compcogneuro/web: d = 配列(out)
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/temporal-derivative.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Learning”] bibfile = “ccnlab.json” +++ 時間導関数 はニューロンの活動状態の時間変化であり、[[GeneRec]] の数学的枠組みに基づいて、[[kinase algorithm]] を経由して [[Axon]] に至る [[error-driven learning]] の中心的なメカニズムです。 [[predictive learning]] のコンテキストでは、時間を 2 つの異なるフェーズに離散化できます ([[Boltzmann machine]] で最初に開発されたように)。
{id=”figure_minus-plus” style=”高さ:20em”}
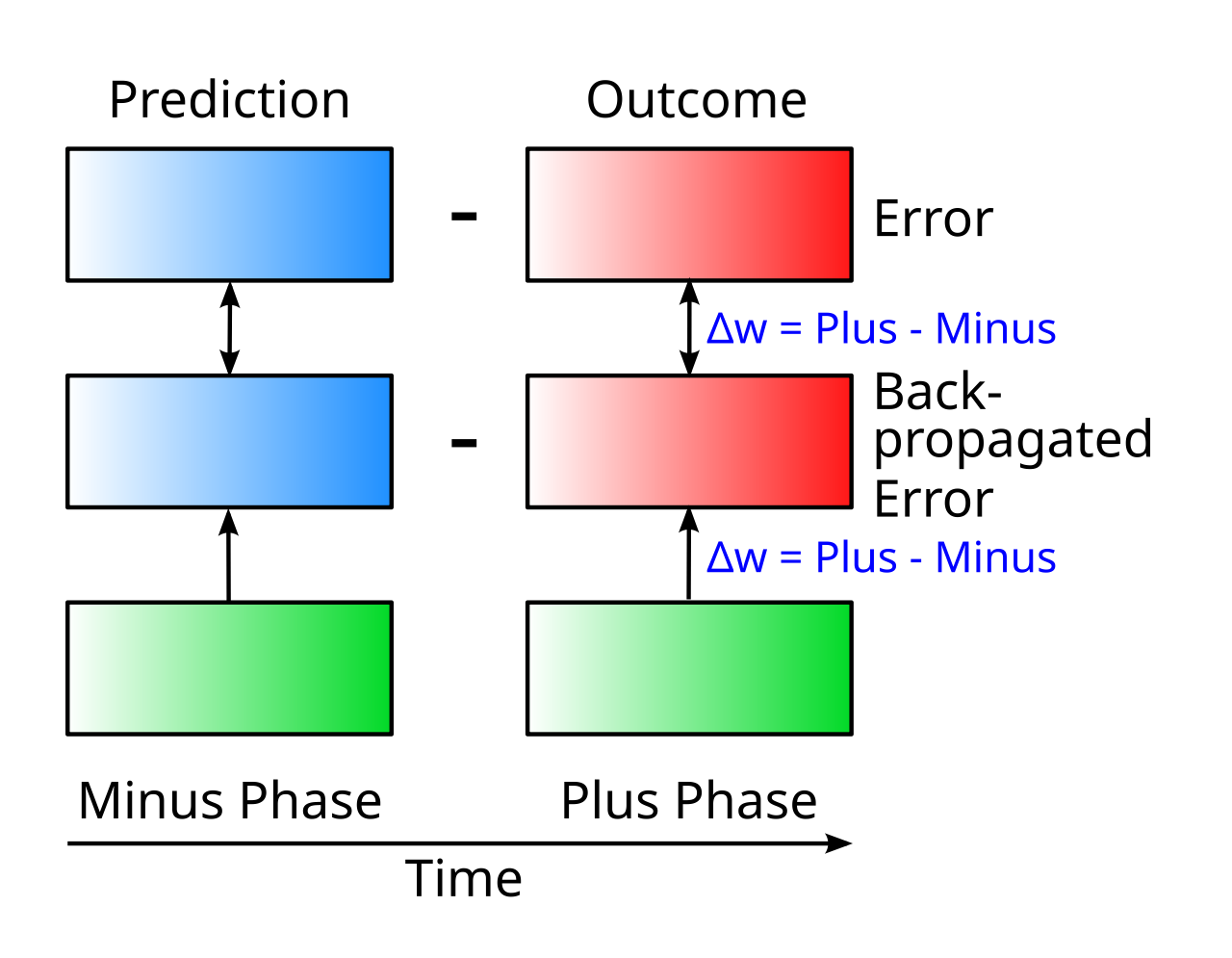
- マイナスフェーズは、ネットワークが予測を生成しているときです。
- プラスフェーズは、ネットワークが実際の結果 (実際に起こったこと) を経験しているときです。
時間導関数は、これら 2 つのフェーズ間の「差」、つまり 予測誤差 であり、ネットワーク内のすべてのニューロンはこの差の関数として学習します。
- $\propto$ (プラス - マイナス) の学習
単純な方程式形式では、シナプス重みの変化 $w$ は、プラス相 ($y^+$) とマイナス相 ($y^-$) の間の活動状態の位相方向の差 $y$ の関数です。
{id=”eq_td” title=”時間差学習”} \(\Delta w \propto y^+ - y^-\)
対照的に、標準的な [[error backpropagation]] 学習では、エラー信号は、生物学的不信感の主な原因である活性化伝播を支配する方程式とは異なる方程式を使用し、構造的に別個の経路を介して伝播されます。
時間導関数の主な利点は、「時間はネットワーク内のあらゆる場所で発生する」ため、エラー信号が時間の経過とともに脳内のニューロンのネットワーク内のすべての領域に広がることができることです。対照的に、異なる解剖学的経路間で計算される導関数では、これらの経路がネットワーク内で少なくともある程度分離および組織化された状態を維持する必要があり、これにより通常、計算できるエラー信号の種類が強く制限されることになります。
したがって、時間導関数は非常に堅牢な汎用メカニズムであり、生物学の複雑で有機的な世界に特に適していると考えられます。実際、このメカニズムの初期の経験的サポートは [[Jang et al (2026)]] で報告されています ([[OReilly (2026) Cortical Learning]] も参照)。 [[neocortex]] の外側では、[[reinforcement learning]] の TD (時間差) アルゴリズムは同じ時間予測誤差フレームワークを共有しますが、[[dopamine]] の形式で非常に異なる神経基板にマッピングされます。
時間導関数のローカル計算
時間導関数のもう 1 つの魅力的な特性は、異なる [[exponential integration]] 時定数を持つ 2 つの化学プロセス間の競合を通じて、各ニューロンとシナプスでローカルに計算できることです。具体的には、「速い」プロセスから「遅い」プロセスを減算すると、時間微分が自動的に計算されます。
これは、次の簡単なシミュレーションで示されています。このシミュレーションでは、高速化学プロセスと低速化学プロセスを駆動する「ドライバー」入力に対する応答が示されています (オンライン [[exponential integration]] を使用)。脳では、このドライバーはシナプス前およびシナプス後のスパイクの形での神経活動であり、主に カルシウム イオンの流入によって駆動される一連の化学経路によって統合されます (詳細については、[[synaptic plasticity]] および [[kinase algorithm]] を参照)。
