compcogneuro/web: transformer
このページは外部資料の日本語訳です。原文の見出し順と本文順を保ち、コード・URL・出典表記はできるだけ原形のまま残しています。
出典とライセンス
原典: https://github.com/compcogneuro/web/blob/main/content/transformer.md
ライセンス: Text: CC BY 4.0; code: BSD 3-Clause。このページは日本語翻訳であり、変更点は翻訳とサイト内整形です。
+++ Categories = [“Learning”, “Activation”, “Computation”] bibfile = “ccnlab.json” +++ Google ([[@VaswaniShazeerParmarEtAl17]]) の研究者によって開発された transformer アーキテクチャは、[[large language models]] (LLM) を強化し、self-attention と高次元の_feedforward network_ (FFN) (つまり、標準 [[error-backpropagation]]) という 2 つの異なるメカニズムを含んでいます。いわば、attention コンポーネントはすべての [[attention]] を取得しますが、LLM ([[@NandaRajamanoharanKramarEtAl23]]) で明らかなように、明らかに FFN コンポーネントがこのアーキテクチャのかなりの記憶能力を担っています。トランスフォーマーは、ResNet (残留ネットワーク) [[@HeZhangRenEtAl15]] および正規化メカニズムを含む、他の広く採用されている多数の [[abstract neural network]] メカニズムにも依存します。
トランスフォーマーのメカニズムには神経科学との直接的な関連性がありそうもないという事実にもかかわらず、これは、人間のようなレベルでかなりのレベルの体系的で生成的な [[generalization]] を達成する、ニューロンのような処理メカニズムに基づく人工システムの既知の唯一の実用例を提供するため、[[Axon]] プロジェクト、および [[computational cognitive neuroscience]] をより広く理解するあらゆる試みにとって非常に重要です。 ([[@YangCampbellHuangEtAl25]]; [[@McGrathRussinPavlickEtAl24]]; [[@McClellandHillRudolphEtAl20]])。基本的なメカニズムを説明した後、これらのメカニズムがこの素晴らしい偉業をどのように達成するかを理解することで何が学べるかを考えます。
概要レベルでは、セルフ アテンションと ResNet アーキテクチャによって可能になる構造依存型処理と、フィードフォワード ネットワーク内の [[neocortex]] と [[hippocampus]] の両方の機能を組み合わせた強力なメモリ システムの組み合わせを通じて実現されます。したがって、変換は単なる各部分の合計ではありません。これらのコンポーネントは相乗的に連携して、複雑な [[emergent]] ダイナミクス ([[@ElhageNandaOlssonEtAl21]]) をサポートします。
自分自身への注意
{id=”figure_transformer-attn” style=”高さ:20em”}
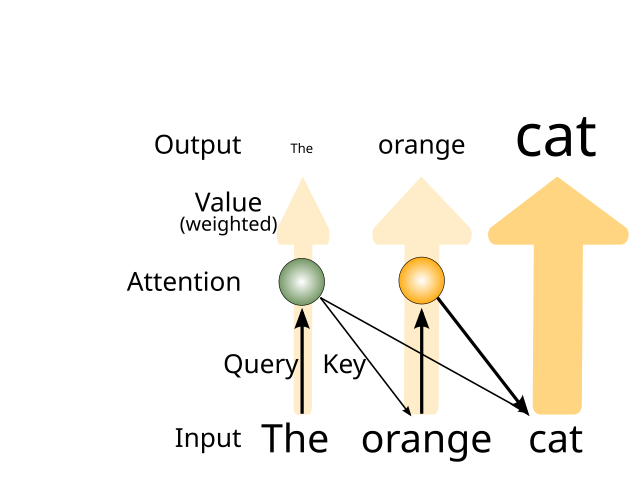
| アテンションのメカニズムは [[#figure_transformer-attn]] に示されています。これは、他の各単語の Key 値と (ドット積、つまり [[linear algebra | matrix multiplication]] によって) 比較される Query として機能する入力トークンごとに計算されます。クエリとキーとしてのトークンの表現は、個別にトレーニングされた重み (ネットワーク全体を通じた誤差逆伝播を介して) によって決定されます。これにより、各トークンから何を抽出するか、およびキーとして他のトークンとどのように照合しようとするかに関して、注意をある程度柔軟にすることができます。 |
注意の限定された焦点の性質は、Query-Key のドット積 (単一のスカラー値) の正規化された指数関数である SoftMax 関数の適用によって取得されます。
{id=”eq_attn” title=”注意”} \(\rm{注意}(Q, K) = \rm{ソフトマックス} \left( \frac{Q K^T}{\sqrt{d_k}} \right)\)
{id=”eq_softmax” title=”ソフトマックス”} \(\rm{softmax}(\bf{X}) = \left[ \frac{e^{x_i}}{\sum_j e^{x_j}}, ... \right]_i\)
