compcogneuro/web: search
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/search.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Computation”, “Activation”, “Learning”] bibfile = “ccnlab.json” +++ 検索 は、おそらく [[computation]] のすべてを統合する最も一般的な概念です。
-
問題解決 は、多くの古典的なシンボリック [[artificial intelligence]] (AI) システム ([[@NewellSimon72]]; [[@Newell90]]) のように、問題空間 を介した検索として定義できます。
-
Planning は、望ましい結果を達成するために action space を検索することであり、[[reinforcement learning#model-based]] 強化学習における多くのアプローチの焦点です。
-
Learning は、representation space を検索して、目的の計算プロセスと動作出力をサポートする、入力を表現するための最適な [[linear algebra#basis space]] を見つけます。
-
推論 は、環境の安定したセマンティクスと比較して、特定の入力刺激の最適な 解釈 を見つけるために、学習された表現を検索します。
-
Evolution は、たとえば広く使用されている [[genetic algorithm]] のように、phenotype space を通じて検索されます。
これは空のトートロジーではなく、これらすべての領域で直面する中心的な問題についての統一的な理解を提供するからです。
これらの空間はそれぞれ [[curse of dimensionality]] に悩まされており、現実世界の大規模な問題に対する効果的な解決策は、何らかの方法で指数関数的爆発の問題に取り組む必要があります。
実際、計算複雑性理論 (wikipedia) の分野では、多項式時間では解けない NP complete として知られる、幅広い問題にわたる同値クラスに基づく統一フレームワークが提供されています。 NP は、非決定的多項式 時間を意味します。これは、解は (多項式時間で) 迅速に検証できるが、実際の解の生成には、指数関数的な時間など、はるかに長い時間がかかる可能性があることを意味します。この NP 完全集合における問題はすべて「扱いにくい」とみなされ、したがって回避する必要がありますが、ベイズ推論や最適な意思決定などの認知関連の計算のほとんどは NP 困難です ([[@vanRooijWrightWareham12]])。
列挙型検索は呪われています
検索問題ドメインで使用されるアルゴリズムに、状態を介した列挙型検索 (つまり、さまざまな次元に沿って関連する値の特定の組み合わせを列挙する) の要素が含まれている場合、そのアルゴリズムは次元の呪いに悩まされる可能性が高く、状態空間が増加するにつれて指数関数的に急速に手に負えなくなります。
たとえば、そのような問題に対する最も単純な「強引な」アルゴリズムには、入れ子になった巨大なセットの for ループが含まれ、各次元に沿ってすべての値をループし、考えられる各組み合わせを列挙し、この状態ベクトルで計算された関数を評価します。このような入れ子になった for ループを経験したことがある人ならわかるように、レベルの数が増えると、これらのループはすぐに行き詰まってしまいます。
これを「シリアル検索プロセス」と呼ぶのは直感的に魅力的ですが、この列挙プロセスをラップした並列実装を使用した場合でも問題は残ります。並列処理の量に関係なく、指数関数的に増加する係数を、関係する並列ハードウェアのオーダーの固定定数で除算するだけです。たとえこれが 1,000 億個のニューロンを備えた脳だったとしても、その要因は、わずか 100 個の異なるバイナリ値次元 (例: $2^{100} / 1.0e11 \approx 1.0e19$) を持つ空間の組み合わせ爆発と比較すると、すぐに見劣りするでしょう。
