアクションがより複雑になるにつれて、次元の問題の呪いを軽減する必要があると考えています。
{id=”figure_rubicon-rl” style=”高さ:20em”}
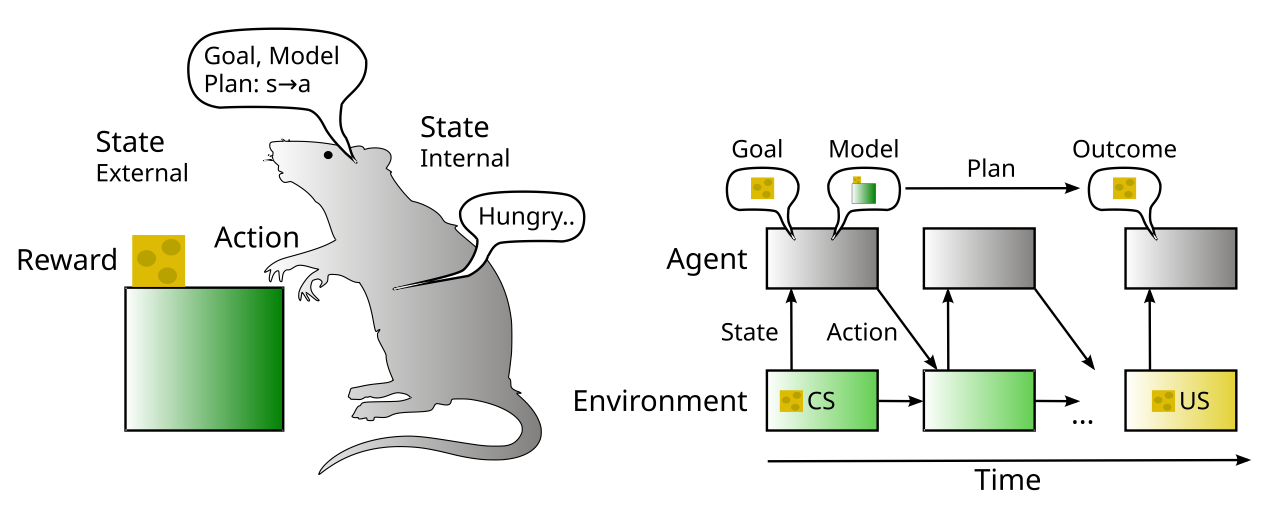
これらの目標指向メカニズムの最終的な効果は、次の計算ステップを中心に動作を整理することです ([[#figure_rubicon-rl]] で示されています)。
-
既存の積極的な目標がない場合は、効率的で抽象的な内部モデルによって指示される方法で環境を探索し、利用できる可能性のある有用な結果 (食料やその他の資源など) を示唆する手がかりを探します。
-
そのような考えられる機会ごとに、並列制約充足処理を使用して、望ましい結果を得るために必要な可能なアクション プランの学習された表現を効率的に検索し、合成的にアクティブ化します。この処理に関与する制約には、努力、リスク、不確実性要因が含まれ、これらは結果の状況に応じた利益(たとえば、現在の飢餓レベルの影響など)と比較して比較検討されます。腹側前頭前皮質と内側前頭前皮質内のさまざまな脳領域は、これらのさまざまな要素の学習に特化しており、これらはすべて、この目標選択プロセス中に双方向に相互作用します。
-
利用可能な最良のオプションは、決定に費やす時間と労力の量を決定する緊急性やその他の要因によって調整される評価プロセスの後に選択されます。これは、システムがルビコン川を渡って目標に取り組んだ状態になり、オプションを保守的に評価するのではなく、選択した目標を達成することに集中するようになるときです。利益とコストの推定、および計画プロセスの結果はすべて、それぞれの前頭前皮質領域で堅牢に維持されるアクティブな維持状態に「ゲート」され、目標追求プロセスを導くために必要な重要な情報を含む分散目標表現を提供します。
-
維持された行動計画は、計画 ([[@MillerCohen01]]; [[@OReillyBraverCohen99]]) と一致する運動行動の選択に偏りを与え、[[reinforcement learning#model-free]] RL のような厳格で静的に学習された行動ではなく、動的な政策誘導行動を提供します。アクション アフォーダンスが発生すると、この計画は進行中の制約充足処理を通じて更新でき、学習された環境とアクション モデルによる並行検索を活用して、明白な行動検索を効果的に絞り込み、最も有望なアクションに焦点を当てます。
-
維持されたコストと利益の見積もりは、進行中の進捗を測定するためのアクティブなベンチマークを提供します。物事が予想よりも長くかかり、予想よりも不確実になり、予想された結果に向かうのではなく進歩が遠ざかっている場合、これは目標の放棄(つまり、「あきらめる」アクション)を引き起こす可能性があります。これには、この目標を達成できなかったことを記録し、それに応じて推定表現を更新する重要な学習信号が伴います。この「ドーパミンの低下」は主観的には失望として経験されます。