各 Key の正規化されたスカラー アテンション値 (各クエリからの寄与の合計として計算され、[[#figure_transformer-attn]] の下向きの矢印で表されます) は、そのトークンの Value ベクトルを乗算し、線形重みによって再び変換され、この変換されたアテンションで変調された値が、アテンション メカニズムの出力結果になります (図の入力から出力に流れる大きな矢印で示されています)。
直感的には、この注意メカニズムにより、各入力単語がそれに最も関連性の高い他の単語を選択できるようになります。そのため、図の例では、入力単語「オレンジ」が「猫」を修飾するため、猫に強い注意の重みが与えられます。
指数関数的な SoftMax 正規化により、注意メカニズムは通常、他の比較的少数の単語に焦点を当てます。そのため、複数の注意焦点を同じフィードフォワード スイープで処理できるようにするために、そのような複数の注意ヘッドが並行して使用されます。モデルは標準の [[error backpropagation]] を使用してトレーニングされるため、クレジット割り当てプロセスでは、関連するすべてのものを同時に並行して存在させることが重要です。そうでないと、[[temporal credit assignment]] を達成するために、より複雑な時間プロセスによるバックプロパゲーションが必要になります。
フィードフォワード ネットワーク: 高次元パターン分離器
上で述べたように、実際には、トランス ([[@HuangYangPotts24]]) の記憶能力の大部分を占めるのは単なる標準的なフィードフォワード逆伝播ネットワークである FFN コンポーネントであり、セルフ アテンション メカニズムと同様にトランスの機能にとって重要です。これにより、これらのモードランセルは、このような膨大な量の情報を消化し、数十億の単語を含むデータベースに対して、あらゆる種類の予測を確率以上のレベルで生成できるようになります。
この記憶能力をサポートする FFN の重要な特徴は、隠れ層のサイズです。これはトークン入力ベクトルのサイズの 4 倍であり、典型的な GPT LLM モデル ([[@Aizi23]]) の LLM 学習可能なパラメーターの合計の約 70% を占めます。 FFN は、注意を払って重み付けされたトークン表現をこの大きな隠れ層に投影し、アクティビティ パターンを互いに比較的分離できるようにします (つまり、パターン分離)。これは、サポート ベクター マシン (SVM; [[@CortesVapnik95]])、および脳の [[hippocampus]] および [[cerebellum]] で使用されるのと同じ計算トリックです。
| このパターン分離関数を実行した後、表現は入力と同じ次元に圧縮されます。これはオートエンコーダーとして (つまり、入力と同じ表現を使用する) としてではなく、大きな隠れ層によって発見された [[combinatorial vs conjunctive | conjunctive]] 特徴に基づいて構築できる新しい変換を作成します。次に説明するように、ネットワーク全体で同じ次元を維持することは、ResNet プロパティにとって重要です。 |
ResNet 残差ストリーム
トランスフォーマーの ResNet プロパティは、情報がネットワーク ([[@ElhageNandaOlssonEtAl21]]) を通過するときにアテンション ヘッドが分割して操作できるバスのような経路を本質的に提供するために重要です。具体的には、ネットワークの各レベルはその出力をネットワーク全体の最終出力ステージに直接渡し、追加のレベルはその情報をこの「残りのストリーム」の情報に追加するだけです。
各上位層はその直下のレベルからのみ情報を取得するため、その層によって実行される処理のコンテキストが決まります。しかし、下位レベルの情報を直接出力に直接渡す機能は、誤差逆伝播を効果的に機能させるためだけでなく (そうしないと、上位層をすべてフィルタリングするまでに誤差勾配が大幅に薄まってしまいます)、上位層が入力から抽出された変換された情報の蓄積フローの「動的エディター」として機能できるようにするためにも不可欠です。
したがって、これらの上位層は、下位層によって抽出されたすべての情報_内容_を複製する必要はなく、代わりに、さまざまな抽象化レベルで入力に存在する関係をキャプチャする、より多くの_構造_情報を注入できます。これは、[[generalization]] ([[@YangCampbellHuangEtAl25]]; [[@WebbFranklandAltabaaEtAl24]]; [[@OReillyRanganathRussin22]]) で説明されているような体系的で生成的な動作に不可欠です。