さらに、シリアル コンピューター上で並列アルゴリズムを実装することは常に可能であり、実際にこれが頻繁に行われます。したがって、並列と直列に関する以下の問題は、計算の基礎となるアルゴリズム構造に関するものであり、ハードウェアでの実際の実装方法ではありません。繰り返しますが、これらのハードウェア レベルの考慮事項は、高次元の組み合わせ爆発に直面するとすぐに無関係になる一定の要因に寄与するだけです。
ニューラル ネットワークにおける多項式時間 (P) 検索
高次元空間で検索する唯一の妥当な方法は、当面の問題に関連する次元間の組み合わせの相互作用を何らかの形で十分に捕捉しながら、その組み合わせの列挙ではなく、次元値自体のレベルで直接動作するアルゴリズムを使用することです。このようなアルゴリズムの計算コストは、次元数程度の_多項式_になります。
たとえば、各単位が特定の次元の値を表すニューラル ネットワークでは、計算コストはニューロンを相互接続するシナプス重みの数の関数であり、最悪の場合は $n^2$ となり、計算コスト多項式は 2 の指数になります。このニューラル ネットワークが、脳のように重みのレベルで並列動作する専用のニューラル ハードウェアに実装されている場合、計算時間は事実上一定のままであり、これは小さなマウスの脳と巨大な人間の脳を比較するとはっきりと観察されることです。
{id=”figure_search” style=”高さ:20em”}
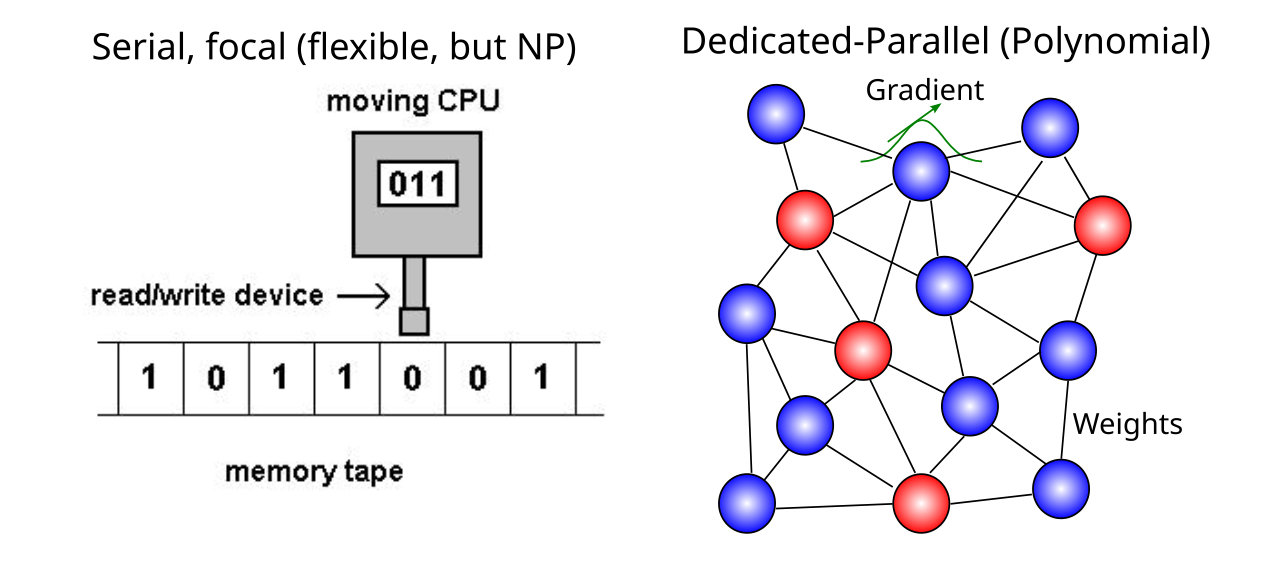
| ニューラル ネットワークは、ニューロンを相互接続するシナプスの重み ([[#figure_search]]) を介して、さまざまな値間の相互作用をキャプチャします。 [[Bidirectional connectivity | Bidirectionally-connected]] ネットワークは、時間の経過に伴う勾配ベースの更新の複数回の反復 (たとえば、[[theta rhythm]] の場合は 200 ミリ秒以上) の複合効果を利用して、分散された変数の組み合わせ間の相互作用を計算して通信することもできます。したがって、次元間のさまざまな組み合わせをすべて列挙するのではなく、これらのシナプスの重み (および反復相互作用) は、関連するすべてのものを捕捉する必要があります。完全な網羅的な列挙に比べてこれで十分であるとは信じがたいかもしれませんが、[[abstract neural network]] アルゴリズムの目覚ましい成功は、これが実際に計算の複雑さと計算能力の間のトレードオフを管理する非常に効率的で実用的な方法であることを示しています。 |
ニューラル ネットワークが適切に機能する主な理由は、それ自体が多項式的に効率的なアルゴリズムを使用して、これらのシナプスの重みをトレーニングして、関連する組み合わせ相互作用をエンコードできるためです。実際、効率的な検索の模範的な例は、[[error backpropagation]] 学習で使用される_確率的勾配降下_ プロセスです。このプロセスは、全体的な誤差関数 (objective 関数) に対するシナプス重みの 1 次 偏導関数 (つまり、gradients) を計算します。バックプロパゲーションの計算コストは、シナプス重みの数のオーダーで線形ですが、広く使用されている ChatGPT のような AI モデルを強化する [[large language models]] (LLM) を含む、さまざまなタスクを実行するニューラル ネットワークの最適化に非常に効果的であることが証明されています。