ドライバー入力は、[[predictive learning]] と一致する方法で時間の経過とともに変化します。最初の prediction 値があり、その後に outcome 値 ([[#figure_minus-plus]]) が続きます。予測は、次に何が起こるかを予測するときに存在する脳の状態に関連付けられた局所的な神経活動であり、結果は、予測を行った直後に実際の結果を経験したときの局所的な神経活動です。
予測誤差は、予測と結果のシーケンスが完了したときの、時間ウィンドウの終わりにおける高速トレースと低速トレースの差によって表されます。この差が正の場合、それは正の値の誤差勾配を反映しており、シナプスの重みもそれに応じて増加するはずです ([[synaptic plasticity]] の文献では LTP として知られています)。同様に、負の場合、シナプスの重みは減少するはずです (LTD)。
{id=”sim_td” title=”高速 - 低速からの時間導関数” Collapsed=”true”} 「ゴール」 fastTau := 20.0 // 高速積分の時定数 lowTau := 40.0 // 低速積分の時定数 プレド:= 50.0 アウト:= 80.0 var dwtStr、fastStr、slowStr、predStr、outStr 文字列
## 合計時間 := 200 driver := zeros(totalTime) // ドライバーはシステムを駆動するものです fast := zeros(totalTime) // fast はドライバーの高速インテグレータです low := zeros(totalTime) // low はドライバーの遅いインテグレータです ##
関数 td() { fastStr = fmt.Sprintf(“高速タウ: %g”, fastTau) throwStr = fmt.Sprintf(“遅いタウ: %g”, 遅いタウ) predStr = fmt.Sprintf(“予測: %g”, pred) outStr = fmt.Sprintf(“結果: %g”, out) ## d := array(pred) // 現在のドライブ f := 0.0 // 現在の高速 s := 0.0 // 現在遅い fTau := 配列(fastTau) sTau := 配列(slowTau) ## for t := 範囲 200 { if t == 150 { # d = 配列(out) } ## f += (1.0 / fTau) * (d - f) // f は d に向かって移動します s += (1.0 / sTau) * (d - s) // s は f に向かって移動します ドライバー[t] = d 速い[t] = f 遅い[t] = s ## } ## dwt := 速い[-1] - 遅い[-1] ## dwtStr = fmt.Sprintf(“重みの変化 ΔW ≅ 予測 - 結果 = 速い - 遅い = %7.2g”, dwt.Float1D(0)) }
td()
プロットスタイル := func(s *plot.Style) { s.Range.SetMax(100).SetMin(0) s.Plot.XAxis.Label = “時間” s.Plot.XAxis.Range.SetMax(200).SetMin(0) s.Plot.Legend.Position.Left = true } プロット.SetStyler(ドライバー, プロットスタイラー)
fig1, pw := lab.NewPlotWidget(b) dl := プロット.NewLine(fig1, ドライバー) fl := プロット.NewLine(fig1, 高速) sl := プロット.NewLine(fig1, 遅い) fig1.Legend.Add(“ドライバー”, dl) fig1.Legend.Add(“高速”, fl) fig1.Legend.Add(“遅い”, sl)
dwtTx := core.NewText(b) dwtTx.Styler(func(s *styles.Style) { s.Min.X.Ch(80) // 可変幅コンテンツによるクリーンなレンダリング }) core.Bind(&dwtStr, dwtTx)
関数 updt() { td() dl.SetData(ドライバー) fl.SetData(高速) sl.SetData(遅い) dwtTx.UpdateRender() pw.NeedsRender() }