Instead of giving up in the face of unexpected difficulties, the system could expend additional effort to overcome these difficulties (i.e., perseverance, which can then turn into perseveration if it goes on too long). The neuromodulator [[norepinepherine]] has been implicated in this switch between perseverance and giving up ([[@Aston-JonesCohen05]]). The decision about whether and when to give up, versus try harder, depends on relevant contextual factors, all informed by prior learning experiences. Considerable evidence suggests that the [[lateral habenula]] plays a critical role in making this decision.
-
望ましい結果が達成されると、適切な正の報酬信号 (ドーパミンバースト) が生成され (内部的に、期待に対する結果の関数として)、それに応じて推定値が更新され、幸福または満足として経験されます。
したがって、動作は、維持された分散目標状態によって積極的にガイドされ、それによって、TD モデルのような将来価値の推定に基づくソフトマックス確率モデルを使用してアクションを選択する一般的な方法と比較して、より一貫性がありながらも動的な動作モードが提供されます。高次元空間をナビゲートするには、アクティブな計画に基づいて長期にわたるアクション選択の一貫性が重要です。高次元空間では、たとえ小さなノイズの可能性でも複数のステップにわたって蓄積され、一連の目標主導型アクション ([[@EcoffetHuizingaLehmanEtAl21]]) を必要とする目標を達成する能力が事実上阻害される可能性があります。
このアプローチの明白なコストは、特定の目標にコミットすると、別の目標を機会に選択することができなくなり、目標選択プロセスの精度が重視されることです。ただし、重要な仮説は、局所的な確率的推定に従って常にアクションを選択する場合と比較して、達成される (または放棄される) まで特定の目標に固執することの学習上のメリットが大きいということです。
上で説明したように、システムが具体的な結果(つまり、達成したかどうかを明確に評価できるもの)につながる目標の最短のタイムスケールに取り組むことに偏っている場合、これらのコミットメントコストと機会コストを軽減できます。これらの短期的な目標は、多くの場合、より大きな、より長い時間スケールの目標に向けたサブ目標として機能しますが、アクティブな目標の選択と関与のダイナミクスは、特に、一度に 1 つのアクティブに関与する目標状態のみが存在する、目標駆動型の行動のこの内部ループで動作します。
内部ループのタイムスケールが 1 つのアクションのみに縮小すると、システムは標準の RL フレームワークに崩壊するように見えます。ただし、内部ループが比較的短い場合でも、重要な仮説は、保守的な目標選択のメカニズムと、初期の目標選択状態の積極的な維持を使用した期待に対する結果の追跡が、全体的により戦略的で積極的な行動を「ブートストラップ」するのに役立つだろうということです。上で述べたように、タイムスケールが長くなると、外側ループの目標は一連の内側ループのステップとともに実行されるため、これらのステップの積極的、保守的、結果志向の性質によって形成されます。