興味深いことに、多くの人が長年にわたってバックプロパゲーション アルゴリズムのようなものを使用することを検討していましたが (これは実際には初等微積分に基づく非常に標準的な勾配ベースの最適化手法にすぎません)、この単純な勾配ベースのアルゴリズムではひどく準最適な解 (つまり、局所最小値) が生成されるだけであると考えていたため、気にすることさえありませんでした。実際には、適切なヒューリスティック技術 (AdaMax メカニズム; [[@KingmaBa14]] など) とネットワーク構成を使用すれば、勾配降下法が最適な解を生成するという保証はありませんが、実用上非常に重要であるのに十分な効果があることは確かです。
「十分に優れた」ソリューション (つまり、satisficing; [[@Simon56]]) を優先して最適性制約を回避するこのヒューリスティックなアルゴリズム アプローチは、伝統的に最適なソリューションと [[Turing machine]] プログラムの実行時間を含む最悪のシナリオの観点から組み立てられてきた計算複雑性アプローチとは対照的です。したがって、誤差バックプロパゲーションの成功は、NP 完全フレームワークと、そのクラスのアルゴリズムの基本的な扱いにくさに関する中心的な仮説を損なうものではありませんが、さまざまなアルゴリズムの相対的なコストと機能を分析する、より「緩和された」方法が役立つことを示唆しています。
ニューラル ネットワークのようなアルゴリズムのより広範なカテゴリをより正確に分類するために、これらを「専用並列、勾配ベース、重み付き、適応型」アルゴリズムと呼びます。
-
専用の表現要素は、計算中に任意に組み合わせることができる個々の状態コンポーネントを柔軟に操作するのではなく、検索対象の関連する状態全体をキャプチャします。これにより、1 つのアルゴリズム並列ステップ (専用並列 計算) での「状態全体」にわたる計算がサポートされます。
-
勾配 (偏微分) は、1 つのアルゴリズム ステップで専用並列状態全体を効率的に検索するために使用されます。偏導関数は、([[error backpropagation]] アルゴリズムのように) 状態の 1 つのローカル要素に加えられた変更に関して、他のすべての状態要素の影響を自動的に計算します。また、[[GeneRec]] アルゴリズムで実証されているように、通常は再帰的に計算可能であり、ローカル並列計算をサポートします。最近のニューラル ネットワーク アルゴリズム開発の爆発的な増加は、すべて autograd 自動勾配計算フレームワークの計算効率によって推進されています。
Iterative updating via the gradients proceeds for a finite number of iterations, with the final result being sufficiently optimized within some reasonable threshold. This forecloses the worst-case search scenario of exponential iterations.
-
段階的な重み付け係数は、表現要素間の関係をキャプチャするために使用されるため、専用並列の勾配ベースの計算と互換性があります。これは、システムが表現できる組み合わせ論の性質に強い制約を課し、組み合わせ爆発を非常に低い次数 (例: $n^2$) に切り捨てるものです。
Much of the exploratory engineering in designing a neural network model involves configuring the topology of these weighted connections to capture the relevant interactions, which represents a kind of outer-loop of hyperparameter searching, so the computational cost of this should not be overlooked. From a biological perspective, this is what evolution does (see below).