func addSlider(label *string, val *float64, mxVal float32) { tx := core.NewText(b) tx.Styler(func(s *styles.Style) { s.Min.X.Ch(40) // 可変幅コンテンツによるクリーンなレンダリング }) core.Bind(ラベル、tx) sld := core.NewSlider(b).SetMin(1).SetMax(mxVal).SetStep(1).SetEnforceStep(true) sld.SendChangeOnInput() sld.OnChange(func(e events.Event) { updt() tx.UpdateRender() }) core.Bind(val, sld) }
addSlider(&predStr, &pred, 100) addSlider(&outStr, &out, 100) addSlider(&fastStr, &fastTau, 100) addSlider(&slowStr, &slowTau, 100) 「」
このシミュレーションのコードは、単純な移動平均更新式に従って、高速変数と低速変数を更新します (例: $fast$ 変数)。
{id=”eq_fast-slow”} \(\rm{高速} += \frac{1}{\rm{高速タウ}} (\rm{ドライバー} - \rm{高速})\)
この方程式により、変数 (高速または低速) が「タウ」時定数係数によって決定される速度でドライバー値に向かって移動します。たとえば、ドライバーが fast よりも大きい場合、$driver - fast$ は正になるため、fast はドライバーの値に近づくように増加します。 $fastTau = 10$ の場合、更新ごとにドライバーに向かって 10 分の 1 移動します (fastTau ステップでドライバーまでの約 2/3 に到達します)。この非常に単純なタイプの更新方程式は [[axon]] 全体で使用されており、生物学でも同様に非常に普及しています。
試してみることができるいくつかのこと:
-
PredictionとOutcomeの両方を同じ量だけ増減します。Fast - Slow間の競合減算ロジックにより、重みの変化は relative 差にのみ影響されることに注意してください。 -
PredictionとOutcomeの両方を同じ値 (例: 50) に設定し、これにより重みの変化が zero になることを観察します。これは、結果に対する予測に誤差がないことと一致します。これは、生の値を大幅に増減した場合 (例: 両方 20、または両方 80) であっても当てはまります。これは、一般にアクティビティの全体的なレベルによって駆動される [[hebbian learninghebbian]] 形式の学習とは対照的な重要な点であり、アクティビティが増えると (より大きな) ウェイトの増加が期待されます。 -
Tau係数にも重要な制約があります。たとえば、PredictionとOutcomeが両方とも 50 の場合、Slow Tauを 70 まで増やします。予測誤差がないにもかかわらず、重みの変化がプラスになっていることがわかります。これは、Slow 係数が遅すぎて最後に追いつくことができないためです。これは、これらのTau因子を生成する局所化学速度定数が、ネットワーク レベルのエラー信号の実際の時間的ダイナミクスに合わせて適切に調整される必要があることを意味します。Although this might be considered biologically implausible, in fact there is strong evidence of prominent [[oscillatory rhythms]] in the brain at different characteristic frequencies, including the [[alpha cycle]] at roughly 10 Hz (100 ms period) and the [[theta rhythm theta cycle]] at roughly 5 Hz (200 ms period). These rhythms have been shown to strongly influence learning, in a manner consistent with this simple model and the [[kinase algorithm]] more generally.