| 計算の観点から見ると、このモデルが解決しなければならない究極の課題は、[[generalization | generative]] (新しい環境における体系的な動作) をサポートするのに十分な [[combinatorial vs conjunctive | combinatorial]] である新しい目標表現を学習することです。つまり、これまでに実行したことのないことについて、実際に実行する前にシステムが新しい計画をどのように合成できるかについての答えが必要です。作業仮説は、[[credit assignment#temporal credit assignment]] 問題を解決するプロアクティブで結果重視の学習メカニズムと、最適化された表現ダイナミクスを組み込むことによって、Rubicon フレームワークがこの中心的な未解決の問題に答えるだろう、というものです。 |
生物学的概要
{id=”figure_goal-bio” style=”高さ:20em”}
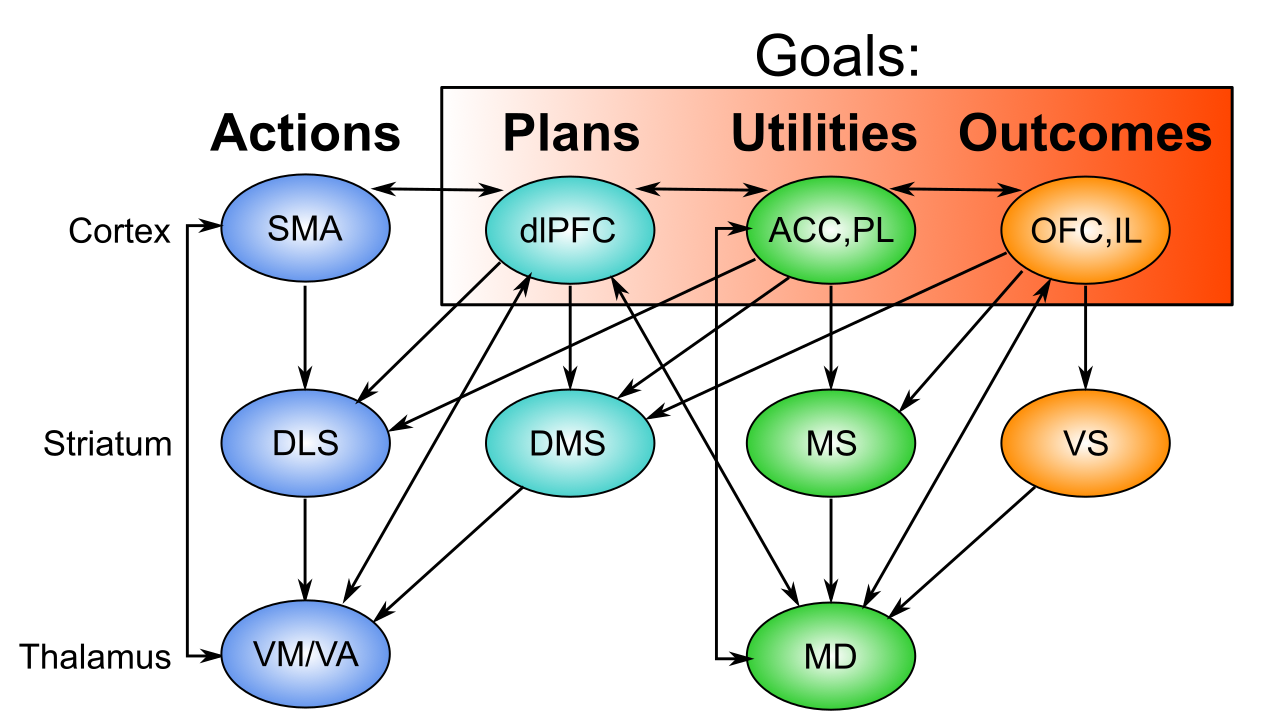
腹側および内側 [[prefrontal cortex]] (PFC) の_goal_ 状態の分散表現を [[#figure_goal-bio]] に示します。各領域は、特定の目標関連パラメーターを直接エンコードする関連する皮質下領域との双方向接続を備えており、広範囲のデータ ([[@AlexanderDeLongStrick86]]; [[@OngurPrice00]]; [[@SaddorisGallagherSchoenbaum05]]; [[@FrankClaus06]]; [[@RushworthBehrensRudebeckEtAl07]]; [[@SchoenbaumRoeschStalnakerEtAl09]]; [[@PauliHazyOReilly12]]; [[@HuntMalalasekeraBerkerEtAl17]];
-
眼窩前頭皮質 (OFC) は、生物学的および感情的に顕著な結果、つまり、条件付け理論における 無条件刺激 (US) をコード化します。 OFC がこれらの米国のような状態を維持および追跡しているというかなりの証拠があり ([[@RichWallis16]])、OFC の損傷により、これらの米国の結果の急速な変化に行動を適応させる能力が損なわれます ([[@BalleineDickinson98]])。古典的な条件付け理論と同様に、これらの米国の表現は、生物学に基づいた [[emotion needs]] を追求する動機付けシステムを基盤としています。 [[@^Hull43]] とマズローの欲求階層 ([[@Maslow43]]) にまで遡るドライブに関する広範な文献があり、OFC [[@OngurPrice00]] に収束する皮質下投影によって部分的に US の報酬価値を固定しています。 -
大脳辺縁系下皮質 (IL) は、OFC のより詳細な結果表現と比較して、US の value をより抽象的に表現します。