-
これらの重み付け係数は、専用の表現空間を最適化するために (効率的な勾配ベースのメカニズムを使用して) 調整され、状態変数 (つまり、学習) 全体の関連関係を適切に捕捉します。一度学習すると、専用並列ネットワークを介した情報の効率的な伝播により、関連する状態の相互作用が自動的に表現され、推論、問題解決、計画などの機能がサポートされます。
[[abstract neural network]] モデルのプロパティを一般化するこの試みは、[[@RumelhartMcClelland86]] の元の並列分散処理 (PDP) 用語に似ています。このような有用なアルゴリズムのクラスを既存のニューラル ネットワーク アルゴリズムを超えて有意義に拡張するかどうかは不明ですが、おそらく、これらのネットワークのアルゴリズム特性を他のシステムと比較してより明確に描写するのに役立つでしょう。
検索としての学習
表現空間を通じて効率的な多項式時間検索を実装するニューラル ネットワーク モデルの機能は、おそらく、ニューラル ネットワーク モデルと古典的なシンボリック AI モデルとの間の最大の違いを表しています。モデルが本質的にさまざまな AI ベースのアフォーダンスを備えた [[Turing machine]] である古典的な AI フレームワークの離散的シンボリックな性質は、勾配ベースのシナプス媒介学習メカニズムと互換性がありません。したがって、そのようなモデルで学習しようとすると、最終的には列挙的な組み合わせ検索が必要になり、組み合わせ爆発に直面して失敗します。繰り返しますが、これは、基礎となるアルゴリズムの特性であるため、並列ハードウェアを使用できる場合でも当てはまります。
現在、確率的勾配降下法が信じられないほどうまく機能する理由を解明する文献が増えています (例: [[@NakkiranKaplunBansalEtAl21]]; [[@Shwartz-ZivTishby17]]; [[@VidalBrunaGiryesEtAl17]])。 確率的勾配降下法プロセスの「確率的」な性質は、その成功に不可欠であり、検索プロセスにおけるノイズの広範な重要性と一致しており、興味深い [[emergent]] プロセスです。外部から注入されるものではなく、勾配を計算するために問題空間全体の小さなサブサンプルを使用することから派生します。勾配の計算に全空間を使用すると、この空間全体に課せられたすべての制約によって「妨げられ」、通常は学習が成功しません。
検索としての制約満足度
[[Constraint satisfaction]] は、広範囲の計算プロセスを理解するためのもう 1 つの高レベルの統一された方法を提供します。この一般性は、現在の検索ベースの観点からは偶然ではありません。制約満足とは、事実上、一連の制約を解決または最適化する (ほぼ!) 可能な状態の検索です。計画や問題解決を含め、多くの問題はこの方法で定式化できるため、制約を満たすことで、これらの領域の重要な計算を理解するためのより一般的な方法が提供されます。
制約を満たすための確率的勾配ベースのアプローチは、多項式の時間計算量を持ち、一般に極小問題 ([[@HoosTsang06]]) に悩まされないため、高次元の状態空間に効率的に拡張できます。このようなアルゴリズムの 1 つのクラスは、実際にはニューラル ネットワークです。[[@HopfieldTank85]] の先駆的なアプローチに遡ります。[[@HopfieldTank85]] は、双方向接続されたホップフィールド ネットワークの反復更新が、制約充足領域の古典的な例である巡回セールスマン問題に優れた解決策を提供できることを示しました。外部ノイズは制約充足アルゴリズムでよく使用されますが、スパイク ニューラル ネットワークは当然、十分な緊急ノイズを示します。