要約すると、2 つの単純な指数積分方程式 ([[#eq_fast-slow]]) 間の競合に基づく [[#sim_td]] は、ローカルで計算された時間導関数が、時間の経過とともに現れるエラー信号と一致する方法でシナプス変化を駆動できることを示しています。
学習のタイミング
この時間導関数フレームワークの重大な問題は、予測誤差信号の正確な計算が実際の結果の開始後のある時点で行われなければならないことです。たとえば、学習がマイナス (予測) フェーズ中に発生した場合、予測状態に向かって学習し、前の結果状態からは離れて学習します。
さらに、タイミングは、高速コンポーネントが低速コンポーネントから逸脱するのに十分な時間を確保する必要がありますが、遅すぎるコンポーネントが追いつくにつれて差がなくなり始めるため、あまり時間をかけすぎないようにする必要があります。多くの Axon シミュレーションでは、簡素化のために入力は一定の間隔で提示され、学習タイミングはアルゴリズムによって制御できます。しかし、実際に脳内でどのように機能するのでしょうか?
以下のシミュレーションに示すように、個々のニューロンで利用できる信頼性の高いタイミング信号があり、これが生物学的シナプス可塑性プロセスを潜在的に駆動する可能性があります。この信号は、fast と slow の差の絶対値が時間の経過とともに変化する様子に基づいており、diff としてプロットされます。
{id=”sim_diff” title=”学習のタイミング” Collapsed=”true”} 「ゴール」 fastTau := 20.0 // 高速積分の時定数 lowTau := 40.0 // 低速積分の時定数 プレド:= 50.0 アウト:= 80.0 var dwtStr、fastStr、slowStr、predStr、outStr 文字列
## 合計時間 := 200 driver := zeros(totalTime) // ドライバーはシステムを駆動するものです fast := zeros(totalTime) // fast はドライバーの高速インテグレータです low := zeros(totalTime) // low はドライバーの遅いインテグレータです diff := zeros(totalTime) // diff は高速の差分と低速の差分の絶対値です ##
関数 td() { fastStr = fmt.Sprintf(“高速タウ: %g”, fastTau) throwStr = fmt.Sprintf(“遅いタウ: %g”, 遅いタウ) predStr = fmt.Sprintf(“予測: %g”, pred) outStr = fmt.Sprintf(“結果: %g”, out) ## d := array(pred) // 現在のドライブ f := 0.0 // 現在の高速 s := 0.0 // 現在遅い fTau := 配列(fastTau) sTau := 配列(slowTau) ## for t := 範囲 200 { if t == 150 { # d = 配列(out) } ## f += (1.0 / fTau) * (d - f) // f は d に向かって移動します s += (1.0 / sTau) * (d - s) // s は f に向かって移動します ドライバー[t] = d 速い[t] = f 遅い[t] = s diff[t] = abs(s-f) ## } ## dwt := 速い[-1] - 遅い[-1] ## dwtStr = fmt.Sprintf(“重みの変化 ΔW ≅ 予測 - 結果 = 速い - 遅い = %7.2g”, dwt.Float1D(0)) }
td()
プロットスタイル := func(s *plot.Style) { s.Range.SetMax(100).SetMin(0) s.Plot.XAxis.Label = “時間” s.Plot.XAxis.Range.SetMax(200).SetMin(0) s.Plot.Legend.Position.Left = true } プロット.SetStyler(ドライバー, プロットスタイラー)
fig1, pw := lab.NewPlotWidget(b) dl := プロット.NewLine(fig1, ドライバー) fl := プロット.NewLine(fig1, 高速) sl := プロット.NewLine(fig1, 遅い) dfl := プロット.NewLine(fig1, diff) fig1.Legend.Add(“ドライバー”, dl) fig1.Legend.Add(“高速”, fl) fig1.Legend.Add(“遅い”, sl) fig1.Legend.Add(“Diff”, dfl)