-
背外側 PFC (dlPFC) は、高レベルでの運動行動計画を表し、そのような計画をサポートするために他の脳領域に強い影響を与えます ([[@MillerCohen01]]; [[@Desimone96]]; [[@OReillyBraverCohen99]])。
-
前帯状皮質 (ACC) は、dlPFC を含む背側 PFC 運動野の対応する領域と広範な相互接続性を持ち、さまざまな運動計画に関連する努力や不確実性など、運動によって引き起こされるユーティリティ値をコード化します ([[@AlexanderBrown11]]; [[@ShenhavBotvinickCohen13]])。
- 前辺縁皮質 (PL) は、上記のすべての信号を全体的な utility 値に統合し、結果 (ACC から) を得るために必要なアクション プランのコストと比較した (IL からの) 結果値をエンコードします。
これらの領域は、広範な双方向接続を介して目標選択プロセス中に相互通信し、考えられる結果、計画、およびそれらの全体的な利用価値の高次元空間を通じて効率的な専用並列 [[search]] を実行する [[constraint satisfaction]] プロセスをサポートし、これらの領域のそれぞれによって課せられる制約を満たす合理的な分散目標状態に収束し、関連する環境および内部状態の入力も行います。 ([[@HerdKruegerNairEtAl21]])。
対応する大脳基底核領域は、これらの前頭領域から入力を受け取り、目標選択プロセスにおいて、現在の活動状態が良い賭けと悪い賭けを表す程度を評価することを学習し、全体的な目標表現が閾値を超えている場合、下流の視床領域の抑制を解除します。特に、視床の内側背核 (MD) 核は、これらの目標に関連する前頭野のすべてに多様な投射を持ち、これらの領域全体に分散された目標状態の強力なアクティブな維持をロックする調整されたゲート制御信号を提供できます ([[@HerdKruegerNairEtAl21]]; [[@OReillyFrank06]])。
TODO: 分散アクション表現と段階的制御信号を使用した並列 BG モーター学習により、効率的な並列検索を実行します。
TODO: 扁桃体、VS、LHb システム、PVLV、DA、ドライブなど。
認知の概要
多くの動物では、この目標達成の内部ループは、行動の発作と停止という普遍的な現象 ([[@KramerMcLaughlin01]]; [[@Shull11]]; [[@FalligantHagopianNewland24]]) に関連している可能性があり、これは、たとえば公園や裏庭にいるリスを観察することで明らかです。興味深いことに、ハトは器具による条件付け課題ではこの行動の兆候を示さないが、げっ歯類はしっかりとこの行動の兆候を示しており([[@FalligantHagopianNewland24]])、より発達した目標関連の脳システムが役割を果たしている可能性を示唆している。これと同じ特徴は人間にも明らかです。私たちは、タスクを実行しているときにどれだけ頻繁に集中力を失ったり外したりして、他のことをしている間をさまようことに多くの時間を費やしていることによく気づいていないかもしれません ([[@ShinagawaYamada25]])。