| 興味深いことに、誤差逆伝播学習における確率的勾配降下プロセスは、制約充足に適用されるのと同じプロセスに直接関連しており、再帰型 ([[bidirectional connectivity | bidirectionally-connected]]) ネットワーク ([[@Almeida87]]; [[@Pineda88]]) における反復 [[error backpropagation#backpropagation to activations]] として理解できます。これは当然、双方向接続された [[Axon]] フレームワークで実現され、[[error backpropagation]] への [[GeneRec]] 近似のバージョンも実装されます。 |
したがって、軸索ネットワークは制約充足プロセスの結果を反映する [[optimized representations]] を継続的に生成し、したがって活性化空間で動的に表現空間を介した検索を同時に実行し、シナプス重み調整を介した学習の過程で実行します。
緊急シリアル処理
チューリングマシンのようなシリアルなシンボリック処理は高次元空間の検索には向いていませんが、シリアルなシンボリック計算ははるかに柔軟です。シリアル プロセスでは、次元の任意の「組み合わせ」をケースごとに異なる方法で処理できるためです。シリアル処理のこの重要な利点は、[[Turing machine]] が汎用計算デバイスであるのに対し、並列分散計算は一般にそうではなく、代わりに特定の問題に (学習プロセスなどを介して) 適応させる必要がある理由です。
したがって、専用並列の勾配ベースの処理とシリアル処理を組み合わせる最も効果的な方法は、現実世界の高次元の性質に取り組み、状況の低次元で抽象化された概要を生成する前者の基盤を用意することです。そして、創発的なチューリングマシンのようなシリアルプロセスが、結果として生じる低次元の抽象空間上で動作し、より柔軟なシリアル処理をサポートすることができます。
私たちは、この全体的な構成が知的行動に不可欠であり、人間の認知の多くの側面について説得力のある説明を提供すると信じています。 AI に対するシンボリック アプローチと「サブシンボリック」アプローチの間の長年の議論に関して、これはこの 2 つの統合を表しており、基本的にサブシンボリックなニューラル ネットワーク ハードウェアからシンボリック処理が出現します ([[@AndersonLebiere98]]; [[@JilkLebiereOReillyEtAl08]])。
興味深いことに、[[large language models]] もこれと同じ全体構成を持っています。これは、[[large language models]] がコンピューター プログラムの動作を予測するために広範に訓練されており、本質的にチューリング マシン ([[@YangCampbellHuangEtAl25]]) のように動作することを学習しているためです。実際、研究では、標準トレーニング コーパスのコンピューター プログラミングの側面を除外すると、結果として得られるシステム全体の認知的柔軟性に大きな影響を与えることが示されています。
表現の問題