認知神経科学への影響
反対のいくつかの否定的な主張にもかかわらず、トランスフォーマーは、たとえかなり顕著な記憶能力を示す傾向があるとしても、訓練された膨大なコーパスの純粋な暗記によってその驚くべき能力を獲得するわけではありません。その代わり、認知レベルでは、彼らの成功の背後にある「秘密のソース」は、この膨大な意味論的能力と [[episodic memory]] 能力を、抽象的で構造に敏感な [[generalization]] 能力と統合する能力です。
構造ベースの体系性と最適化された表現
認知レベルでは、この複数の頭の注意は、人間がテキストを読む際の並列的な [[constraint satisfaction]] と逐次的な逐次的な注意 ([[@McClellandHillRudolphEtAl20]]) の両方から生じるダイナミクスの一部を捉えている可能性があります。たとえば、より大きな複合表現を形成する相互に互換性のある単語がある場合 (たとえば、「ケーキの一部」)、注意メカニズムは相互興奮を生み出し、それらの単語を 1 つの単位として集中させ、単語がそのように処理されるのを助けます。既存の言語理論 ([[@TenneyDasPavlick19]]; [[@ManningClarkHewittEtAl20]]; [[@WarstadtBowman22]]; [[@ChenShwartz-ZivChoEtAl25]]; [[@McGrathRussinPavlickEtAl24]]) に示されているように、この種のメカニズムが複数の抽象レベルにわたって LLMS で動作していることについては十分な証拠があります。
[[language]] の理解に関与する一連のプロセスに関する広範な文献があります。このプロセスは、文中の単語を読み進め、蓄積された_文脈_を使用して後続の単語を解釈するときに、自然に強い注意に似た効果を生み出します。 garden path 文のように、後続の単語がこれらの期待と一致しない場合、多くの場合、積極的な再解釈が必要になります ([[@FerreiraHenderson91]]; [[@Fujita21]])。トランスフォーマーにはアクティブな作業メモリのメンテナンスがありませんが、コンテキスト入力サイズはますます大きくなり、後続の処理のコンテキスト化に使用できる「インコンテキスト」アクティブ メモリ システムを効果的に提供します ([[@OlssonElhageNandaEtAl22]])。
全体として、アテンション メカニズムは、標準のフィードフォワード ネットワークと比較して、トランスフォーマー内で [[optimized representations]] の形式をもたらします。このような種類の異なる処理ストリーム間の強い相互作用は、特定のレイヤー内では発生せず、レイヤー間の変換の蓄積によってのみ蓄積されます。さらに、この層ごとの相互作用の蓄積でさえ、多くの場合、ReLU 活性化関数の使用によって制限されます。ReLU 活性化関数は、ほぼ線形であるため、線形の相加効果をもたらす傾向があります。対照的に、SoftMax 正規化ダイナミクスにより、トランスフォーマーでの注意はより非線形になります。
完全な [[bidirectional connectivity]] と、その結果として生じる [[Axon]] の制約を満たすダイナミクスと比較すると、トランスフォーマーの注意メカニズムは、これらのダイナミクスを捉える正しい方向への強力な一歩であることは確かです。ただし、トランスフォーマーは基本的にフィードフォワード アーキテクチャのままであるため、実際には、より高いレベルの表現を直接フィードバックして、以前の層のアクティビティを変調することはできません。代わりに、これらの上位層は、残留ストリームの下位層の出力の動的編集を実行します。
さらに、非常に多くのフィードフォワード層が、双方向ネットワークで発生するであろうダイナミクスを効果的に展開する方法を学習することができます ([[bidirectional connectivity#feedforward unrolling]] を参照)。それにもかかわらず、この方法で新皮質ネットワーク全体を展開することは計算的に扱いにくいため、トランスフォーマーは新皮質で真の双方向接続が達成できることのより限定された側面しか捉えることができません。
スロットベースのバインディング
いくつかの分析により、変圧器が系統的に [[binding problem]] を解決できるメカニズムが明らかになりました ([[@FengSteinhardt24]]; [[@Gur-AriehGevaGeiger25]])。まず、情報は明示的に構造化されたスロットベースのアーキテクチャで表現され、各単語が独自の異なる表現を持つため、関連情報が存在する適切なスロットを効果的にポイントするだけで、抽象的な方法でバインディングを行うことができます。これは明らかにそのスロットの内容とは独立しています。これは実質的にシンボリック コンピュータで行われることです。シンボリック コンピュータでは、任意のパターンの情報を特定のメモリ アドレスに配置し、そのメモリ アドレスを完全に抽象的で体系的な変数として使用して、特定の役割を果たすコンテンツを表すことができます。