dwtTx := core.NewText(b) dwtTx.Styler(func(s *styles.Style) { s.Min.X.Ch(80) // 可変幅コンテンツによるクリーンなレンダリング }) core.Bind(&dwtStr, dwtTx)
関数 updt() { td() dl.SetData(ドライバー) fl.SetData(高速) sl.SetData(遅い) dfl.SetData(diff) dwtTx.UpdateRender() pw.NeedsRender() }
func addSlider(label *string, val *float64, mxVal float32) { tx := core.NewText(b) tx.Styler(func(s *styles.Style) { s.Min.X.Ch(40) // 可変幅コンテンツによるクリーンなレンダリング }) core.Bind(ラベル、tx) sld := core.NewSlider(b).SetMin(1).SetMax(mxVal).SetStep(1).SetEnforceStep(true) sld.SendChangeOnInput() sld.OnChange(func(e events.Event) { updt() tx.UpdateRender() }) core.Bind(val, sld) }
addSlider(&predStr, &pred, 100) addSlider(&outStr, &out, 100) addSlider(&fastStr, &fastTau, 100) addSlider(&slowStr, &slowTau, 100) 「」
予測と結果ドライバーの状態のさまざまな組み合わせにわたって、diff 値は 2 つの異なるピークを示していることがわかります。1 つは予測フェーズのアクティビティの開始によって fast と slow が異なる速度で変化するときの開始時で、もう 1 つは結果 (プラス) フェーズの開始直後です。一般に、最初のピークは実際にははるかに大きく信頼性が高く、全体的な感覚またはネットワークの内部 (隠れた) 状態の変化を反映していますが、2 番目のピークは予測と結果の差に比例します。
たとえば霊長類では、事象関連電位 (ERP) ([[@HelfrichKnight19]]) として知られるサッカード後の神経活動の特徴的な波についての確固たる証拠があり、モードサッカード固視は約 200 ms にしっかりと集中しています ([[@DevillezGuyaderCurranEtAl20]])。さらに、新皮質と相互接続する高次の [[thalamus]] 領域 (すなわち、肺動脈および背背側) は、注意力と行動に重大な影響を与える強力なシータリズム (5 Hz、200 ミリ秒) の固有振動を駆動します ([[@FiebelkornKastner19]]; [[@FiebelkornKastner21]])。
げっ歯類では、シータ周期(これも 200 ms 周期)での神経活動の脳全体の同調の証拠があり([[@SattlerWehr25]])、相対的な安定性とその間の急激な移行を伴う期間(つまり、メタ安定性、[[@LaCameraFontaniniMazzucato19]]、[[@RecanatesiPereira-ObilinovicMurakamiEtAl22]])を特徴とする全体的な皮質全体の神経活動の強い証拠があります。これらの相転移は部分的には運動事象によって駆動されるようであり、[[motor]] および [[prefrontal cortex]] 入力を受け取る VA (腹側前部) 視床の皮質全体にわたる広範な接続性と一致しています ([[thalamus#frontal thalamus]] を参照)。
私たちのモデルでは、最初のピークの開始から一定のサイクル数 (ミリ秒) 後に学習のタイミングを制御することが、実際にはうまく機能することがわかりました。スパイキング ネットワーク (例、軸索の [[kinase algorithm]]) では、学習を促進する時間積分値は [[#sim_diff]] ほど滑らかではありません。これは、シナプス後スパイキングによる大きな寄与があるためです。ただし、他の多数のニューロンからサンプリングした、各ニューロンに入る総興奮性コンダクタンスと抑制性コンダクタンスの合計では、より滑らかな値が得られます。この場合も同じピーク駆動ロジックがうまく機能し、[[kinase algorithm]] で使用されます。