[[distributed representations]] の性質には、専用並列の勾配ベースのニューラル ネットワーク アルゴリズムの有効性に関連する重要な意味があります。特に、[[combinatorial vs conjunctive]] 表現間の違いは重要です。 combinatorial 表現には、関連する各次元を独立して表す個別の表現単位 (例: それぞれの個別の色とそれぞれの個別の形状) がありますが、conjunctive 表現は、これらの次元にわたる特定の組み合わせをエンコードします。各接続詞の組み合わせが個別に表現される完全な組み合わせ爆発は、混合選択性 ([[@FusiMillerRigotti16]]; [[@OReillyBusbySoto03]]) として知られる接続詞の高次元空間全体にわたる段階的分散表現を使用することで回避できることに注意してください。
{id=”figure_binding-problem” style=”高さ:20em”}
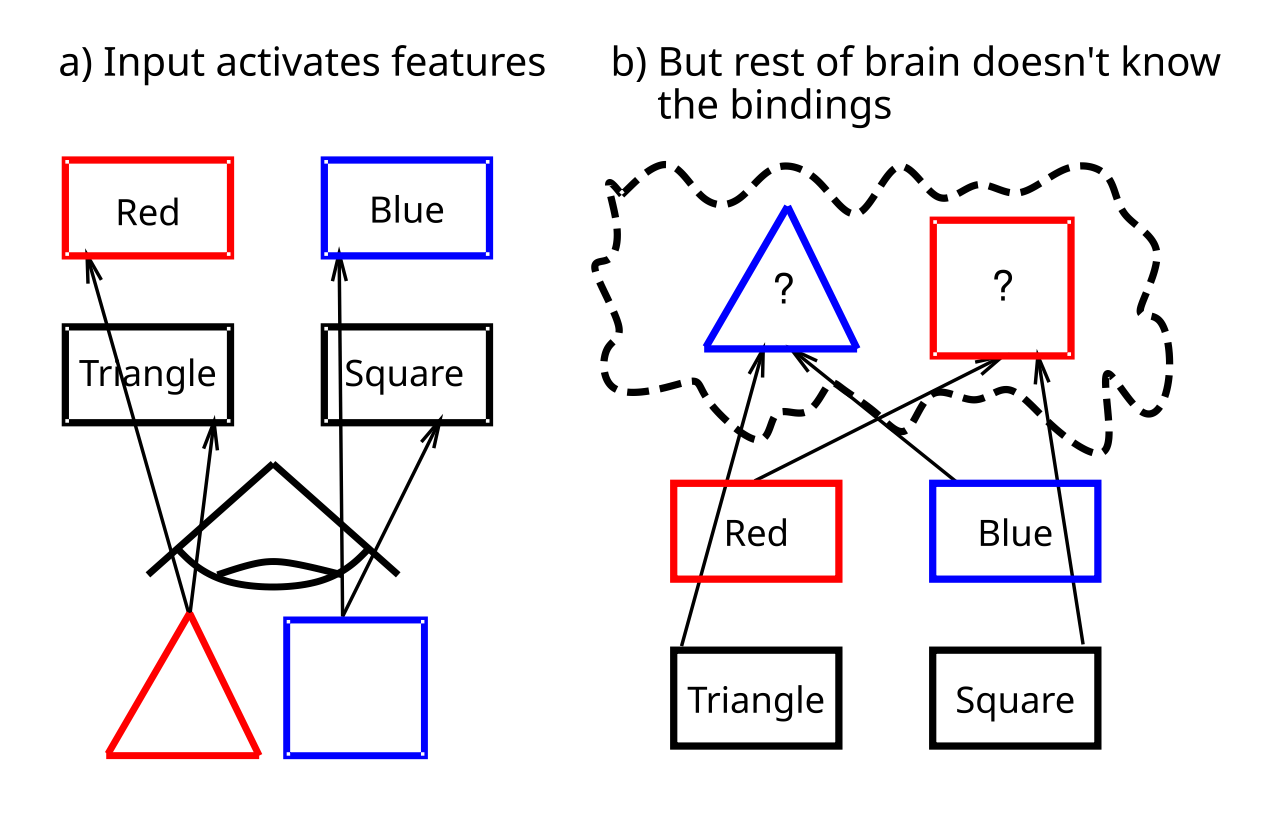
純粋に組み合わせ表現では、特徴の異なる固有の組み合わせを同時に表現することが困難になります (例: 青い四角と赤い三角形、青い三角形と赤い四角、[[#figure_binding-problem]])。これにより、これらの表現を直接操作するアルゴリズムに問題が発生します。対照的に、結合表現は、特徴のさまざまな組み合わせを「バインド」するため、そのような表現の要素に対する操作は、これらのさまざまな組み合わせに敏感になる可能性があります。
これらの表現上の問題は、検索表示プロパティに応じて並列プロセスと直列プロセスの両方を使用すると説明されているビジュアル検索のコンテキストでのバインディング問題の場合にうまく説明されています。たとえば、人々は、色や方向などの基本的な視覚的特徴を効率的に並行して検索できます。これらの特徴は、たとえば、緑の気を散らすもののコレクションの中から赤いターゲットを探すときに、自動的かつ迅速に「飛び出す」ことができます。ターゲットとディストラクタはそのような特徴のより複雑な組み合わせを持っているため、探索空間を狭めるためにますます連続した空間 [[attention]] が使用されます ([[@Treisman77]]; [[@Wolfe10]]; [[@HerdOReilly05]])。
ベイジアン モデルと検索
広く研究されている認知のベイジアン モデル ([[@TenenbaumKempGriffithsEtAl11]]; [[@ChaterOaksfordHahnEtAl10]]) は、一般に完全な組み合わせ列挙を必要とする確率分布に基づいているため、次元性の呪いにしばしば悩まされます。たとえば、各変数が統計的に独立している、または他の変数から相互に排他的であるなど、特定の強力な単純化仮定を立てることができます。しかし、これらは形式主義の表現力を過度に損なう傾向があります。対照的に、ニューラル ネットワークの学習されたシナプス重みは、効率的な計算をサポートしながら、変数間の関係を捉えるはるかに優れた能力を提供し、それによってトレードオフ空間における一種のスイート スポットを表します。
高次元の確率空間を介した逐次探索の並列スレッドを使用するために、粒子フィルター ([[@DoucetFreitasGordon01]]) または MCMC (マルコフ連鎖モンテカルロ) サンプリング ([[@Neal93]]) メソッドを最適化する試みがかなり行われてきました。ただし、これらのメソッドの逐次的な性質により、空間の次元が増加するにつれて、シリアル検索に予想される制限が課せられます ([[@Sanborn17]]; [[@GershmanBeck17]])。