たとえば、次の簡単なステートメントを考えてみましょう。
アンはコーヒーを飲みます
サブジェクト ロール (Ann) は、あるメモリ位置にあるビットのパターンであれば何でも構いませんが、オブジェクト ロール (coffee) は別の場所にあることができ、適切なメモリ位置にパターンを配置する適切な方法 (たとえば、語順やその他の言語規則に基づく) がある限り、任意のコンテンツ (たとえば、Bazif は smalrog を飲みます) に自動的に一般化できます。
キュー値アテンション メカニズムにより、トランスフォーマは、特定のスロットに注意を集中させるためのキューとして、任意のアドレスのようなアクティビティ パターンを使用できるようになります。そのため、バインディング問題に対するこの解決策の使用を可能にするのは、スロット ベースのアーキテクチャとキュー値アテンション メカニズムの存在の両方の組み合わせです。
興味深いことに、[[basal ganglia]] (BG) および [[prefrontal cortex]] (PFC) の動的ワーキング メモリ ゲート メカニズムに基づいて、同様のソリューションが提案されました。この場合、BG は、任意のアクティビティ パターンを PFC アクティブ メンテナンス ([[@KrieteNoelleCohenEtAl13]]) の特定のストライプ (スロット) にゲートできます。これにより、同じ種類のアドレスのような機能バインディングが実現され、その PFC スロット内のすべてのものが、この場所にゲートされているという理由だけで特定の機能的役割を引き受けます。
この PFC-BG モデルの重要な課題は、さまざまなスロットにわたってニューロンをトレーニングして、そのスロットに入れられる可能性のある関連コンテンツを表現する必要があることです。トランスフォーマーは、すべての物理バインディング スロットにわたって同じ学習されたシナプスの重みを再利用するだけで、この困難な偉業を達成します。このような余裕のない脳内でこれが実際にどのように機能するのかは不明ですが、おそらく単語を適切に抽象化した音素エンコーディングを使用すれば、人々は特定の音素セットをいくつかの異なる PFC 位置の 1 つにルーティングする方法を学習できるでしょう。したがって、言語のコンパクトで普遍的な音韻コードは、任意の結合問題を解決する上で重要な要素となる可能性があります。
意味記憶とエピソード記憶
トランスフォーマーには、[[neocortex]] ([[semantic memory]] 用) と [[hippocampus]] (エピソード記憶用) の間の解剖学的および機能的な違いに対応するいかなる種類の構造的区別もありませんが、フィードフォワード ネットワークの高次元の性質により、これらのモデルは、特定のテキストの高度に特殊な記憶と、より一般化された意味知識 ([[@NandaRajamanoharanKramarEtAl23]]) の両方をエンコードできます。 [[combinatorial vs conjunctive]] 表現で説明したように、これらの異なるタイプの表現の間にはトレードオフがあり、バックプロパゲーション メカニズムは、トランスフォーマーが通常使用される [[predictive learning]] タスクの必要に応じて、これらの異なるタイプの表現の有用な組み合わせを学習できます。
標準的な変換器に決定的に欠けているのは、最初のトレーニングセットを超えて「新しい」エピソードのような記憶を形成する能力です。そのため、トレーニングテキストの驚くべき真実の想起を示すことはできますが、人間のように、経験したその後の出来事を詳細に思い出すことはできません。多くの研究者が、LLM にこの能力を追加する方法に取り組んでおり、エピソード記憶のエンコードと取得に対する追加の制御レベルは、研究すべき興味深い問題です (例: [[@ZhengWolfRanganathEtAl25]])。
要約すると、トランスフォーマーは、基盤となる異なるニューラル ハードウェアを使用するだけで、人間の脳の [[cognitive architecture]] の本質的な特性をキャプチャしていると見なすことができます。したがって、これらのモデルの成功は、この認知アーキテクチャの人工バージョンが人間の認知の最も重要な側面の多くを実際に再現できること、そしてこれらすべてが実際にどのように機能するかをより深く理解することによって、[[Axon]] モデルについて学ぶべきことがたくさんあることを具体的に実証しています。