これらの理由から、多大な努力とある程度の進歩にもかかわらず、大規模なベイジアン モデル ([[@ZhuChenHuEtAl17]]) の実践例はありません。代わりに、それらは不確実性の下で推論がどのように機能するかについての重要な原則を実証する小規模なモデルになる傾向があります。離散スパイキング ニューロンの動作との興味深い潜在的な関連性がいくつかあり ([[@GershmanBeck17]]、[[@PougetBeckMaEtAl13]]、[[@McKeeCrandellChaudhuriEtAl22]])、これは、これらのより抽象的なモデルを、高次元空間にスケールするより並列的な基礎となるニューラル メカニズムと接続する方法を示唆しています。
進化における勾配
自然界における [[Evolution]] には、「複製された」生物全体にわたる大規模な並行検索が含まれ、それぞれが並行して生活を送っていますが、そのような各生物の存在論的発達は連続的であるため、個体間で蓄積される共有ゲノム プログラムの表現にかなりの柔軟性が与えられます。ただし、生涯にわたるこの一連の試行錯誤の探求は、[[reinforcement learning]] にとって特別な課題を生み出します。
進化は DNA にコード化された発生プログラムに基づいて行われるため、この発生プロセスの性質は進化の探索プロセスの効率を形作る上で重要な役割を果たします。発達プログラムが、漸進的な段階的探索を可能にする段階的かつ勾配ベースのプロセスを伴う限り(例えば、手足をわずかに長くしたり短くしたり、葉をわずかに大きくしたりするなど)、進化は網羅的で列挙的な探索プロセスよりも効率的になる可能性があります。これは、進化が手に負えない NP 完全探索プロセスであるという議論 (例: [[@RichBlokpoeldeHaanEtAl21]]) と矛盾します。
それにもかかわらず、地球上の進化プロセスの気が遠くなるような「計算能力」でさえ、比較的低次元のシステム(たとえば、$2^{100} \approx 1.0e30$、10億年で割っても依然として非常に大きい)の組み合わせ爆発によって簡単に小さくなってしまう可能性があることを認識することが重要です。
これまで進化が実際にどのように進行したかを遡及的に見ると、個々の細胞から多数の細胞で構成される生物への進化は、脳内の処理を多数の異なる神経処理要素間の相互作用を中心に組織化することにより、その性質に重要なバイアスを与えました。これは当然、専用の並列多項式時間処理アルゴリズムに有利であり、偶然にも、生物が解決しなければならない計算問題の全範囲に対して効率的な解決策を提供するように見えます。
驚くべきことに、進化の過程は約 5 億年前の脊椎動物の体と脳の設計図 (bauplan) にも定着しており、これは驚くほど耐久性と適応性があることが証明されています。人間の脳は、有顎魚で出現したのと同じ設計図に従って構造化されており、[[basal ganglia]]、[[cerebellum]]、および [[hypthalamus]] を含む多くの重要な脳領域の同じ中核機能がすべて揃っています。これらの脳システムは、約 2 億年前から始まる哺乳類に特有の [[neocortex]] に適応して統合されており、私たちの高次の認知機能に不可欠です。したがって、どういうわけか、進化的探索プロセスは、機能するニューラル アルゴリズムを見つけるのに効率的だったようです。